Hadoop 2.x 源码编译
◆ 编译 Hadoop 环境要求:
1、必须在 Linux 系统下进行编译;
2、编译使用的 JDK 版本必须是 1.6 以上;
3、编译需要使用 Maven(因为源码是由 Maven 管理的)版本 3.0 以上;
4、安装 Findbugs 插件工具,版本 1.3.9
5、安装 CMake 编译工具,版本 2.6 或最新版本
6、安装 zlib devel
7、安装 openssl devel
8、编译时必须连接互联网
〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓编译开始〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓
◆ 第一步,解压 Hadoop 安装包,版本:2.5.0
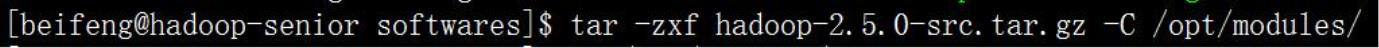
◆ 第二步,解压 JDK,版本:1.7
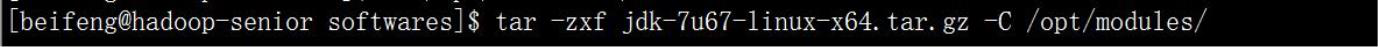
◆ 第三步,配置环境变量,并使 profile 文件生效(在 root 用户下操作)



◆ 第四步,配置 Maven,并使 profile 文件生效(在 root 用户下操作)





◆ 第五步,安装 gcc/gcc-c++/make(在 root 用户下操作)

◆ 第六步,解压安装 protobuf(切回普通用户)
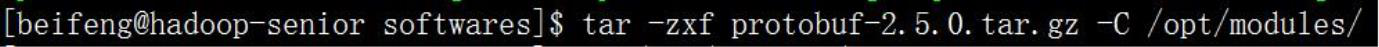

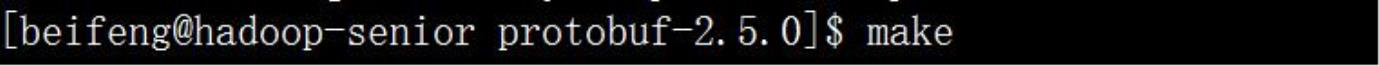

◆ 第七步,配置环境变量
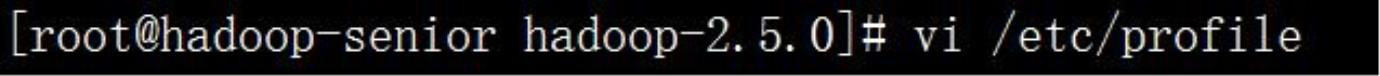

◆ 在普通用户下 source 生效 profile 文件,并查看安装是否成功

◆ 第八步,下载安装 CMake、openssl、ncurses 依赖包
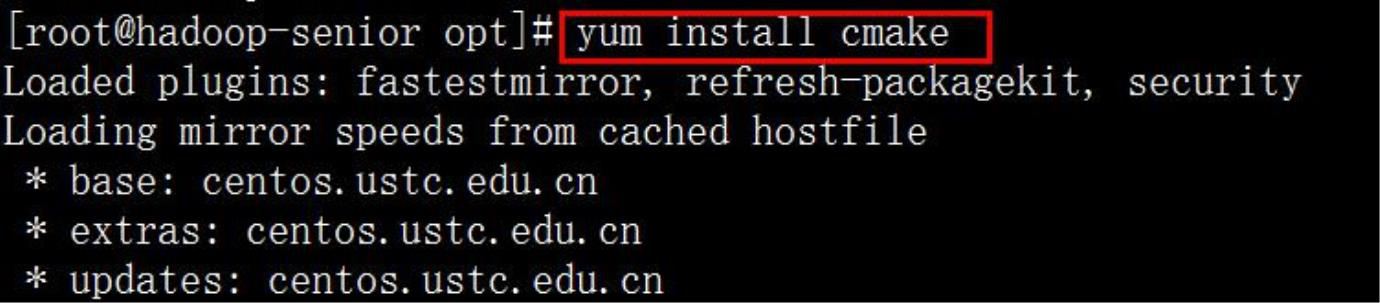


◆ 第九步,开始编译 Hadoop 源码包,先移动到 hadoop 源码包安装目录下

由于后面要使用snappy压缩,所以编译方式修改如下:
http://pkgs.fedoraproject.org/repo/pkgs/snappy/snappy-1.1.1.tar.gz/8887e3b7253b22a31f5486bca3cbc1c2/snappy-1.1.1.tar.gz
tar zxvf snappy-1.1.1.tar.gz && cd snappy-1.1.1 && ./configure && make && make install
查看snappy安装情况:ls -lh /usr/local/lib |grep snappy
安装:
mvn package -Pdist,native -DskipTests -Drequire.snappy
◆ 编译成功!整个编译过程大约需要等待 20~30 分钟,如下图:

◆ 替换原来的 Native 目录,执行命令查看,不再提示警告

〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓编译完成!〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓〓