
本文为《蚂蚁金服 Service Mesh 大规模落地系列》第六篇 - Operator 篇,该系列将会从核心、RPC、消息、无线网关、控制面、安全、运维、测试等模块对 Service Mesh 双十一大规模落地实践进行详细解析。文末包含往期系列文章。
引言
Service Mesh 是蚂蚁金服下一代技术架构的核心,也是蚂蚁金服内部双十一应用云化的重要一环,本文主要分享在蚂蚁金服当前的体量下,如何支撑应用从现有微服务体系大规模演进到 Service Mesh 架构并平稳落地。
本文作者:杜宏伟(花名:应明),蚂蚁金服技术专家,关注 API 网关,Service Mesh 和容器网络,蚂蚁金服 Service Mesh 核心成员。
为什么需要 Service Mesh
在此之前,SOFAStack 作为蚂蚁金服微服务体系下服务治理的核心技术栈,通过提供 Cloud Engine 应用容器、SOFABoot 编程框架(已开源)、SOFARPC(已开源) 等中间件,来实现服务发现和流量管控等能力。经过若干年的严苛金融场景的锤炼,SOFAStack 已经具备极高的可靠性和可扩展性,通过开源共建,也已形成了良好的社区生态,能够与其他开源组件相互替换和集成。在研发迭代上,中间件类库已经与业务解耦,不过避免不了的是,运行时两者在同一个进程内,意味着基础库的升级需要推动业务方升级对应的中间件版本。
我们一直在探索更好的技术实现方式。我们发现,Service Mesh 通过将原先通过类库形式提供的服务治理能力进行提炼和优化后,下沉到与业务进程协同,但独立运行的 Sidecar Proxy 进程中,大量的 Sidecar Proxy 构成了一张规模庞大的服务网络,为业务提供一致的,高质量的用户体验的同时,也实现了服务治理能力在业务无感的条件下独立进行版本迭代的目标。
应用 Service Mesh 的挑战
