龙芯 vs 飞腾:各种测试数据看国产CPU水平
https://zhuanlan.zhihu.com/p/99921594 跟实际使用感受差不多 我也感觉龙芯只有飞腾一半的性能。 稳定性也不是很好。
2019年年末,龙芯、飞腾两大国产CPU巨头更是相继组织了规模宏大的年会,发布了新型桌面芯片及其整机产品,顿时硝烟四起。各大媒体也都很嗨,zyt、xhs、rmrb都对两个盛会做了报道,环球更是发表了第三方文章,把龙芯吹捧了一把,把其他家狠狠打压了一番。在芯片行业遭遇国际严峻形势的情况下,秀秀肌肉提振一下信心很有必要,笔者也很振奋于国产CPU的整体氛围已经起来了,中国芯片的发展大势已经不可抵挡。但我们仍应认清我们的差距,切不可盲目乐观,号称“补课”已经完成,不要被一些发明出来的metric晃晕了头脑,否则你吃得起小龙虾,你就买得起奥迪。
一周时间过去了,情绪的高潮也应该差不多了,是时候理性出场、数据说话了。这两款芯片性能到底如何?公布的性能水分有多大?笔者在两家产品的样机上进行了一番摸底测试。
整机配置:
1、龙芯整机:3A4000四核,1.8GHz,内存8G,SATA机械硬盘
2、飞腾整机:FT2000四核,2.6GHz,内存8G,SATA机械硬盘
下面放数据,事先声明,用的编译开关是通用的,不排除两家还各自有神操作,能够提升各自性能,也欢迎各自提供测试数据。
一、SPEC2006(分数越高越好)
龙芯vs 飞腾spec2006测试结果对比:
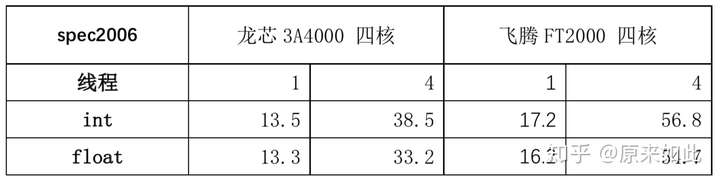
龙芯3A4000四核测试结果:
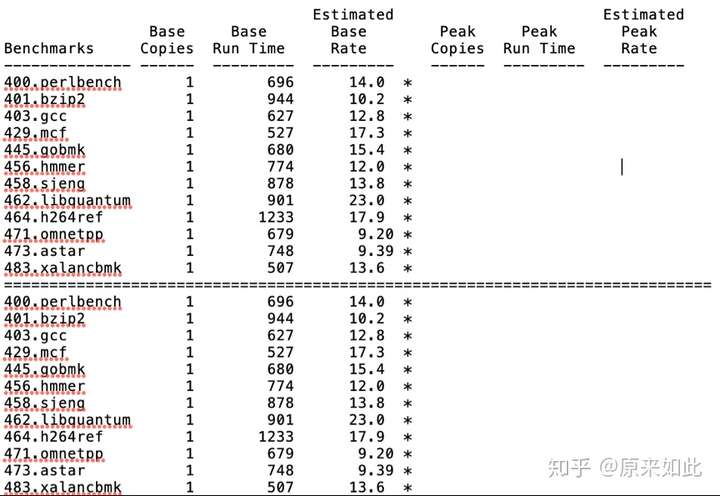
图:3A4000单核整型spec2006测试结果
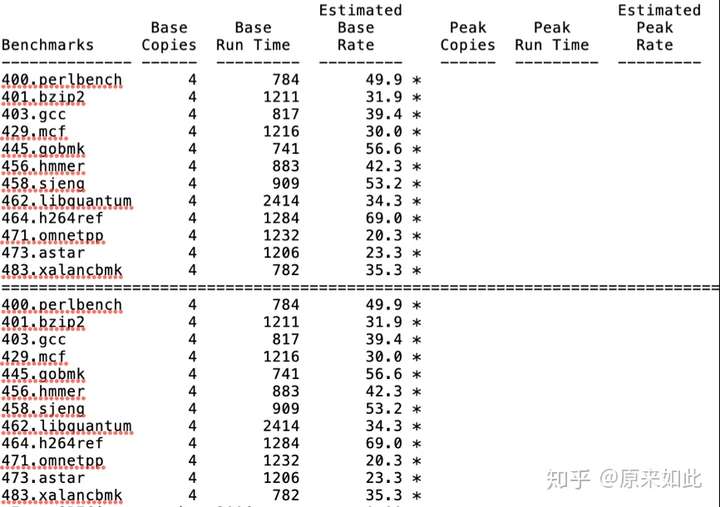
图:3A4000四核整型spec2006测试结果

