当表很大的时候可以设计冗余字段,避免与大表连表查询造成性能低下
比如日志表和用户表,日志表通常到后期会相当的大可以做一个username的冗余字段,避免查看username的时候去和user表关联
当分页过大时的优化策略
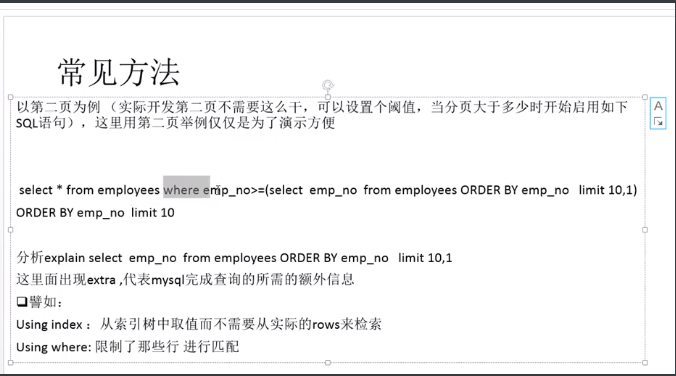
下图的例子是直接使用where去检索一个非索引列,结果是采用全文检索的方式

通过加上order by 索引列把上图查询的type优化成index
使用BTree索引优化查询 发现type变成了ref
BTree索引

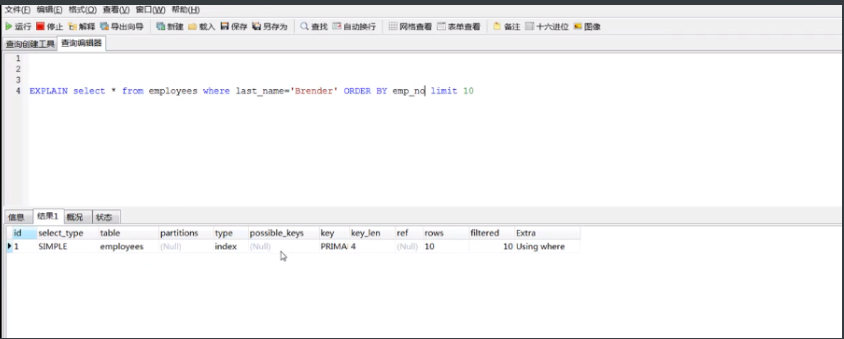
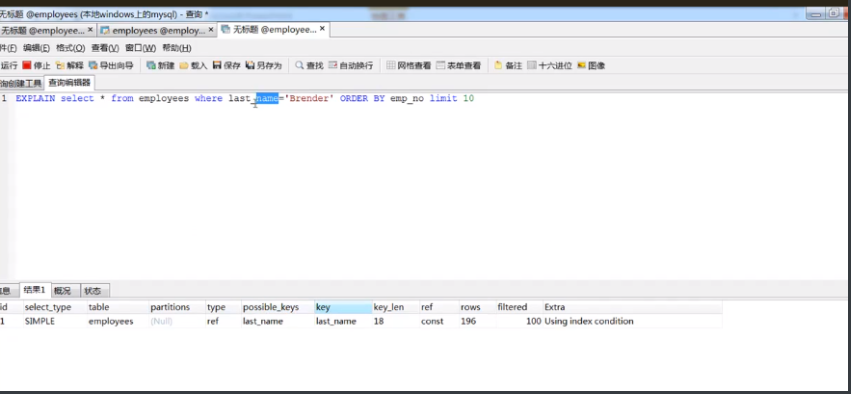
下图的查询classType有normal索引,索引方式为btree这个时候type是ref速度已经很快了

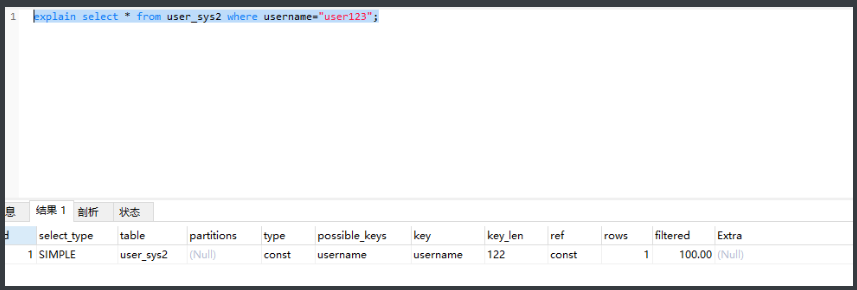
当查询身份证但是身份证有x所以不能用纯数字,只能用vachar,这时候可以加上唯一索引, 索引方式用btree,这样查询的type会变成const速度相当的块
如下图user_sys2的唯一索引是username,并且索引方式是Btree,所以这个时候type就变成了const
count(*)在MyIsam中非常快,因为MyIsam引擎已经保存了行数,但是Innodb需要自己计算
count(*)统计所有记录行
count(column)统计不为NULL的数据的条目
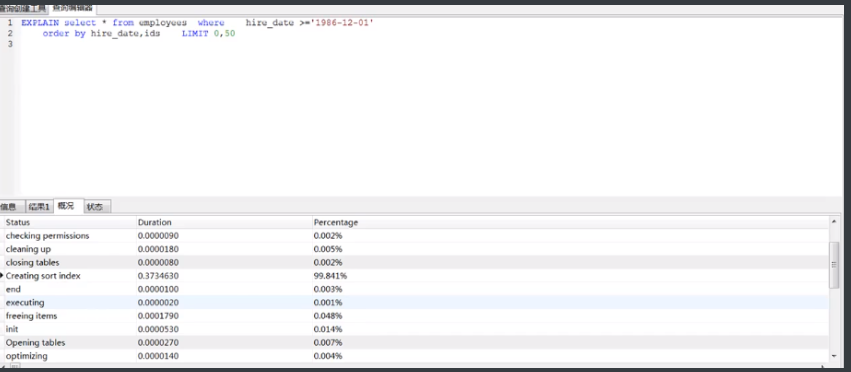
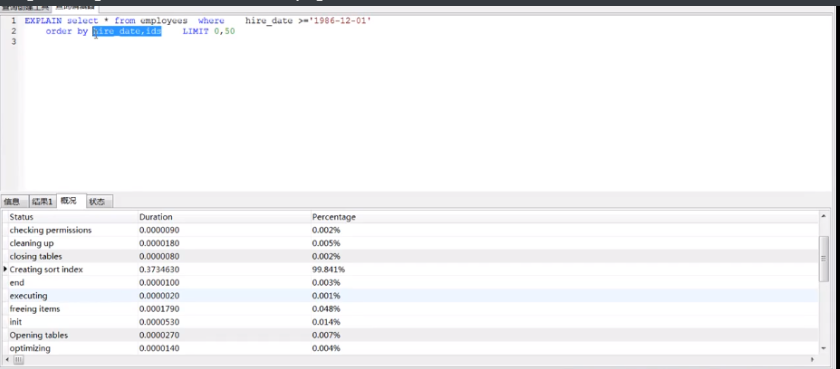
当order by 需要两个列去排序的时候要创建联合索引,下图hire_date和ids都分别有各自的索引,但是查询的时候会使用All,开销都花在创建排序索引上面,看下面2图,可以发现creating sort index消耗占比%99.841
这个时候如果我们把hire_date,ids加上联合索引,查询速度就会大大的提升,下图此时type已经变成range
联合索引不可以随便创建,只有经常需要联合查询的数据列才需要加联合索引,因为加索引会影响插入和修改速度,因为inndb的索引下叶子节点都是直接存放有数据的,因此查询块,不用到磁盘扫描,但是插入的时候就包含创建索引和数据拷贝,所以会导致插入和修改速度慢