Service Mesh 带给我们的能力很美好,但现实为我们带来的挑战同样很多。比方说数据面技术选型和私有协议支持,控制面与蚂蚁金服内部现有系统对接,配套监控运维体系建设,以及在调用链路增加两跳的情况下如何优化请求延迟和资源使用率等等。
本文着重从 MOSN(Sidecar Proxy)的运维和风险管控方面,分享我们的实践经验,其他方面的挑战及应对方案,请参考系列分享中的其他文章。
MOSN:https://github.com/sofastack/sofa-mosn
Sidecar 注入
创建注入
已经完成容器化改造,运行在 Kubernetes 中的应用,如何接入到 Service Mesh 体系中?最简单的方式,也是以 Istio 为代表的 Service Mesh 社区方案所采用的方式,即是在应用发布阶段,通过 mutating webhook 拦截 Pod 创建请求,在原始 Pod Spec 的基础上,为 Pod 注入一个新的 MOSN 容器。
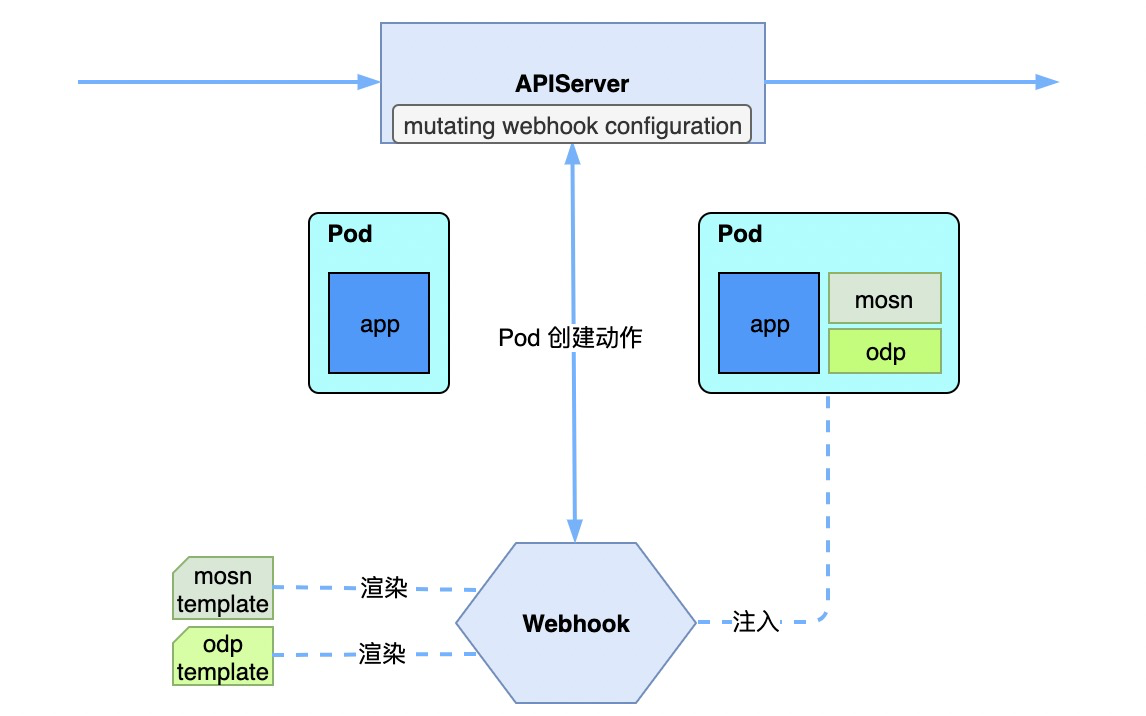
值得注意的是,在资源分配上,起初我们依据经验值,在应用 8G 内存的场景下,为 Sidecar 分配 512M 内存,即
App: req=8G, limit=8G
Sidecar: req=512M, limit=512M
很快我们就发现了这种分配方案带来的问题,一方面部分流量比较高的应用的 MOSN 容器,出现了严重的内存不足甚至 OOM;另一方面注入进去的 Sidecar 容器额外向调度器申请了一部分内存资源,这部分资源脱离了业务的 quota 管控。
因此,为了消除内存 OOM 风险和避免业务资源容量规划上的偏差,我们制定了新的“共享内存”策略。在这个策略下,Sidecar 的内存 request 被置为0,不再向调度器额外申请资源;同时 limit 被设置为应用的 1/4,保障 Sidecar 在正常运行的情况下,有充足的内存可用。为了确实达到“共享”的效果,蚂蚁金服 sigma 团队针对 kubelet 做了调整,使之在设置 Sidecar 容器 cgroups limit 为应用 1/4 的同时,保证整个 Pod 的 limit 没有额外增加(细节这里不展开)。
