如何快速成就JAVA架构师,深度理解性能优化,亿级高并发,微服务架构体系
写blog和写代码一样,刚开始都是不完美的,需要不断的修正和重构,如果大家在阅读本blog中发现任何问题和疑问,都欢迎讨论或拍砖。
1 性能调优简介
1.1为什么要进行性能调优?
1.1.1 编写的新应用上线前在性能上无法满足需求,这个时候需要对系统进行性能调优
1.1.2 应用系统在线上运行后随着系统数据量的不断增长、访问量的不断上升,系统的响应速度通常越来越慢,不满足业务需要,这个时候也需要对系统进行性能调优
1.2 性能调优包括那些方面?
1.2.1 谈到系统或产品的性能调优,可以从广义和狭义两个范围来理解。
从广义的层面来看,就不仅限于程序内部了,因为造成系统性能问题的瓶颈很可能来源于方方面面,而这种情况往往是性能调优很普遍的情况,
下面就从广义的范围细分成几个角度来进行阐述,见图-1 广义性能调优鱼骨图
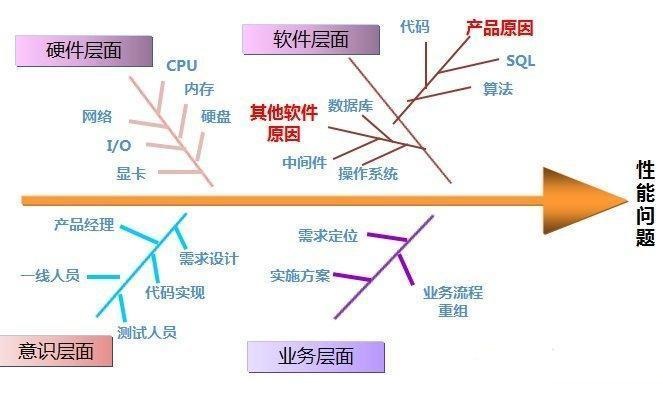
图-1 广义性能调优鱼骨图
1.2.2从狭义的范畴来看,性能调优主要是指通过修改软件程序逻辑、结构等技术手段提升软件产品的各项性能指标,如响应时间等。本文重要是从狭义的范畴来看。
从狭义的范畴看,性能调优可以从 硬件(计算机体系机构)、操作系统(OS\JVM)、文件系统、网络通信、数据库系统、中间件、应用程序本身等方面入手。
这里主要关注JVM、中间件、应用程序的性能调优。
1.3 性能的参考指标
执行时间:一段代码从开始运行到运行结束所使用的时间。
CPU时间:(算法)函数或者线程占用CPU的时间。
内存分配:程序在运行时占用的内存空间。
磁盘吞吐量:描述I/O的使用情况。
网络吞吐量:描述网络的使用情况。
响应时间:系统对某用户行为或者动作做出响应的时间。响应时间越短,性能好。
2 性能调优步骤
2.1性能调优步骤图
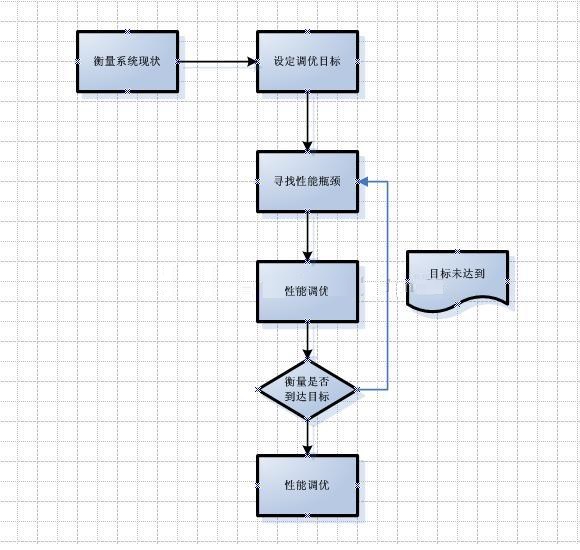
图-2性能调优步骤图
调优前首先要做的是衡量系统现状,这包括目前系统的请求次数、响应时间、资源消耗等信息,例如B系统目前95%的请求响应时间为1秒。
在有了系统现状后可设定调优目标,通常调优目标是根据用户所能接受的响应速度或系统所拥有的机器以及所支撑的用户量估算出来的,例如 设定调优目标:95%的请求要在500ms内返回。
在设定了调优目标后,需要做的是寻找性能瓶颈,这一步最重要的是找出造成目前系统性能不足的最大瓶颈点。找出后,可结合一些工具来找出造成瓶颈点的代码,到此才完成了这个步骤。