limit优化
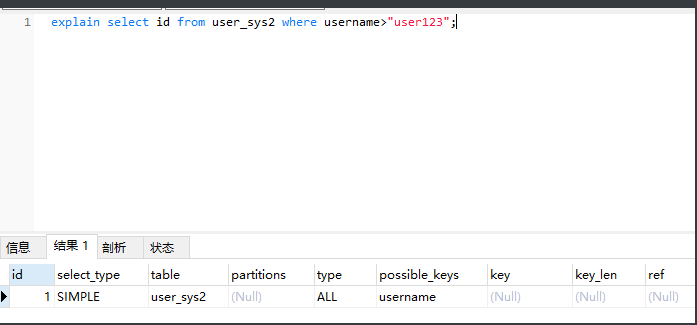
where条件查询username上有索引但是如果不加limit使用的是all
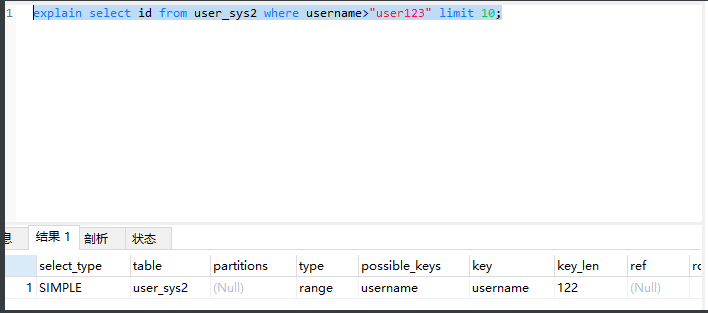
加上了limit之后就会变成range
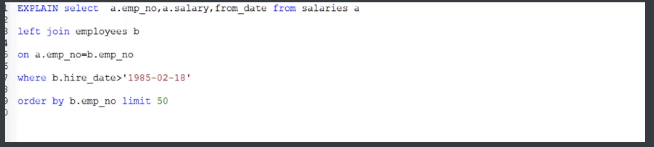
limit优化用错排序字段遇到的坑,因为是联表,因为用到的是b表的查询条件,但是排序用的是a表的,所以虽然type是range但是extra有using temporary,using filesort此时我们是需要优化的
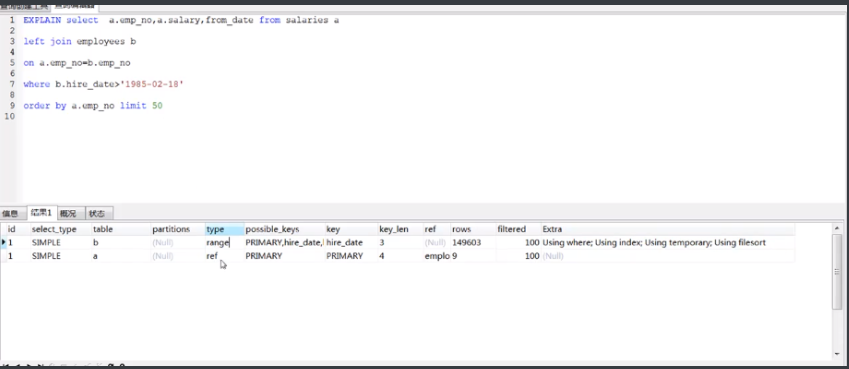
排序和查询都用一张表的索引字段,这样虽然type变成了index 但是extra只有一个where 速度就快了好多

分组查询倒排序速度很慢,因为排序过程中的s并不是索引字段,而是max(salary)

使用下面的方式已经优化了一些但是依然不够,可以用第三方来完成我们的sql优化,可以吧分组查询结果单独建立一张表,当有数据产生时需要去修改这张表