当然,Sidecar 与应用“共享”分配到的内存资源,也导致了在异常情况(比如内存泄露)下,sidecar 跟应用抢内存资源的风险。如何应对这个风险?我们的做法是,通过扩展 Pod Spec(及相应的 apiserver, kubelet 链路),我们为 Sidecar 容器额外设置了 Linux oom_score_adj 这个属性,以保障在内存耗尽的情况下,Sidecar 容器会被 OOM Killer 更优先选中,以发挥 sidecar 比应用能够更快速重启,从而更快恢复到正常服务的优势。
此外,在 CPU 资源的分配上,我们也遇到过在一些场景下,MOSN 抢占不到 CPU 资源从而导致请求延迟大幅抖动,解决方案是确保在注入 Sidecar 时,根据 Pod 内的容器数量,为每个 Sidecar 容器计算出相应的 cpushare 权重,并通过工具扫描并修复全站所有未正确设置的 Pod。
原地注入
在创建 Pod 的时候注入 Sidecar,是一件相对比较“舒服“的接入方式,因为这种做法,操作起来相对比较简单,应用只需先扩容,再缩容,就可以逐步用带有 Sidecar 的 Pod,替换掉旧的没有 Sidecar 的 Pod。可问题是,在大量应用,大规模接入的时候,需要集群有较大的资源 buffer 来供应用实例进行滚动替换,否则替换过程将变得十分艰难且漫长。而蚂蚁金服走向云原生的目标之一则是,双十一大促不加机器,提高机器使用率。如果说我们要花更多的钱购买更多的机器来支持云原生,就多少有点事与愿违了。
为了解决这个问题,我们提出了“原地注入”的概念,也就是说在 Pod 不销毁,不重建的情况下,原地把 Sidecar 注入进去。