在找到了造成瓶颈点的代码后,开始进行性能调优。通常需要分析其需求或业务场景,然后结合一些优化的技巧确定优化的策略,优化策略或简或繁,选择其中收益比(优化后的预期效果/优化需要付出的代价)最高的优化方案,进行优化。
优化部署后,继续衡量系统的状况,如已达到目标,则可结束此次调优,如仍未达到目标,则要看是否产生了新的性能瓶颈。或可以考虑继续尝试上一步中制定的其他优化方案,直到达成调优目标或论证在目前的体系结构上无法达到调优目标为止。
3 性能调优思路
性能调优的步骤主要有:衡量系统现状、设定调优目标、寻找性能瓶颈、性能调优,验证是否达到调优目标。
本文档主要关注调优步骤中的 寻找性能瓶颈 和 性能调整(优) 两个关键的阶段阶段,主要思路见下图:图-3 寻找性能瓶颈和性能调优项结构分解图
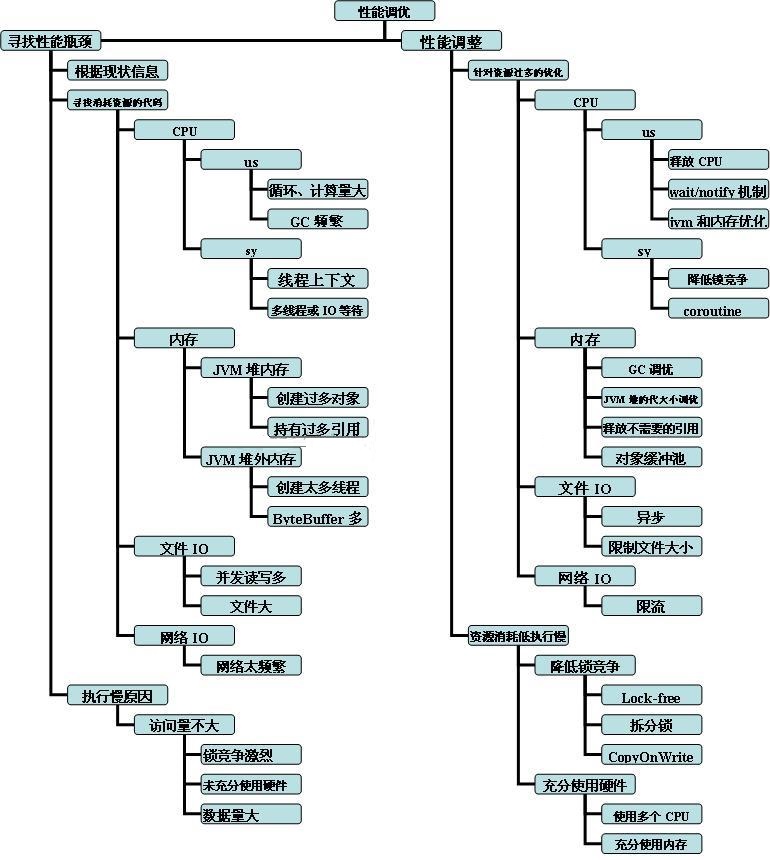
图-3 寻找性能瓶颈和性能调优项结构分解图
4 寻找性能瓶颈
寻找性能瓶颈分个两部分:寻找过度消耗资源的代码 和 寻找未充分使用资源但程序执行慢的原因和代码。
通常性能瓶颈的表象是资源消耗过多外部处理系统的性能不足;或者资源消耗不多但程序的响应速度却仍达不到要求。
这里资源主要是指:消耗在CPU、内存、文件IO、网络IO等方面资源。机器的资源是有限的,当某资源消耗过多时,通常会造成系统的响应速度慢。
外部处理系统的性能不足主要是指所调用的其他系统提供的功能(如数据库操作的响应速度不够);所调用的其他系统性能不足多数情况下也是资源消耗过多,但程序的性能不足造成的; 数据库操作性能不足通常可以根据数据库的sql执行速度、数据库机器的IOPS、数据库的Active Sessions等分析出来。
寻找未充分使用资源但程序执行慢的原因和代码:资源消耗不多、但程序的响应速度仍然达不到要求的主要原因是程序代码运行效率不够高、未充分使用资源或程序结构不合理。
对于Java应用而言,寻找性能瓶颈的方法通常为首先分析资源的消耗,然后结合OS和Java等一些分析工具来查找程序中造成资源消耗过多的代码。
4.1CPU消耗分析
在Linux中,CPU主要用于 中断、内核进程以及用户进程的任务处理,优先级为:中断 > 内核进程 > 用户进程,在学习如何分析CPU消耗状况前,有三个重要概念交代一下。
4.1.1 上下文切换、运行队列、利用率
4.1.1.1上下文切换
每个CPU(或多核CPU中的每核CPU)在同一时间只能执行一个线程。 Linux采用的是抢占式调度:即为每个线程分配一定的执行时间,当到达执行时间、线程中有IO阻塞或高优先级线程要执行时,Linux将切换执行的线程,在切换时要存储目前程序的执行状态PCB(Program Control Block),并恢复要执行的线程的状态,这个过程就称为上下文切换。