图:3A4000单核浮点型spec2006测试结果
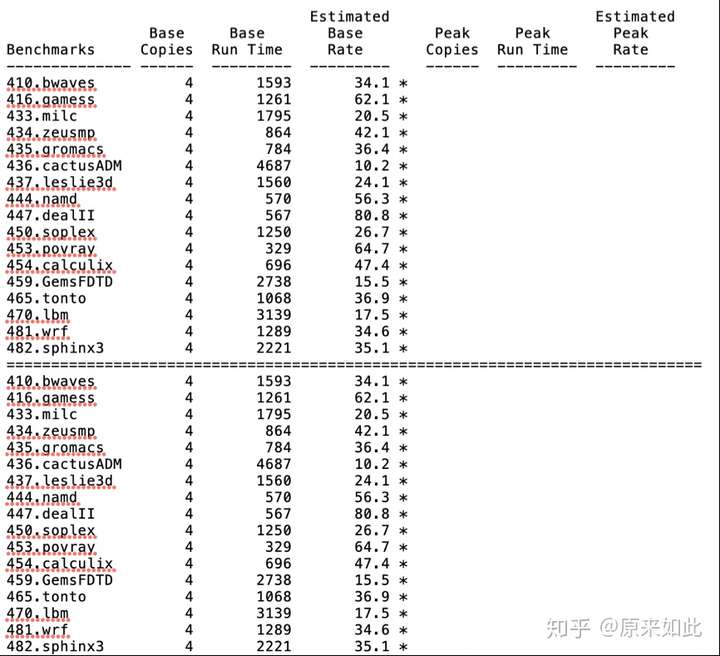
图:3A4000四核浮点型spec2006测试结果

飞腾FT2000四核测试结果:

图:飞腾2000单核整型spec2006测试结果
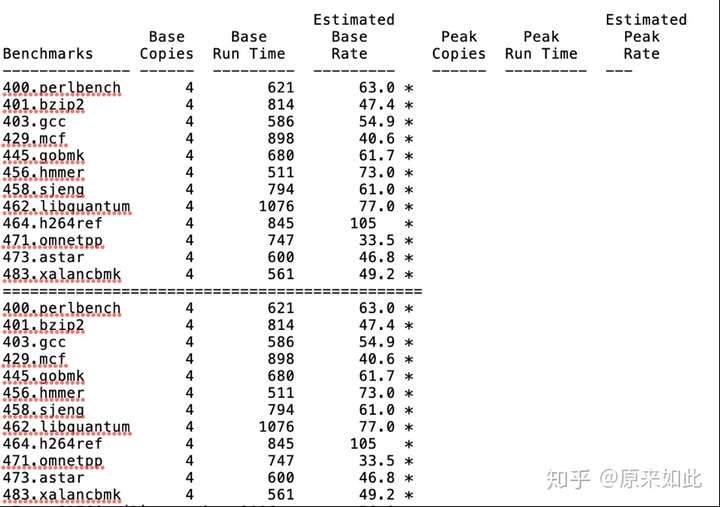
图:飞腾2000四核整型spec2006测试结果

