Impala is an open-source, fully-integrated, state-of-the-art MPP SQL query engine designed speci cally to leverage the flexibility and scalability of Hadoop.
Impala是基于Hadoop上的MPP方案,提供RDBMS-like的体验,比Hive要快,更符合BI的需求
架构上看,
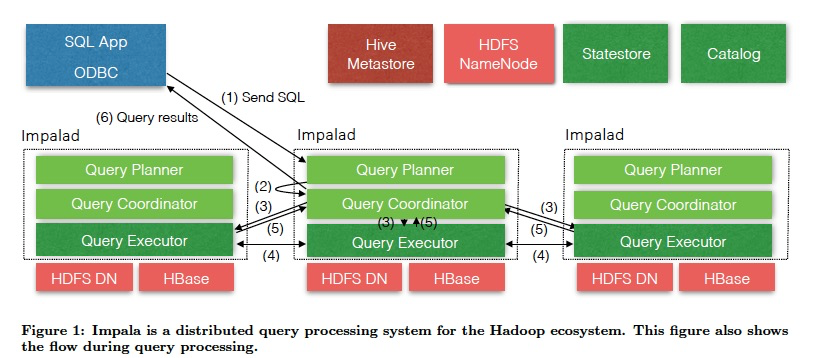
Impala主要分成如下几个模块,
impalaD,负责处理查询,每个机器上都会有,同时也会有Hdfs的datanode,便于data locality
Statestore,用于同步配置和元数据,基于subscribe-publish机制
CatalogD,catalog和元数据的gateway,因为元数据是存在外部存储,比如hive或hbase,可负责执行DDL命令

StateStore
因为impala每个daemon都是对等的,所以每个节点都需要实时知道最新的元数据变化,这样才能实时应对查询
比如,DDL发生变化,集群成员发生变化,查询路由发生变化
所以认为,数百个节点间的元数据同步是一个大的挑战
那么比较简单的想法,是pull的方式
我维护一个中心化的元数据服务,每个查询来的时候,实时去查,这个方案明显有很多不好的地方,单点,关键是会查询主路径上加入同步rpc
所以,Impala维护一个statestore,用publish-subscribe的方式把配置push给每个订阅的节点
statestore和节点间两种消息,更新消息和keepalive消息;并且statestore本身不会去persist数据,他只是充当一个元数据发布组件

Catalog service本身是catalog的gateway,好处可以替换底层的存储,对上层透明
但是这些catalog metadata还是要通过statestore广播给impala daemon;
并且一般catalogs会比较大,所以也是惰性加载,启动的时候只是加载skeleton

Impala执行查询,分为Frontend和Backend
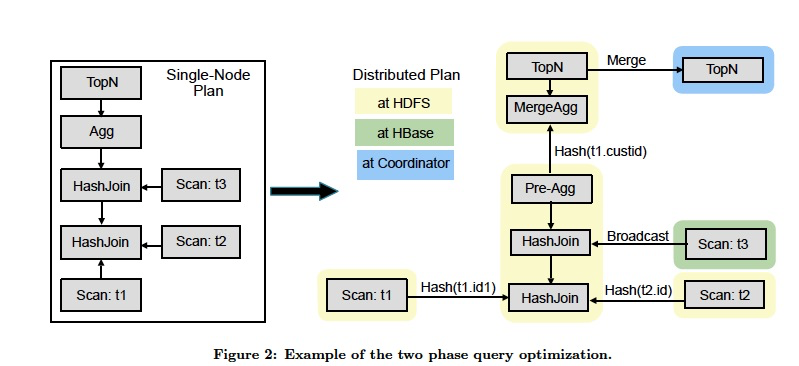
Frontend负责产生执行计划,Impala分两步产生计划,
先产生单节点的计划,如图的左半边
再产生并行化的计划,如图右边,
首先区分开,fragment boundary,类似于stage的概念,fragment可以在data locality执行
然后,定义数据交换的方式,比如在hbase中的维表,就可以广播
最后,增加pre-agg,local先预聚合,然后再merge,并且在Coordinator上进行topn

BackEnd, 主要就是用C++实现,并用code generation替代interpreted,大大提升执行效率

Impala支持各种存储格式,但推荐使用Parquet,

资源管理,Impala主要依赖Yarn,有点值得借鉴的是,在Impala和Yarn之间加了一层,Llama用于快速调度