对于Java应用,典型的是在进行文件IO操作、网络IO操作、锁等待或线程Sleep时,当前线程会进入阻塞或休眠状态,从而触发上下文切换,上下文切换过多会造成内核占据较多的CPU使用,使得应用的响应速度下降。
4.1.1.2运行队列
每个CPU核都维护了一个可运行的线程队列,例如一个4核的CPU, Java应用中启动了8个线程,且这8个线程都处于可运行状态,那么在分配平均的情况下每个CPU中的运行队列里就会有两个线程。通常而言,系统的load主要由CPU的运行队列来决定,假设以上状况维持了1分钟,那么这1分钟内系统的load就会是2,但由于load是个复杂的值,因此也不是绝对的,运行队列值越大,就意味着线程要消耗越长的时间才能执行完。 Linux System and NewWork Performance Monitoring中建议控制在每个CPU核上的运行队列为1-3个。
4.1.1.3利用率
CPU利用率为CPU在用户进程、内核进程、中断处理、IO等待以及空闲五个部分使用的百分比,这五个值是用来分析CPU消耗情况的关键指标。 Linux System and NewWork Performance Monitoring 中建议用户进程的CPU消耗/内核的CPU消耗的比例在 65%-70% / 30%-35%
4.1.2Linux观测CPU消耗状态的工具:perf、top、vmstat、pidstat、sar、pcpu、ps Hh -eo tid
4.1.2.0 工具 perf 性能测试工具
sudo apt-get install linux-tools-common
sudo apt-get install linux-tools-3.13.0-27-generic
4.1.2.1工具top
用工具SSH登陆到Linux 上后,在字符界面下输入top命令后即可查看CPU的消耗情况,CPU的信息在TOP视图的上面几行中
图-4 Top查看CPU使用情况图:第四行被矩形围起来的部分:其中 0.2% us 表示用户进程处理所占的百分比;0.7% sy 表示为内核线程处理所占的百分比; 0.0% ni 表示被nice命令改变优先级的任务所占的百分比;99.0% id 表示CPU的idle空闲时间所占的百分比; 0.0% wa 表示在执行的过程中等待IO所占的百分比; 0.2% hi 表示硬件中断所占的百分比; 0.0% si 表示软件中断所占的百分比。
相信只要是个稍微像样点的互联网公司,或多或少都有自己的一套缓存体
只要用缓存,就可能会涉及到缓存与数据库双存储双写,你只要是双写,就一定会有数据一致性的问题,遂笔者想在这想和大家聊一聊:如何解决一致性问题?