图:飞腾2000单核浮点型spec2006测试结果
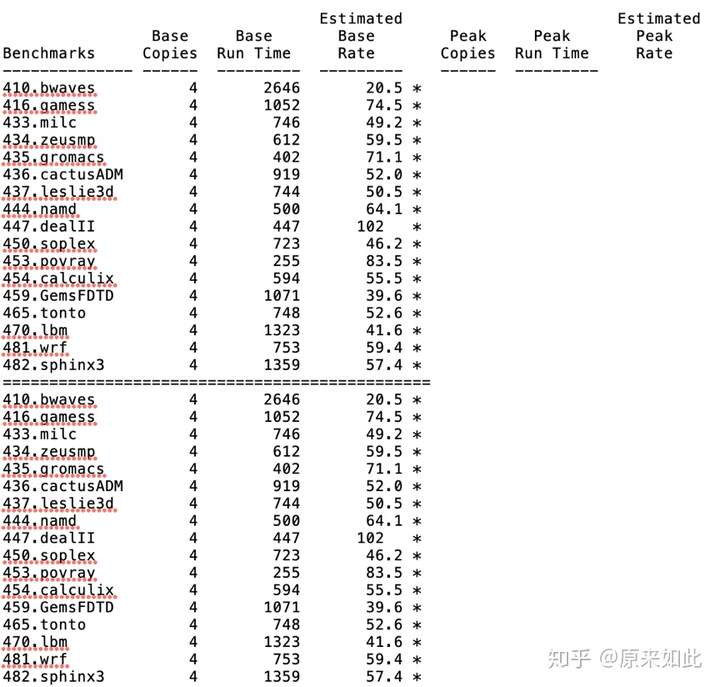
图:飞腾2000四核浮点型spec2006测试结果
二、LmBench访存延迟(延迟越低越好)
龙芯vs 飞腾LmBench测试结果对比:

龙芯测试结果:

飞腾测试结果:

三、系统综合性能Unixbench(分值越高越好)
龙芯vs 飞腾Unixbench测试结果对比:

龙芯测试结果
单核测试结果:

多核测试结果:
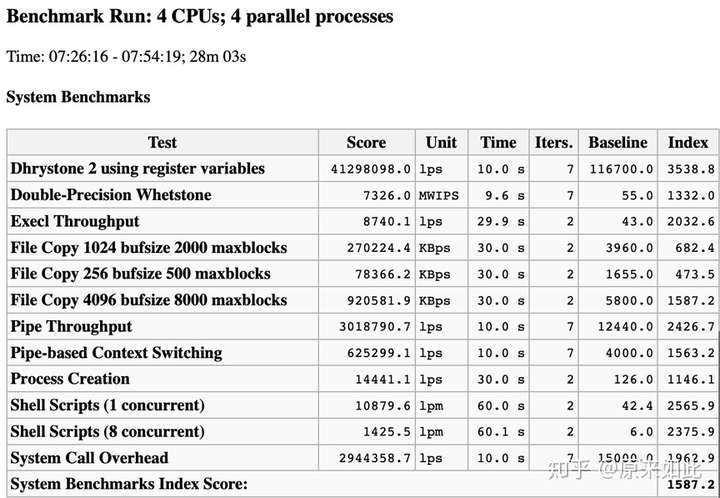
飞腾测试结果:
单核测试结果:

多核测试结果:

四、stream访存带宽(带宽越高越好)
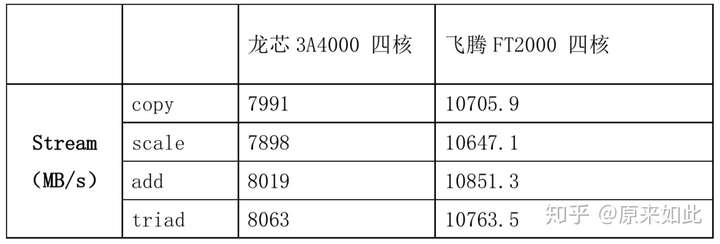
龙芯vs 飞腾stream测试结果对比:
龙芯测试方法及过程日志
-------------------------------------------------------------
STREAM version $Revision: 5.10 $
-------------------------------------------------------------
This system uses 8 bytes per array element.
-------------------------------------------------------------
Array size = 10000000 (elements), Offset = 0 (elements)
Memory per array = 76.3 MiB (= 0.1 GiB).
Total memory required = 228.9 MiB (= 0.2 GiB).
Each kernel will be executed 10 times.
The *best* time for each kernel (excluding the first iteration)
will be used to compute the reported bandwidth.
-------------------------------------------------------------
Number of Threads requested = 4
Number of Threads counted = 4
-------------------------------------------------------------
Your clock granularity/precision appears to be 1 microseconds.
Each test below will take on the order of 23420 microseconds.
(= 23420 clock ticks)
Increase the size of the arrays if this shows that
you are not getting at least 20 clock ticks per test.
-------------------------------------------------------------
WARNING -- The above is only a rough guideline.
For best results, please be sure you know the
precision of your system timer.
-------------------------------------------------------------
Function Best Rate MB/s Avg time Min time Max time
Copy: 7991.1 0.020137 0.020022 0.020330
Scale: 7898.5 0.020402 0.020257 0.020543
Add: 8019.5 0.030083 0.029927 0.030517
Triad: 8063.4 0.030026 0.029764 0.031464
飞腾测试方法及过程日志:
-------------------------------------------------------------
STREAM version $Revision: 5.10 $
-------------------------------------------------------------
This system uses 8 bytes per array element.
-------------------------------------------------------------
Array size = 178900000 (elements), Offset = 0 (elements)
Memory per array = 1364.9 MiB (= 1.3 GiB).
Total memory required = 4094.7 MiB (= 4.0 GiB).
Each kernel will be executed 10 times.
The *best* time for each kernel (excluding the first iteration)
will be used to compute the reported bandwidth.
-------------------------------------------------------------
Number of Threads requested = 4
Number of Threads counted = 4
-------------------------------------------------------------
Your clock granularity/precision appears to be 1 microseconds.
Each test below will take on the order of 328026 microseconds.
(= 328026 clock ticks)
Increase the size of the arrays if this shows that
you are not getting at least 20 clock ticks per test.
-------------------------------------------------------------
WARNING -- The above is only a rough guideline.
For best results, please be sure you know the
precision of your system timer.
-------------------------------------------------------------
Function Best Rate MB/s Avg time Min time Max time
Copy: 10705.9 0.270737 0.267367 0.274043
Scale: 10647.1 0.271205 0.268843 0.273011
Add: 10851.3 0.399085 0.395677 0.403818
Triad: 10763.5 0.402215 0.398904 0.406974
--------------------------------------------------------------
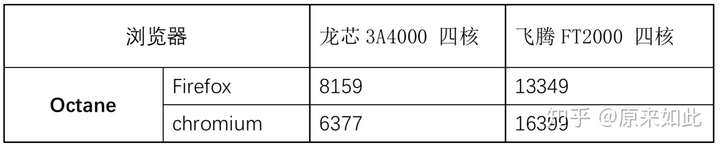
五、浏览器性能Octane(分数越高越好)
龙芯vs 飞腾Octane测试结果对比:
六、SpecJVM2008(分数越高越好)
龙芯vs 飞腾SpecJVM2008测试结果对比:

七、小结
单以spec2006测试来看,飞腾和龙芯的单核性能并未像宣传的那样都达到20分水平,可能是因为他们自己内部测试有更高主频、更好配置,进行了某些他们自己特有的优化,希望他们能够公布出来,让我们好好学习。另外,龙芯未公布全芯片的性能,强调单核提升较多,但芯片设计是个系统工程,不止是单核能力,还涉及到互连、存储、IO等设计,实测的全芯片性能和单核性能综合起来才能代表芯片设计水平。飞腾单核到多核的扩展性尚可,但单核性能也不出彩,即便扩展到3.0GHz,在这个配置下也难以达到20分,更何况核的频率提升带来的性能提升并非线性的,除非外围存储和互连也同步提升。现在市面上的intel、AMD的桌面CPU的spec2006单核性能基本都在30分以上,最高的可以到70、80分。因此,国产CPU相比国际主流来讲还有不小差距,难说达到完成了“补课”的状态,还有很长的路要走。
根据龙芯总裁胡伟武研究员2019年12月24日发布的演讲来看,龙芯3A4000四核在DDR4和功耗方面确实存在一些问题,导致性能与上一代比较提升不明显,希望3A5000能够有所改善。从龙芯在推出3A4000不到半年就要推出3A5000计划来看,确实是非常急迫地想要进行改进,3A4000是一个比较尴尬的中间产品。但龙芯有个亮点,这个DDR4接口是自研的,虽然只是28nm,频率也不高,好歹解决了有无问题。如果不涉及知识产权问题,这个IP可以外售赚钱了。不过没有PCIE是个缺憾,现在还用AMD的HT接口实在是太老的。

总之,还是那句话,国产的大幕已经拉开,谁也无法阻挡。但大家应多些理性、多些客观,对刚刚起步的这项事业只有好处没有坏处。