预防机制
在开发高并发系统时有三把利器用来保护系统:缓存、降级和限流。
缓存:
目的是提升系统访问速度和增大系统能处理的容量,在实际的开发过程中,针对于一些基础档案类数据或者配置参数类数据,我们一般用缓存读取,原因是这些数据的变化性不大,这一部分我们可以减少和数据库的IO交互
缓存失效分为几种场景:1.缓存服务挂了 2.高分期缓存失效 3.热点缓存失效
解决方案:注意这里的校验是两次,这里参照单列模式的DCL双重校验锁机制。(嗯....讲道理这里要整一个volatile 内存屏障 )
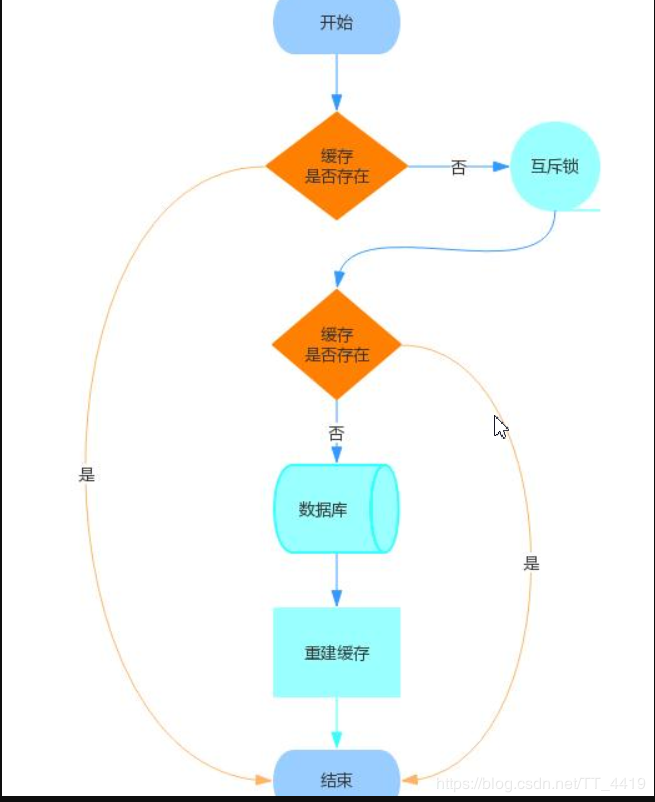
降级:
降级是指在某些高并发场景下,把某些非核心的业务统统往下调。诸如双11交易时,查看蚂蚁深林,蚂蚁庄园之类的服务,仅仅显示一百条数据。
当然降级的颗粒度 ,可以自由调配,根据实际业务和当前的服务器并发请求。比如说,你也可以限制数据库的跟新与插入,但是允许查询操作。
从RPC的角度来说,我访问的是本地服务的伪装者,而不是应用服务本身。
限流:
限流指的是降低一定时间内的并发访问量 一般两种做法 一种是拉长时间,一种是降低访问QPS()
一般开发高并发系统常见的限流有:限制总并发数(比如数据库连接池、线程池)、限制瞬时并发数(如nginx的limit_conn模块,用来限制瞬时并发连接数)、限制时间窗口内的平均速率(如Guava的RateLimiter、nginx的limit_req模块,限制每秒的平均速率);其他还有如限制远程接口调用速率、限制MQ的消费速率。另外还可以根据网络连接数、网络流量、CPU或内存负载等来限流。
限流算法:
限流算法一般分为以下几种:滑动窗口,漏桶,令牌桶.