如何保证缓存与数据库双写一致性,也是现在Java面试中面试官非常喜欢问的一个问题!
一般来说,如果允许缓存可以稍微跟数据库偶尔有不一致,也就是说如果你的系统不是严格要求 缓存 + 数据库 必须保持一致性的话,最好不要做这个方案。
即:读请求和写请求串行化,串到一个内存队列里去,从而达到防止并发请求导致数据错乱的问题,场景如图所示:

值得注意的是,串行化可以保证一定不会出现不一致的情况,但是它也会导致系统的吞吐量大幅度降低,用比正常情况下多几倍的机器去支撑线上的一个请求(土豪请自觉无视此提醒)
解决思路如下图:

代码实现大致如下:
/**
* 请求异步处理的service实现
* @author Administrator
*
*/
@Service("requestAsyncProcessService")
public class RequestAsyncProcessServiceImpl implements RequestAsyncProcessService { @Override public void process(Request request) { try { // 先做读请求的去重 RequestQueue requestQueue = RequestQueue.getInstance(); Map<Integer, Boolean> flagMap = requestQueue.getFlagMap(); if(request instanceof ProductInventoryDBUpdateRequest) { // 如果是一个更新数据库的请求,那么就将那个productId对应的标识设置为true flagMap.put(request.getProductId(), true); } else if(request instanceof ProductInventoryCacheRefreshRequest) { Boolean flag = flagMap.get(request.getProductId()); // 如果flag是null if(flag == null) { flagMap.put(request.getProductId(), false); } // 如果是缓存刷新的请求,那么就判断,如果标识不为空,而且是true,就说明之前有一个这个商品的数据库更新请求 if(flag != null && flag) { flagMap.put(request.getProductId(), false); } // 如果是缓存刷新的请求,而且发现标识不为空,但是标识是false // 说明前面已经有一个数据库更新请求+一个缓存刷新请求了,大家想一想 if(flag != null && !flag) { // 对于这种读请求,直接就过滤掉,不要放到后面的内存队列里面去了 return; } } // 做请求的路由,根据每个请求的商品id,路由到对应的内存队列中去 ArrayBlockingQueue<Request> queue = getRoutingQueue(request.getProductId()); // 将请求放入对应的队列中,完成路由操作 queue.put(request); } catch (Exception e) { e.printStackTrace(); } } /** * 获取路由到的内存队列 * @param productId 商品id * @return 内存队列 */ private ArrayBlockingQueue<Request> getRoutingQueue(Integer productId) { RequestQueue requestQueue = RequestQueue.getInstance(); // 先获取productId的hash值 String key = String.valueOf(productId); int h; int hash = (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); // 对hash值取模,将hash值路由到指定的内存队列中,比如内存队列大小8 // 用内存队列的数量对hash值取模之后,结果一定是在0~7之间 // 所以任何一个商品id都会被固定路由到同样的一个内存队列中去的 int index = (requestQueue.queueSize() - 1) & hash; System.out.println("===========日志===========: 路由内存队列,商品id=" + productId + ", 队列索引=" + index); return requestQueue.getQueue(index); } }
Cache Aside Pattern
下面我们来聊聊最经典的缓存+数据库读写的模式,就是 Cache Aside Pattern。
读的时候,先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存,同时返回响应。更新的时候,先更新数据库,然后再删除缓存。
为什么是删除缓存,而不是更新缓存?