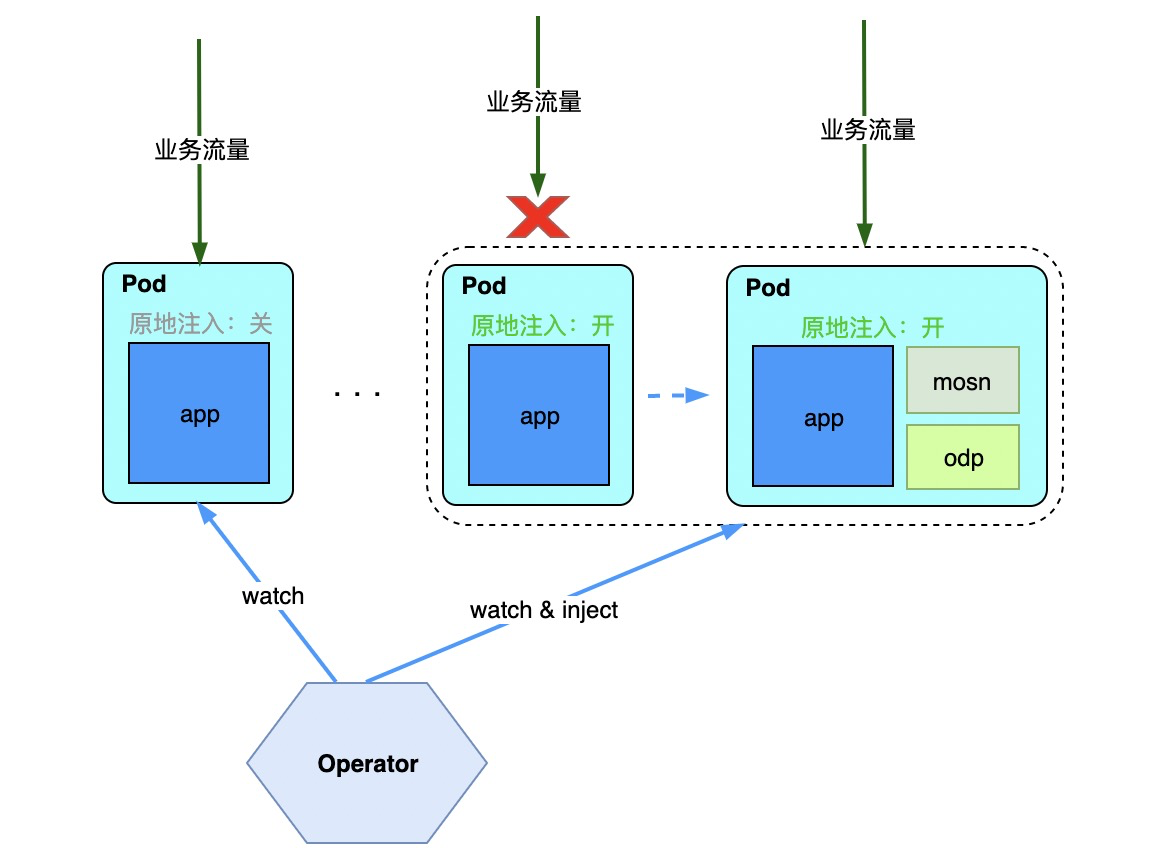
如图所示,原地注入由以下步骤构成:
在 PaaS 提交工单,选择一批需要原地注入的 Pod;
PaaS 调用中间件接口,关闭业务流量并停止应用容器;
PaaS 以 annotation 的形式打开 Pod 上的原地注入开关;
Operator 观察到 Pod 原地注入开关打开,渲染 sidecar 模版,注入到 Pod 中并调整 cpu/memory 等参数;
Operator 将 Pod 内容器期望状态置为运行;
kubelet 将 Pod 内容器重新拉起;
PaaS 调用中间件接口,打开业务流量;
Sidecar 升级
我们将 RPC 等能力从基础库下沉到 Sidecar 之后,基础库升级与业务绑定的问题虽然消除了,但是这部分能力的迭代需求依然存在,只是从升级基础库变成了如何升级 Sidecar。
最简单的升级就是替换,即销毁 Pod 重新创建出一个新的,这样新建出来的 Pod 所注入的 Sidecar 自然就是新版本了。但通过替换的升级方式,与创建注入存在相似的问题,就是需要大量的资源 buffer,并且,这种升级方式对业务的影响最大,也最慢。
非平滑升级
为了避免销毁重建 Pod,我们通过 Operator 实现了“非平滑升级”能力。
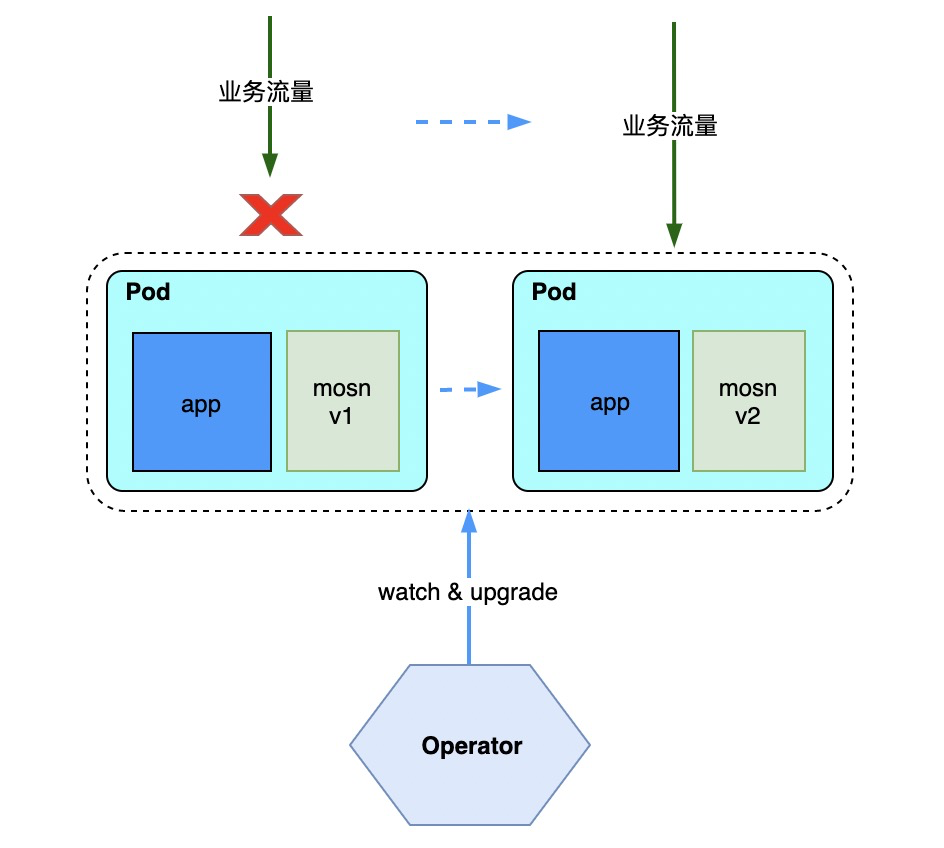
如图所示,非平滑升级需要:
PaaS 关流量,停容器;
Operator 替换 MOSN 容器为新版本,重新拉起容器;
PaaS 重新打开流量;
可以想到,原地升级 Pod 打破了 Kubernetes immutable infrastructure 的设计,为了能够实现我们的目标,sigma 团队修改了 apiserver validation 和 admission 相关的逻辑以允许修改运行中的 Pod Spec,也修改了 kubelet 的执行逻辑以实现容器的增删启停操作。