滑动窗口:
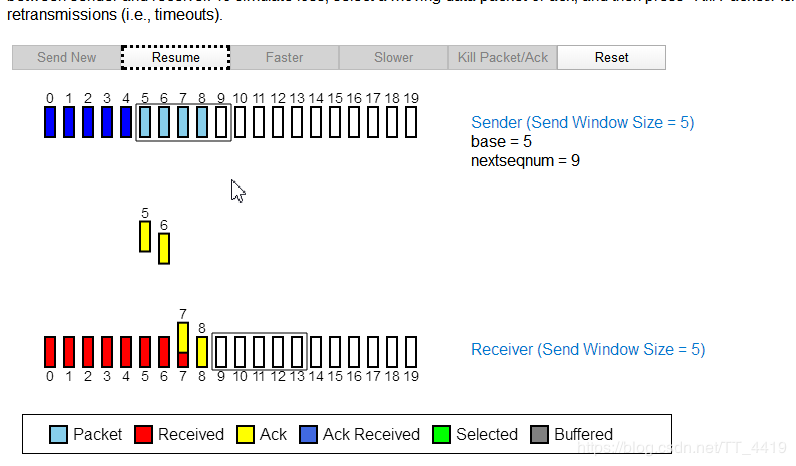
发送和接受方都会维护一个数据帧的序列,这个序列被称作窗口。发送方的窗口大小由接受方确定,目的在于控制发送速度,以免接受方的缓存不够大,而导致溢出,同时控制流量也可以避免网络拥塞。下面图中的4,5,6号数据帧已经被发送出去,但是未收到关联的ACK,7,8,9帧则是等待发送。可以看出发送端的窗口大小为6,这是由接受端告知的。此时如果发送端收到4号ACK,则窗口的左边缘向右收缩,窗口的右边缘则向右扩展,此时窗口就向前滑动了,即数据帧10也可以被发送。
这个是滑动窗口的演示地址,很形象
https://media.pearsoncmg.com/aw/ecs_kurose_compnetwork_7/cw/content/interactiveanimations/selective-repeat-protocol/index.html
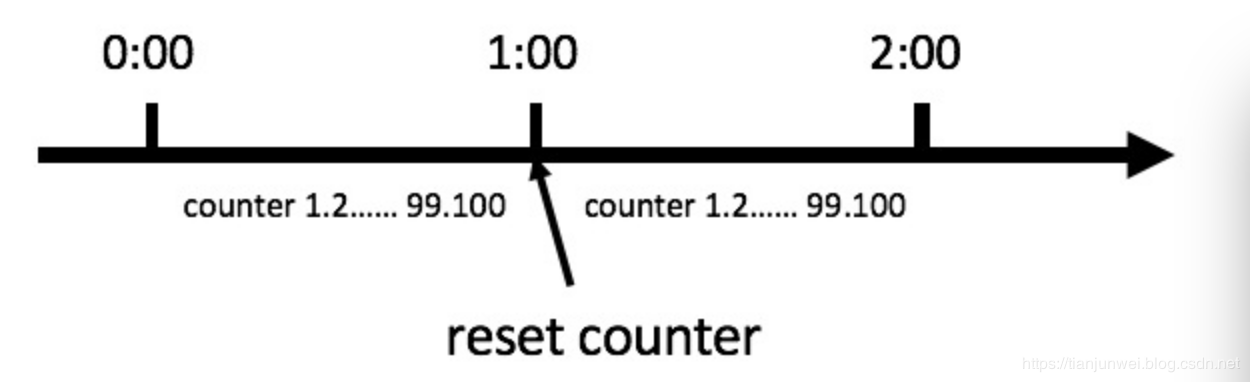
滑动窗口计数器算法是限流算法里最简单也是最容易实现的一种算法。比如我们规定,对于A接口来说,我们1分钟的访问次数不能超过100个。那么我们可以这么做:在一开 始的时候,我们可以设置一个计数器counter,每当一个请求过来的时候,counter就加1,如果counter的值大于100并且该请求与第一个 请求的间隔时间还在1分钟之内,那么说明请求数过多;如果该请求与第一个请求的间隔时间大于1分钟,且counter的值还在限流范围内,那么就重置 counter,具体算法的示意图如下:
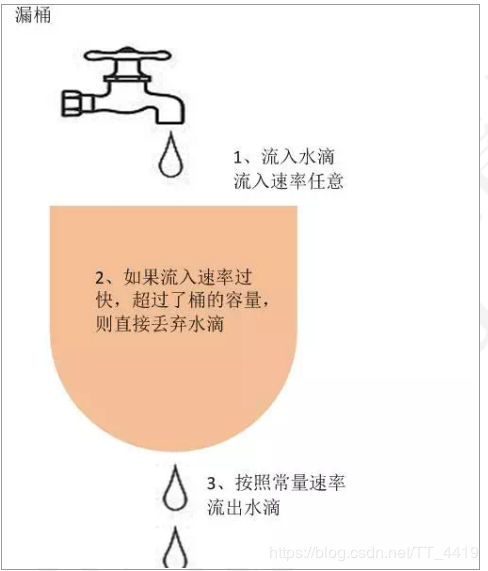
漏桶(控制传输速率 leaky bucket):
漏桶算法思路是,不断的往桶里面注水,无论注水的速度是大还是小,水都是按固定的速率往外漏水;如果桶满了,水会溢出;
桶本身具有一个恒定的速率往下漏水,而上方时快时慢的会有水进入桶内。当桶还未满时,上方的水可以加入。一旦水满,上方的水就无法加入。
桶满正是算法中的一个关键的触发条件(即流量异常判断成立的条件)。而此条件下如何处理上方流下来的水,有两种方式
在桶满水之后,常见的两种处理方式为:
1)暂时拦截住上方水的向下流动,等待桶中的一部分水漏走后,再放行上方水。
2)溢出的上方水直接抛弃。
特点
1. 漏水的速率是固定的
2. 即使存在突然注水量变大的情况,漏水的速率也是固定的
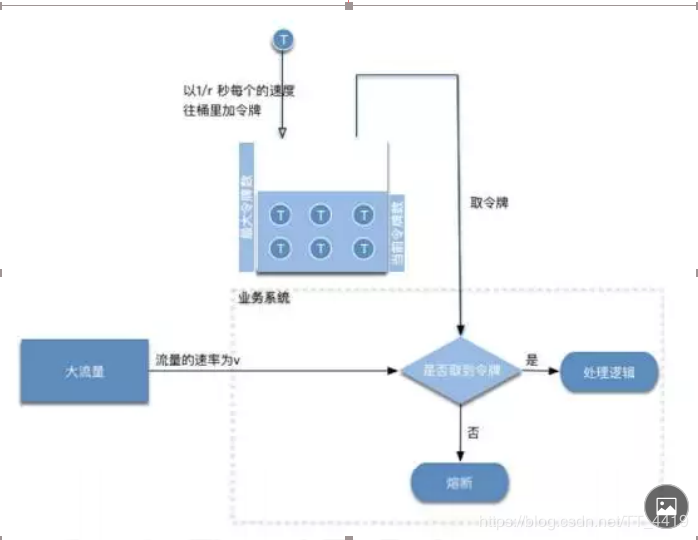
