目标分析
m3u8
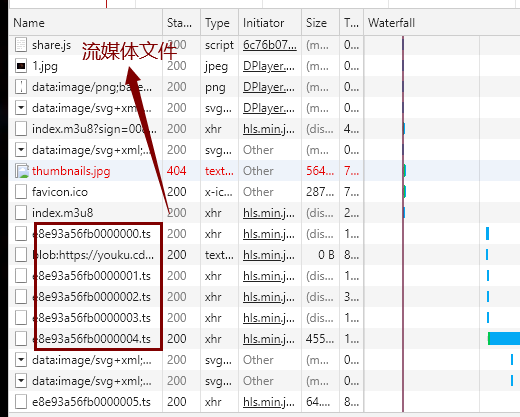
服务器将一个完整的视频切割成1000份;把每一小份视频存储到一个m3u8文件中;
还有一个m3u8文件存储着这个视频是否加密,以及该视频小m3u8目录存放的具体位置
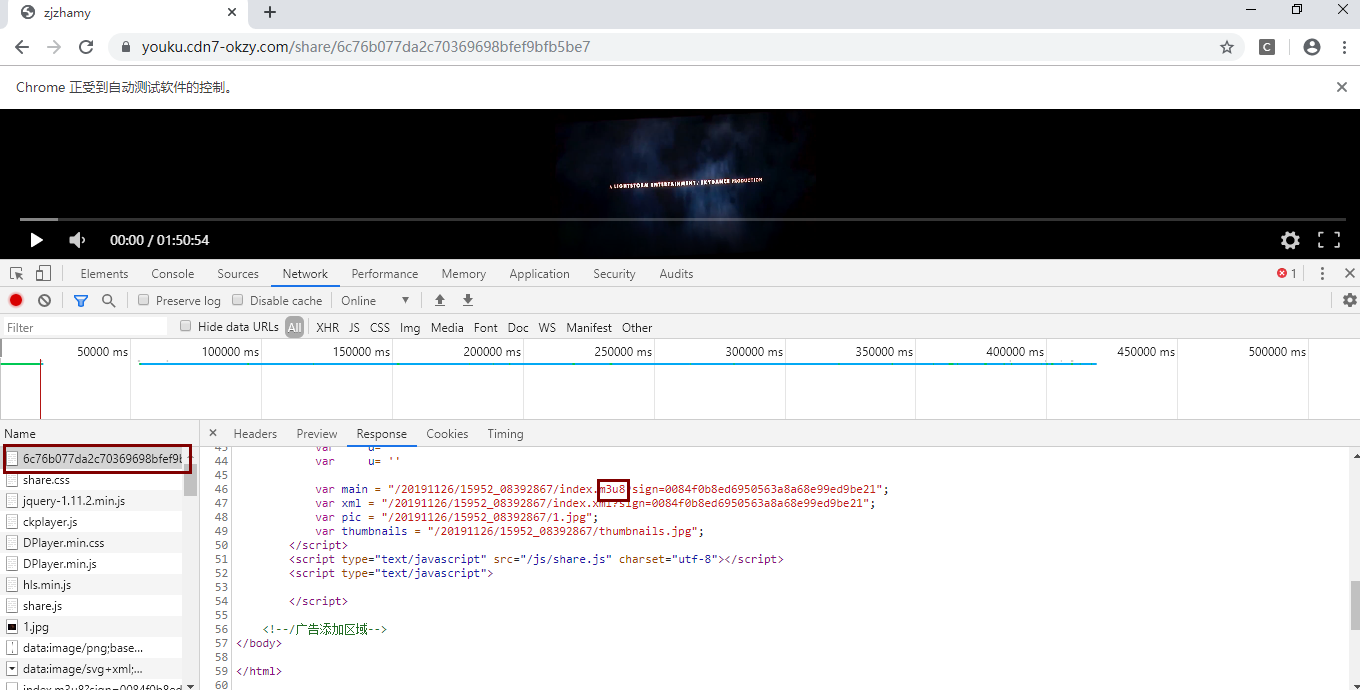
而浏览器拿到的是一个大的m3u8文件
爬取思路
- 先请求到主页面
- 找到大的m3u8文件,拿到第一层m3u8大文件
- 找到每个小的m3u8文件
- 下载每个小的m3u8文件
- 将下载的m3u8文件组合成完整的视频
请求主页面,拿到大的m3u8文件的url
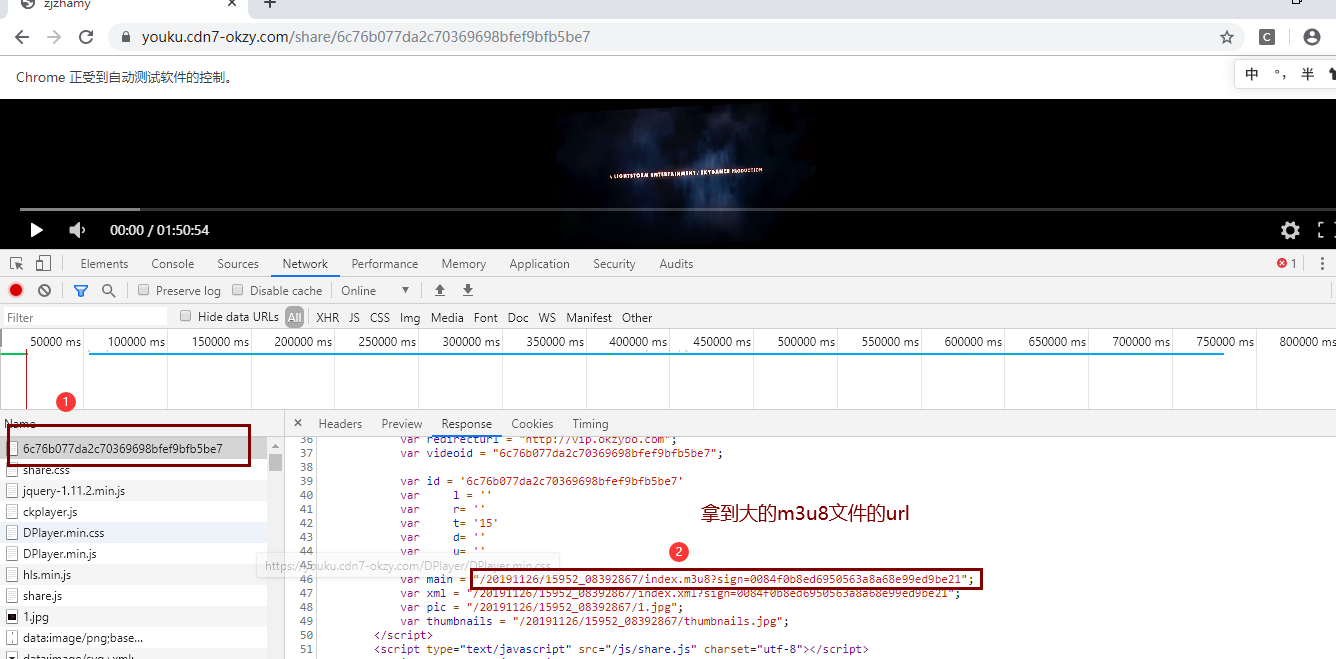
通过大的m3u8文件的url,找到该文件
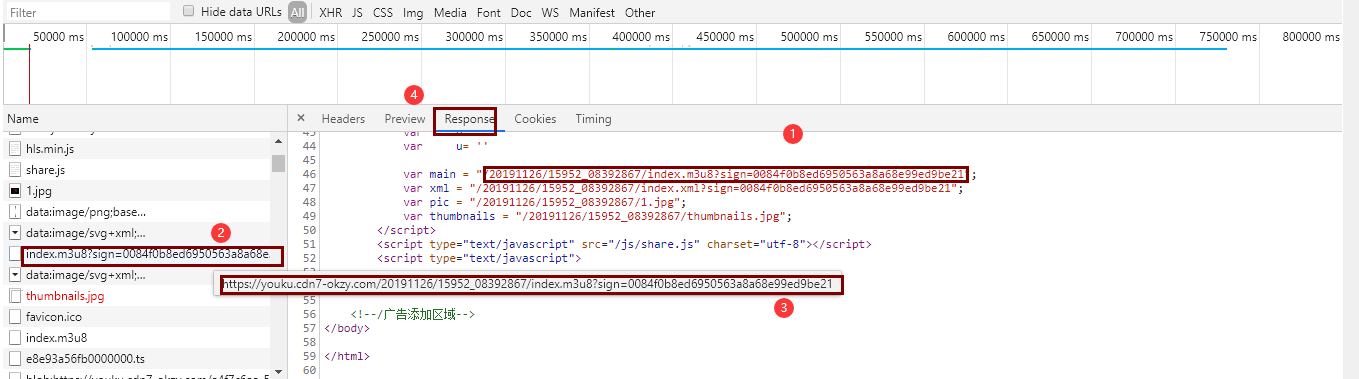
点击大的m3u8文件,获取第一层m3u8文件的路径(1000k/hls/index.m3u8)
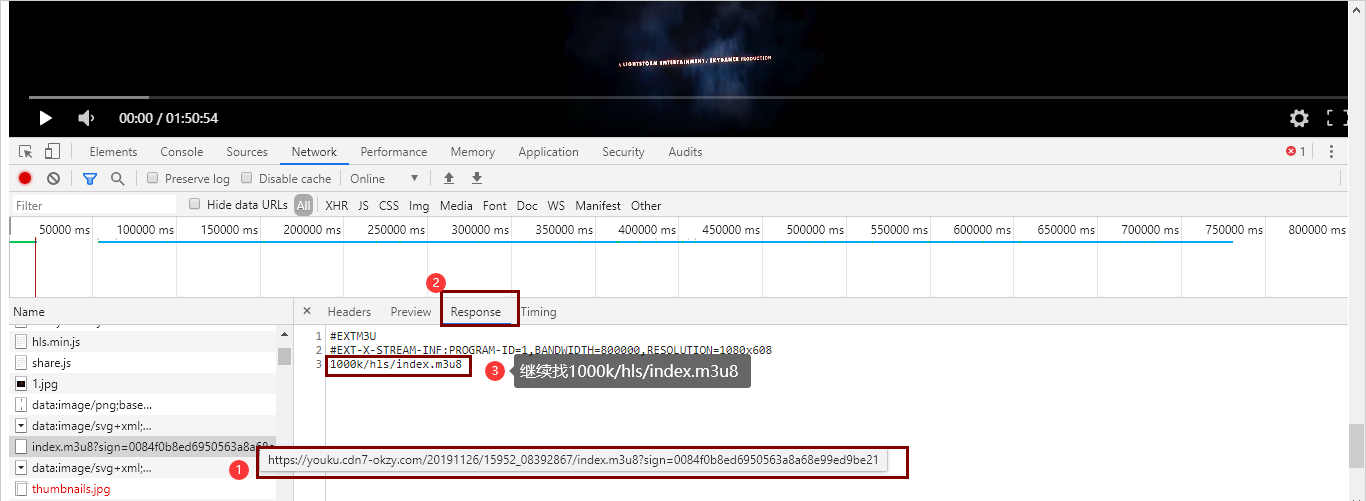
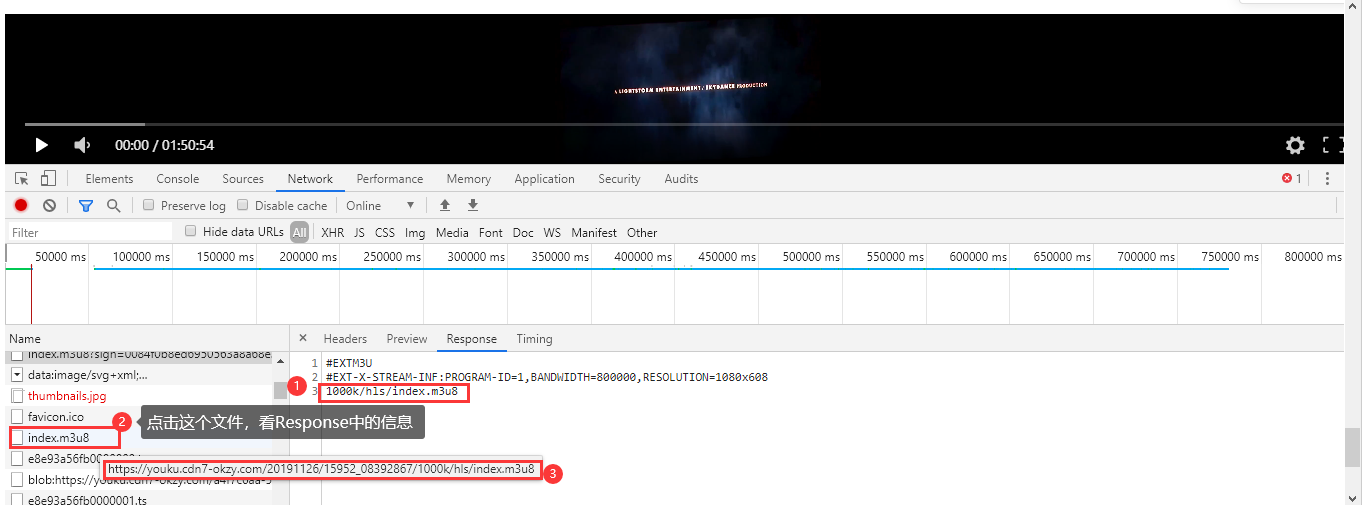
找到第一层m3u8文件,点击获取第一层m3u8文件小m3u8文件的存储路径
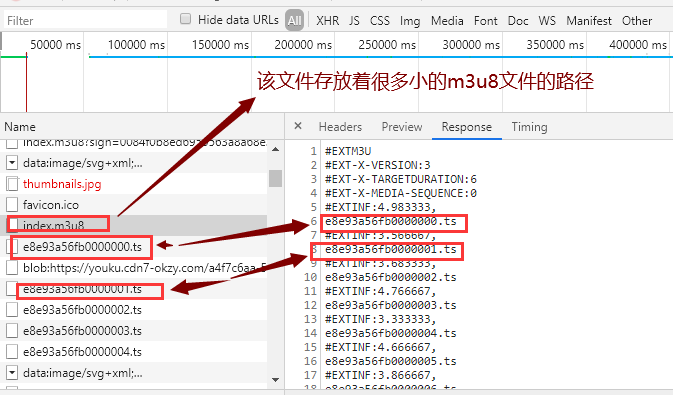
下载每个小的m3u8文件
将下载的m3u8文件组合成完整的视频
代码实现
from selenium.webdriver import Chrome import time web = Chrome(executable_path=r'C:\Users\yun\爬虫+数据\chromedriver_win32(1)\chromedriver.exe') web.get("http://www.yy6080.cn/") # 找到热播电影. 