并行数据架构
https://csruiliu.github.io/blog/20170323-parallel-db-arch/
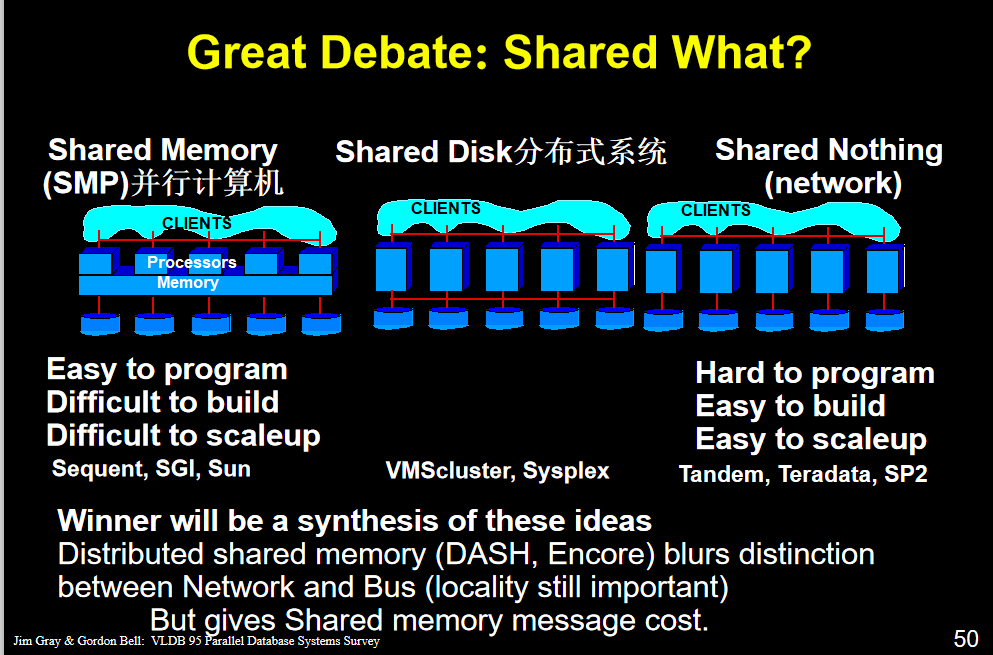
共享内存
两个不同的进程A.B共享内存说明,同一块物理内存被映射到A.B不同的进程地址空间。A可以及时看到B对共享内存的更改
优点:数据的共享使得进程间通行非常方便,函数接口也较简单。
进程间数据不用传送,而是直接访问内存,效率有所提升。
缺点:scability不好 过多的node会产生竞争
容错性也不好 memory crash或出现错误 那么整个系统都会出现问题
共享磁盘
多个node共享一个Disk但各自有各自的memory
提高fault tolerance 因为每个node都有自己的memory 一个或几个出问题时 整个平行数据库系统还能运行下去
scability也提升 但瓶颈从memory转到了disk 多个node对disk的竞争
无共享
共享机器仅通过网络连接
“无共享”架构意味着每个计算机系统都有自己的专用内存和专用磁盘。
每个CPU有自己的disk和memory。
搭建成本比前两种小了很多
多个node之间通信的开销大了很多,协调这些node带来很多overhead
需要自己调度,自己考虑怎么把资源用足
(更好的办法 把每个数据都partition到一个disk 再merge 这样保证每个节点都可以进行操作)
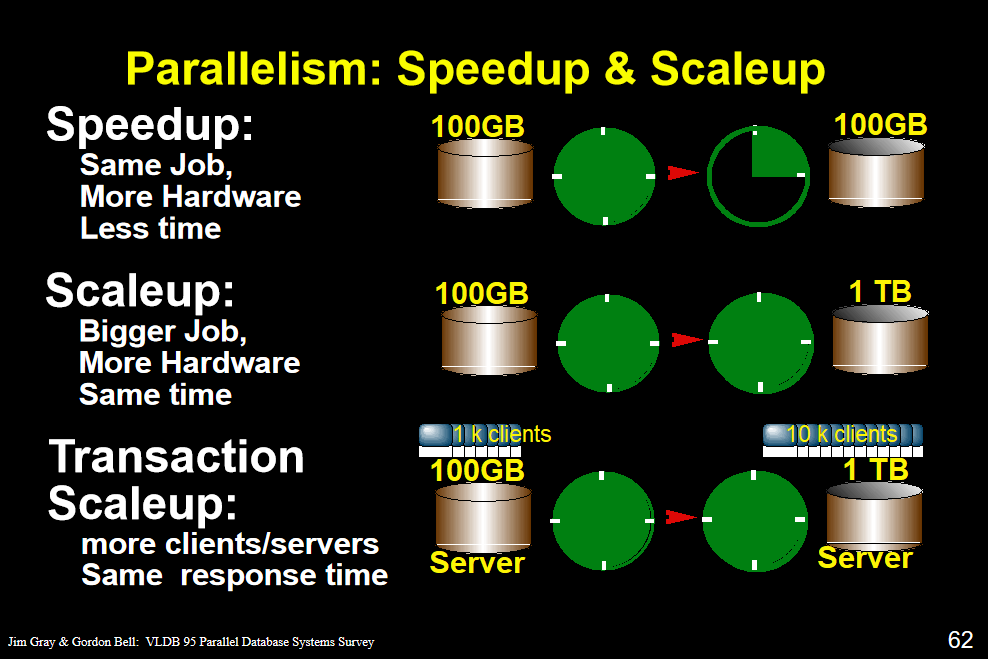
speedup 保持数据不变,扩大计算机的数目 相同的任务在更少的时间内完成
scaleup 数据增多,计算机数目也增多 在相同时间完成更多的任务
transaction scaleup 访问的人增加,硬件投入增加,响应时间不变
一个服务器可以连入更多的client
3.speedup和startup几乎线性的
并行系统性能提高接近线性
两个人做的速度接近一个人的两倍
两个人做任务 做之前分任务 做之后总计 校验 不可并行
4.