平滑升级
为了进一步降低 Sidecar 升级对应用带来的影响,我们针对 MOSN Sidecar 开发了“平滑升级”能力,以做到在 Pod 不重建,流量不关停,应用无感知的条件下对 MOSN 进行版本升级。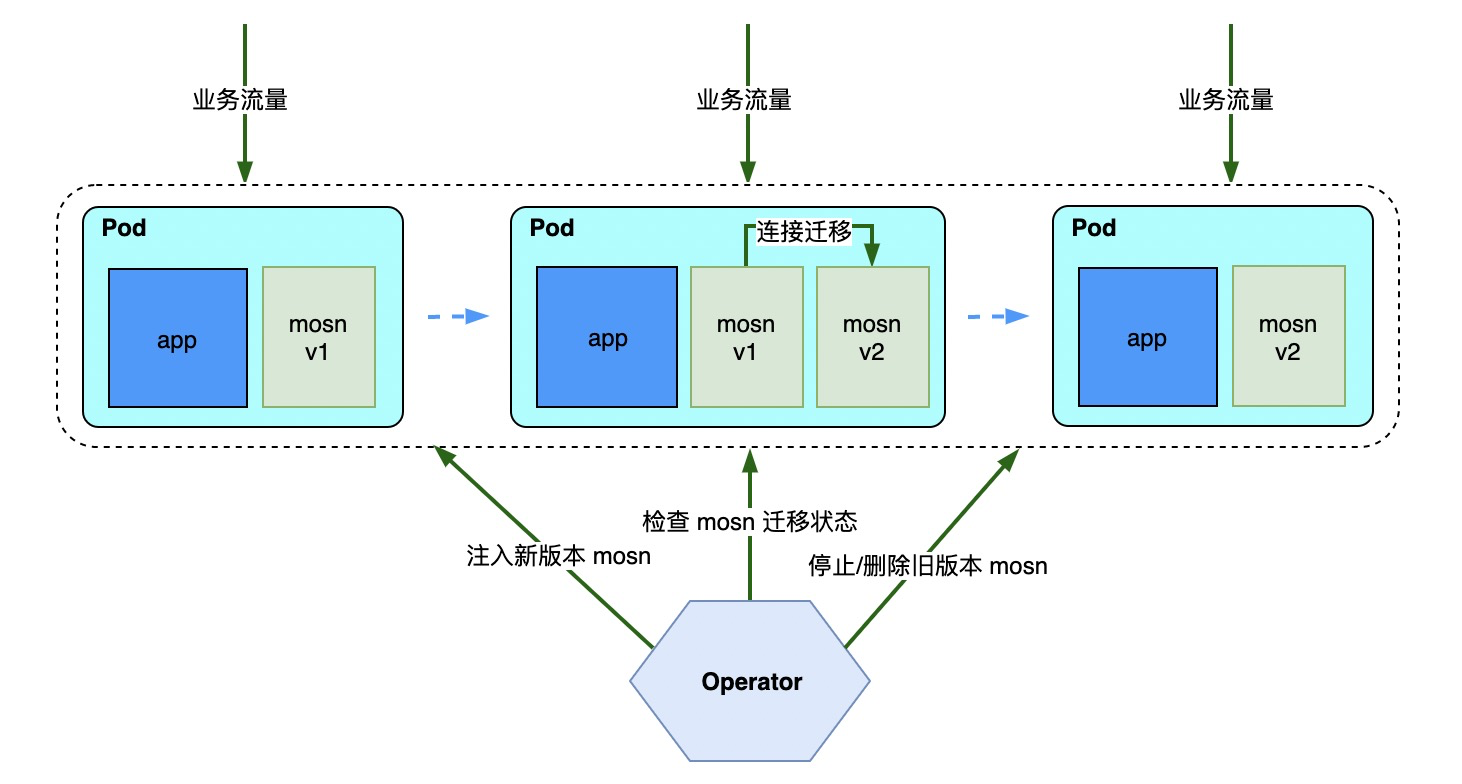
从上图可见,Operator 通过注入新 MOSN,等待 MOSN 自身进行连接和 Metrics 数据的迁移完成,再停止并移除旧 MOSN,来达到应用无感,流量无损的效果。整个过程看似没有很复杂,实则在各个环节上充斥着各种细节上的配合,目前为止,在平滑升级能力上,我们仍需在成功率方面努力,也需要改进 Operator 的状态机来提升性能。关于 MOSN 自身的连接迁移过程,读者如有兴趣,可参阅系列分享中的对应篇章。
Sidecar 回滚
为了确保大促活动万无一失,我们还提供了 Sidecar 回滚的保底方案,以备在识别到 Service Mesh 出现严重问题的情况下,迅速将应用回滚到未接入 Sidecar 的状态,使用应用原先的能力继续提供业务服务。
风险管控
从技术风险角度来看,关于 Sidecar 的所有运维操作,都要具备三板斧能力。在灰度能力上,Operator 为升级等运维动作增加了显式的开关,确保每个执行动作符合用户(SRE)的期望,避免不受控制地,“偷偷地“自动执行变更操作。
监控方面,在基本的操作成功率统计、操作耗时统计、资源消耗等指标之外,仍需以快速发现问题、快速止血为目标,继续完善精细化监控。
Operator 目前对外提供的几个运维能力,细节上都比较复杂,一旦出错,影响面又很大,因此单元测试覆盖率和集成测试场景覆盖率,也会是后续 Service Mesh 稳定性建设的一个重要的点去努力完善。
未来的思考