令牌桶(解决突发流量)
令牌桶算法是网络流量整形(Traffiffiffic Shaping)和速率限制(Rate Limiting)中最常使用的一种算法。典型情况下,令牌桶算法用来控制发送到网络上的数据的数目,并允许突发数据的发送。
令牌桶是一个存放固定容量令牌(token)的桶,按照固定速率往桶里添加令牌; 令牌桶算法实际上由三部分组成:两个流和一个桶,分别是令牌流、数据流和令牌桶
令牌流与令牌桶
系统会以一定的速度生成令牌,并将其放置到令牌桶中,可以将令牌桶想象成一个缓冲区(可以用队列这种数据结构来实现),当缓冲区填满的时候,新生成的令牌会被扔掉。
这里有两个变量很重要:第一个是生成令牌的速度,一般称为 rate 。比如,我们设定 rate=2 ,即每秒钟生成 2 个令牌,也就是每 1/2 秒生成一个令牌;
第二个是令牌桶的大小,一般称为 burst 。比如,我们设定 burst=10 ,即令牌桶最大只能容纳 10 个令牌。
有以下三种情形可能发生:
数据流的速率 等于 令牌流的速率。这种情况下,每个到来的数据包或者请求都能对应一个令牌,然后无延迟地通过队列;
数据流的速率 小于 令牌流的速率。通过队列的数据包或者请求只消耗了一部分令牌,剩下的令牌会在令牌桶里积累下来,直到桶被装满。剩下的令牌可以在突发请求的时候消耗掉。
数据流的速率 大于 令牌流的速率。这意味着桶里的令牌很快就会被耗尽。导致服务中断一段时间,如果数据包或者请求持续到来,将发生丢包或者拒绝响应。
处理机制
熔断:
熔断机制是应对雪崩效应的一种微服务链路保护机制。在微服务中,扇出的微服务不可用或者相应时间过长的话会对服务降级,进而熔断该服务节点,快速返回错误信息,释放资源。
而当检测到微服务响应正常后,则恢复调用。
隔离:
这种模式就像对系统请求按类型划分成一个个小岛的一样,当某个小岛被火烧光了,不会影响到其他的小岛。
例如可以对不同类型的请求使用线程池来资源隔离,每种类型的请求互不影响,如果一种类型的请求线程资源耗尽,则对后续的该类型请求直接返回,不再调用后续资源。
这种模式使用场景非常多,例如将一个服务拆开,对于重要的服务使用单独服务器来部署,再或者公司最近推广的多中心。
熔断设计
在熔断的设计主要参考了hystrix的做法。其中最重要的是三个模块:熔断请求判断算法、熔断恢复机制、熔断报警
(1)熔断请求判断机制算法:使用无锁循环队列计数,每个熔断器默认维护10个bucket,每1秒一个bucket,每个blucket记录请求的成功、失败、超时、拒绝的状态,默认错误超过50%且10秒内超过20个请求进行中断拦截。