然后找到超链接. # /html/body/div[4]/div[2]/div[2]/div/a lst = web.find_element_by_xpath('/html/body/div[4]/div[2]').find_elements_by_tag_name("a") print(lst) for item in lst: item.click() # 点击超链接 time.sleep(1) # 程序睡1秒钟等待浏览器加载内容 # 让浏览器切换窗口. 切换到最后一个窗口 web.switch_to.window(web.window_handles[-1]) # 点击HD超清 web.find_elements_by_class_name('resource-list')[0].find_element_by_tag_name("a").click() time.sleep(1) # 移动到最后的窗口里 web.switch_to.window(web.window_handles[-1]) src = web.find_element_by_xpath('//*[@id="playleft"]/iframe[2]').get_property("src") print(src) # 能够拿到电影的url地址(不是真实地址, 只是一个播放地址) web.close() time.sleep(1) web.switch_to.window(web.window_handles[-1]) web.close() time.sleep(1) web.switch_to.window(web.window_handles[-1])
import requests import re from multiprocessing import Pool # 导入进程池 import os # 事先准备的一个变量, 放cookies cookies = None def get_m3u8_url(url): # 电影的路径, 返回的大m3u8路径 global cookies resp = requests.get(url, headers={ "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36" }) cookies = resp.cookies # 拿到m3u8地址 obj = re.compile(r'var main = "(?P<name>.*?)"', re.S) lst = obj.findall(resp.text) return lst[0] def get_first_m3u8(m3u8): # http://baidu.com-ok-baidu.com/20191011/15297_e281e833/index.m3u8?sign=f4bc72c8adcd91760d3e511c331c99d5 resp = requests.get(m3u8, headers={ "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36" }) f = open("first_m3u8", mode="wb") f.write(resp.content) f.close() f = open("first_m3u8", mode="r", encoding="utf-8") f.readline() f.readline() url = f.readline() # # http://baidu.com-ok-baidu.com/20191011/15297_e281e833/1000k/hls/index.m3u8 m3u8_url = m3u8.replace("index.m3u8", url) return m3u8_url def get_second_m3u8(m3u8_url): resp = requests.get(m3u8_url, headers={ "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36" }) f = open("second_m3u8", mode="wb") f.write(resp.content) f.close() def download_movie(url, name): resp = requests.get(url, headers={ "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36" }, cookies=cookies) f = open("movie/"+name, mode="wb") f.write(resp.content) f.close() print("download: %s 完毕" % name) # http://baidu.com-ok-baidu.com/20191011/15297_e281e833/1000k/hls/5a1c58d6098000000.ts def download_main(m3u8_url): pool = Pool(10) # 准备一个进程池 f = open("second_m3u8", mode="r", encoding="utf-8") for line in f: if line.startswith("#"): continue else: # "http://baidu.com-ok-baidu.com/20191011/15297_e281e833/1000k/hls/index.m3u8" # "http://baidu.com-ok-baidu.com/20191011/15297_e281e833/1000k/hls/5a1c58d6098000000.ts" download_url = m3u8_url[:m3u8_url.rfind("/")+1] + line.strip() # 丢到进程池里. 去下载 pool.apply_async(download_movie, (download_url, line.strip())) pool.close() # 关闭进程池,关闭后po不再接收新的请求 pool.join() if __name__ == '__main__': # http://baidu.com-ok-baidu.com/share/666448e909901d786f4016828c1312c9 m3u8 = get_m3u8_url("http://baidu.com-ok-baidu.com/share/666448e909901d786f4016828c1312c9") # http://baidu.com-ok-baidu.com/20191011/15297_e281e833/index.m3u8?sign=f4bc72c8adcd91760d3e511c331c99d5 m3u8_url = get_first_m3u8("http://baidu.com-ok-baidu.com/"+m3u8) # 拿到的就是小m3u8的路径 get_second_m3u8(m3u8_url) download_main(m3u8_url) os.system("copy /b movie/*.ts movie/1.ts") # copy /b source target windows os.system("cat movie/*.ts > movie/1.ts") # cat source > target mac和linux # 服务器: # 把一个视频切割成1000份 # 把每一小份的路径存在一个m3u8的文件中 # 还有一个m3u8文件记录着这个视频是否加密. 以及该视频的小m3u8目录存放的具体位置 # 交给你的浏览器的是 m3u8大文件1 # 我们的流程应该是: 先请求到主页面-> 找到m3u8大文件, 拿到第一层m3u8大文件 -> m3u8小文件 -> 下载每个小视频 -> 把每个小视频合并成一个大视频