原因很简单,很多时候,在复杂点的缓存场景,缓存不单单是数据库中直接取出来的值。
比如可能更新了某个表的一个字段,然后其对应的缓存,是需要查询另外两个表的数据并进行运算,才能计算出缓存最新的值的。
另外更新缓存的代价有时候是很高的,是不是每次修改数据库的时候,都一定要将其对应的缓存更新一份?
也许有的场景是这样,但是对于比较复杂的缓存数据计算的场景,就不是这样了。
如果你频繁修改一个缓存涉及的多个表,缓存也频繁更新。但是问题在于,这个缓存到底会不会被频繁访问到?
举个栗子,一个缓存涉及的表的字段,在 1 分钟内就修改了 20 次,或者是 100 次,那么缓存更新 20 次、100 次;
但是这个缓存在 1 分钟内只被读取了 1 次,有大量的冷数据。
实际上,如果你只是删除缓存的话,那么在 1 分钟内,这个缓存不过就重新计算一次而已,开销大幅度降低,用到缓存才去算缓存。
其实删除缓存,而不是更新缓存,就是一个 lazy 计算的思想,不要每次都重新做复杂的计算,不管它会不会用到,而是让它到需要被使用的时候再重新计算。
像 mybatis,hibernate,都有懒加载思想,查询一个部门,部门带了一个员工的 list,没有必要说每次查询部门,都把里面的 1000 个员工的数据也同时查出来。
80% 的情况,查这个部门,就只是要访问这个部门的信息就可以了,先查部门,同时要访问里面的员工,那么这时只有在你要访问里面的员工的时候,才会去数据库里面查询 1000 个员工。
最初级的缓存不一致问题及解决方案
问题:先修改数据库,再删除缓存。如果删除缓存失败了,那么会导致数据库中是新数据,缓存中是旧数据,数据就出现了不一致。
解决思路:先删除缓存,再修改数据库。如果数据库修改失败了,那么数据库中是旧数据,缓存中是空的,那么数据不会不一致。
因为读的时候缓存没有,则读数据库中旧数据,然后更新到缓存中。
比较复杂的数据不一致问题分析
数据发生了变更,先删除了缓存,然后要去修改数据库。
但是还没来得及修改,一个请求过来,去读缓存,发现缓存空了,去查询数据库,查到了修改前的旧数据,放到了缓存中。
随后数据变更的程序完成了数据库的修改。
完了,数据库和缓存中的数据不一样了。。。
为什么上亿流量高并发场景下,缓存会出现这个问题?
只有在对一个数据在并发的进行读写的时候,才可能会出现这种问题。
如果说你的并发量很低的话,特别是读并发很低,每天访问量就 1 万次,那么很少的情况下,会出现刚才描述的那种不一致的场景。
但是问题是,如果每天的是上亿的流量,每秒并发读是几万,每秒只要有数据更新的请求,就可能会出现上述的数据库+缓存不一致的情况。
解决方案如下:
更新数据的时候,根据数据的唯一标识,将操作路由之后,发送到一个 jvm 内部队列中。
读取数据的时候,如果发现数据不在缓存中,那么将重新读取数据+更新缓存的操作,根据唯一标识路由之后,也发送同一个 jvm 内部队列中。
一个队列对应一个工作线程,每个工作线程串行拿到对应的操作,然后一条一条的执行。
这样的话,一个数据变更的操作,先删除缓存,然后再去更新数据库,但是还没完成更新。
此时如果一个读请求过来,读到了空的缓存,那么可以先将缓存更新的请求发送到队列中,此时会在队列中积压,然后同步等待缓存更新完成。
这里有一个优化点,一个队列中,其实多个更新缓存请求串在一起是没意义的,因此可以做过滤
如果发现队列中已经有一个更新缓存的请求了,那么就不用再放个更新请求操作进去了,直接等待前面的更新操作请求完成即可。
待那个队列对应的工作线程完成了上一个操作的数据库的修改之后,才会去执行下一个操作,也就是缓存更新的操作,此时会从数据库中读取最新的值,然后写入缓存中。