演进到 Service Mesh 架构后,保障 Sidecar 自身能够快速,稳定的迭代十分重要。相信在未来,除了继续增强 Operator 的能力,也需要通过以下几个可能的优化手段,来做到更好的风险控制:
对 Sidecar 模版做版本控制,由 Service Mesh 控制面,而非用户来决定某个集群下某个应用的某个 Pod 应该使用哪个版本的 Sidecar。这样既可以统一管控全站的 Sidecar 运行版本,又可以将 Sidecar 二进制和其 container 模版相绑定,避免出现意外的,不兼容的升级。
提供更加丰富的模版函数,在保持灵活性的同时,简化 Sidecar 模版的编写复杂度,降低出错率。
设计更完善的灰度机制,在 Operator 出现异常后,快速熔断,避免故障范围扩大。
持续思考,整个 Sidecar 的运维方式能否更加“云原生”?
最后
双十一的考验强化了我们在云原生道路上探索的信心,未来还有很长的路要走,任重而道远。期望我们能够与更多感兴趣的同学交流,一起建设 Service Mesh 技术体系,继续用技术帮助业务更好发展。
SOFAStack 部分开源项目地址:
SOFABoot:https://github.com/sofastack/sofa-boot
SOFARPC:https://github.com/sofastack/sofa-rpc
蚂蚁金服 Service Mesh 大规模落地系列文章
Service Mesh 相关活动报名中

Service Mesh Meetup 第9期来啦,本期与滴滴联合举办,将深入 Service Mesh 的落地实践,并带领大家探索 Service Mesh 在更广阔领域的应用。欢迎参加~
主题:Service Mesh Meetup#9 杭州站:To Infinity and Beyond
时间:2019年12月28日13:00-17:30
地点:杭州西湖区紫霞路西溪谷G座8楼
报名方式:点击“这里”,即可报名