Pandas里三种调用函数应用的方法:
1:apply作用于DF的列或行
2:applymap作用于DF的所有元素
3:map作用于Series的所有元素
agg函数很多情况下都是和groupby组合使用,通常指代分组聚合,它和apply的区别不是很明显,一般当调用自定义函数,没有聚合这个概念时最好使用apply。
先上代码:核心代码是25、54、58行
# -*- coding:utf-8 -*-
from datetime import datetime
import pandas as pd
#*****************
##按天口径出的phone结果
# 口径:1)关键词且官网 2)关键词且app 3)关键词访问大于1 4)官网访问大于1
#*****************
def Main():
dataList = '/data/u_lx_data/zhangqm/sh/yanjie/dudu/result_4G/list09.txt'
# 对照表清单数据(加密和不加密手机号对应关系)
mapRuletxt = '/data/u_lx_data/zhangqm/sh/yanjie/dudu/result_4G/mapRuletxt.txt'
targetTxt = '/data/u_lx_data/zhangqm/sh/yanjie/dudu/result_4G/target2.txt'
# 存储最终解果
phoneSet = set()
# 存储有关键词行为的phone
kwPhoneSet = set()
# 存储有官网行为的phone
webPhoneSet = set()
# app行为
appPhoneSet = set()
#存储对照表清单数据
dict={}
uname = ['phone', 'time', 'name']
# 找官网的数据
def web(str):
if str.find('app') == -1 and str.find('kw') == -1:
return str
print("开始。。。。。")
print(datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
with open(mapRuletxt,'r') as fr:
for line in fr:
line = line.strip().split("\t")
dict[line[1]] = line[0]
with open(dataList,'r') as fr:
for line in fr:
line = line.strip().split("\t")
if line[2].find('app') != -1: # app的
appPhoneSet.add(line[0])
elif line[2].find('kw') != -1: #关键词搜索的
kwPhoneSet.add(line[0])
else: # 官网访问行为的
webPhoneSet.add(line[0])
# 有过关键词搜索行为且有过官网访问行为的phone
for kwphone in kwPhoneSet:
if kwphone in webPhoneSet:
phoneSet.add(kwphone)
# 有过关键词搜索行为且有过app行为的phone
for kwphone in kwPhoneSet:
if kwphone in appPhoneSet:
phoneSet.add(kwphone)
# 关键词访问大于1的phone
df = pd.read_table(dataList, sep="\t", header=None, names=uname, index_col=False)[['phone', 'name']]
kw = df[df.name.str.contains('kw')].groupby('phone')['name'].agg([('uv',pd.Series.nunique)]).reset_index()
for phone in kw[kw.uv > 1]['phone']:
phoneSet.add(phone)
# 官网访问大于1的phone
web = df.applymap(web).dropna().groupby('phone')['name'].agg([('uv',pd.Series.nunique)]).reset_index()
for phone in web[web.uv > 1]['phone']:
phoneSet.add(phone)
with open(targetTxt,'w+') as fw:
for phone in phoneSet:
if phone in dict:
fw.write(dict[phone]+"\n")
print("结束。。。。。")
print(datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
if __name__ == "__main__":
Main()
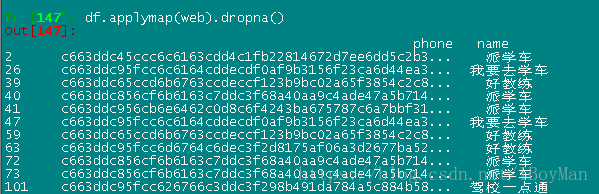
df里的数据如图:

选出name列不包含app和kw的数据,经过代码df.applymap(web).dropna()就可以实现如图:
groupby和agg使用有一个注意点:
1:df[df.name.str.contains('kw')].groupby('phone')['name'].agg([('uv',pd.Series.nunique)])

2:df[df.name.str.contains('kw')].groupby('phone').agg([('name',pd.Series.nunique)])

其实1和2的最终结果是一样的,不一样的是结果对应的列名
当groupby之后跟指定的列agg函数里既可以写成自己需要的列名,如果不
跟指定的列agg函数里就必须写DF里的列名,不然会报不存在的列。