如果请求还在等待时间范围内,不断轮询发现可以取到值了,那么就直接返回;如果请求等待的时间超过一定时长,那么这一次直接从数据库中读取当前的旧值。
高并发的场景下,该解决方案要注意的问题:
1、读请求长时阻塞
由于读请求进行了非常轻度的异步化,所以一定要注意读超时的问题,每个读请求必须在超时时间范围内返回。
该解决方案,最大的风险点在于,可能数据更新很频繁,导致队列中积压了大量更新操作在里面,然后读请求会发生大量的超时,最后导致大量的请求直接走数据库。
所以务必通过一些模拟真实的测试,看看更新数据的频率是怎样的。
另外一点,因为一个队列中,可能会积压针对多个数据项的更新操作,因此需要根据自己的业务情况进行测试,可能需要部署多个服务,每个服务分摊一些数据的更新操作。
如果一个内存队列里积压 100 个商品的库存修改操作,每个库存修改操作要耗费 10ms 去完成,那么最后一个商品的读请求,可能等待 10 * 100 = 1000ms = 1s 后,才能得到数据,这个时候就导致读请求的长时阻塞。
因此,一定要根据实际业务系统的运行情况,去进行一些压力测试和模拟线上环境,去看看最繁忙的时候,内存队列可能会积压多少更新操作,可能会导致最后一个更新操作对应的读请求,会 hang 多少时间。
如果读请求在 200ms 返回,如果你计算过后,哪怕是最繁忙的时候,积压 10 个更新操作,最多等待 200ms,那还可以的。
如果一个内存队列中可能积压的更新操作特别多,那么你就要加机器,让每个机器上部署的服务实例处理更少的数据,那么每个内存队列中积压的更新操作就会越少。
其实根据之前的项目经验,一般来说,数据的写频率是很低的,因此实际上正常来说,在队列中积压的更新操作应该是很少的。
像这种针对读高并发、读缓存架构的项目,一般来说写请求是非常少的,每秒的 QPS 能到几百就不错了。
实际粗略测算一下,如果一秒有 500 的写操作,分成 5 个时间片,每 200ms 就 100 个写操作,放到 20 个内存队列中,每个内存队列,可能就积压 5 个写操作。
每个写操作性能测试后,一般是在 20ms 左右就完成,那么针对每个内存队列的数据的读请求,也就最多 hang 一会儿,200ms 以内肯定能返回了。
经过刚才简单的测算,我们知道,单机支撑的写 QPS 在几百是没问题的,如果写 QPS 扩大了 10 倍,那么就扩容机器,扩容 10 倍的机器,每个机器 20 个队列。
2、读请求并发量过高
这里还必须做好压力测试,确保恰巧碰上上述情况时,还有一个风险,就是突然间大量读请求会在几十毫秒的延时 hang 在服务上,看服务能不能扛的住,需要多少机器才能扛住最大的极限情况的峰值。
但是因为并不是所有的数据都在同一时间更新,缓存也不会同一时间失效,所以每次可能也就是少数数据的缓存失效了,然后那些数据对应的读请求过来,并发量应该也不会特别大。
3、多服务实例部署的请求路由
可能这个服务部署了多个实例,那么必须保证说,执行数据更新操作,以及执行缓存更新操作的请求,都通过 Nginx 服务器路由到相同的服务实例上。
比如对同一个商品的读写请求,全部路由到同一台机器上。可以自己去做服务间的按照某个请求参数的 hash 路由,也可以用 Nginx 的 hash 路由功能等等。
4、热点商品的路由问题,导致请求的倾斜
万一某个商品的读写请求特别高,全部打到相同的机器的相同的队列里面去了,可能会造成某台机器的压力过大。
因为只有在商品数据更新的时候才会清空缓存,然后才会导致读写并发,所以要根据业务系统去看,如果更新频率不是太高的话,这个问题的影响并不是特别大,但是可能某些机器的负载会高一些。