第二张图 加了硬件性能仍然没有提升 说明算法的问题 或协调额外开销成本过大
第三张图 最后的弯曲 每个任务被分成的大小过小 导致协调成本过高 性能会掉一点
time sharing 每台机器同时响应多个人 当前有请求的人排队,每个时间片给当前有请求的人
时间片循环 服务总人数=时间片*队列长度
从一个人切换到另一个人发生了context switch
context switch timer发一个中断 进入kernel mode
保存当前运行CPU的状态
将接下来的进程载入CPU rip指向新进程接下来要执行的指令
再从kernel mode切换回user mode
当time slice的大小接近于context switch的时间 机器感觉大部分时间都在context switch
额外开销抵充了并行提高的效率 并行系统性能下降

scanf取一条记录,count计数,最后汇总
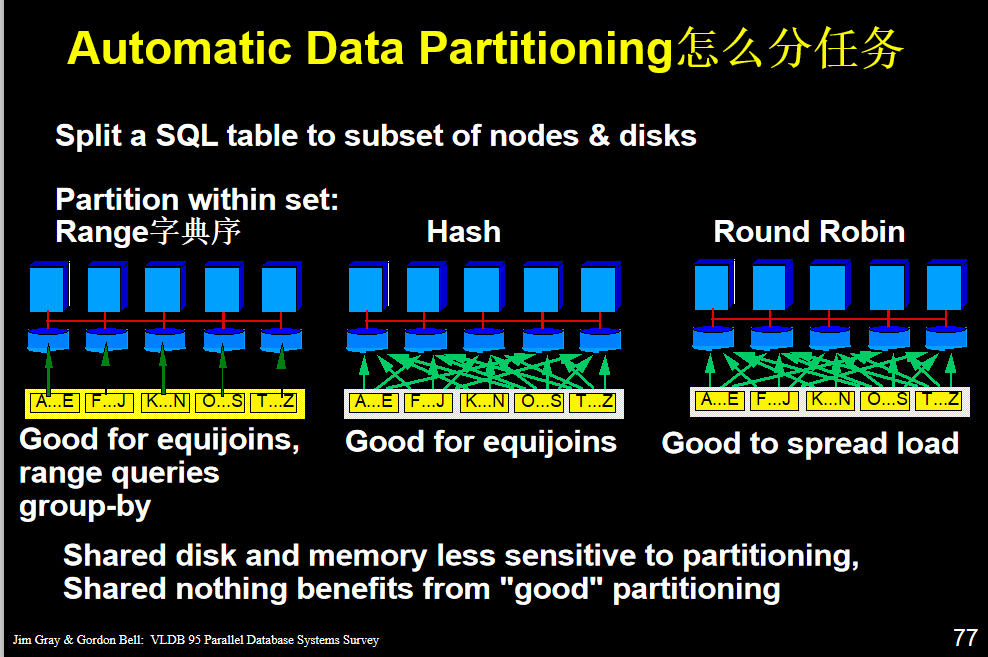
范围 分区根据您为每个分区建立的分区键值范围将数据映射到分区。
hash分区 对您标识的分区键应用的哈希算法将数据映射到分区。 哈希算法将行平均分配给分区,从而使分区的大小大致相同。 散列分区是在设备之间平均分配数据的理想方法。
好处 空间使用均与 取一个大素数的模 减少冲突(冲突意味着映射不均匀)
坏处 不适用于连续的数 将连续的学号分布到不同的地方 找起来麻烦
轮循分区