(2)熔断恢复:对于被熔断的请求,每隔5s允许部分请求通过,若请求都是健康的(RT<250ms)则对请求健康恢复。
(3)熔断报警:对于熔断的请求打日志,异常请求超过某些设定则报警。
隔离设计
隔离的方式一般使用两种
(1)线程池隔离模式:使用一个线程池来存储当前的请求,线程池对请求作处理,设置任务返回处理超时时间,堆积的请求堆积入线程池队列。这种方式需要为每个依赖的服务申请线程池,有一定的资源消耗,好处是可以应对突发流量(流量洪峰来临时,处理不完可将数据存储到线程池队里慢慢处理)
(2)信号量隔离模式:使用一个原子计数器(或信号量)来记录当前有多少个线程在运行,请求来先判断计数器的数值,若超过设置的最大线程个数则丢弃改类型的新请求,若不超过则执行计数操作请求来计数器+1,请求返回计数器-1。这种方式是严格的控制线程且立即返回模式,无法应对突发流量(流量洪峰来临时,处理的线程超过数量,其他的请求会直接返回,不继续去请求依赖的服务)
服务降级与熔断的相关异同点:
相同点:
目的很一致,都是从可用性可靠性着想,为防止系统的整体缓慢甚至崩溃,采用的技术手段;
最终表现类似,对于两者来说,最终让用户体验到的是某些功能暂时不可达或不可用;
粒度一般都是服务级别,当然,业界也有不少更细粒度的做法,比如做到数据持久层(允许查询,不允许增删改);
自治性要求很高,熔断模式一般都是服务基于策略的自动触发,降级虽说可人工干预,但在微服务架构下,完全靠人显然不可能,开关预置、配置中心都是必要手段;
区别:
触发原因不太一样,服务熔断一般是某个服务(下游服务)故障引起,而服务降级一般是从整体负荷考虑;
管理目标的层次不太一样,熔断其实是一个框架级的处理,每个微服务都需要(无层级之分),而降级一般需要对业务有层级之分(比如降级一般是从最外围服务开始)
实现方式不太一样;服务降级具有代码侵入性(由控制器完成/或自动降级),熔断一般称为自我熔断。
基于Redis 实现限流
1、计数算法:
基于redis的incrby 加一和decrby 操作,来控制分布式系统中计数器。
2、令牌桶算法:
基于 Redis 的 list接口可以实现令牌桶令牌补充和令牌消耗操作。
参考博客:https://www.jianshu.com/p/c0937bf9849d
https://blog.csdn.net/llianlianpay/article/details/79768890