在之前的文章另类爬虫:从PDF文件中爬取表格数据中,我们知道如何利用Python的camelot模块,通过写Python程序来提取PDF中的表格数据。本文我们将学习如何用更便捷的工具从PDF中提取表格。
Excalibur是一个用来从PDF中提取表格数据的网页工具,而它正是以camelot为基础。该工具目前只支持文本类型的PDF,而不支持扫描后的PDF文档,关于其说明和使用文档可以参考网址: https://github.com/camelot-dev/excalibur 。
安装Excalibur
在安装Excalibur之前,需要事先安装ghostscript,具体的安装方式可以参考:https://camelot-py.readthedocs.io/en/master/user/install-deps.html 。不同系统安装ghostscript的方式不一样,以笔者的mac电脑为例,安装命令如下:
$ brew install tcl-tk ghostscript安装ghostscript完毕后,再通过pip安装Excalibur,命令如下:
$ pip3 install excalibur-py以上就是全部的安装准备工作了。
启动与使用Excalibur
运行下面的命令启动Excalibur:
$ excalibur initdb
$ excalibur webserver前一句命令是初始化数据库,后一句命令是运行server服务。在浏览器中输入: http://localhost:5050 ,即可使用该平台。
进入该PDF表格提取平台,首页如下:

笔者测试的PDF中含有以下表格:
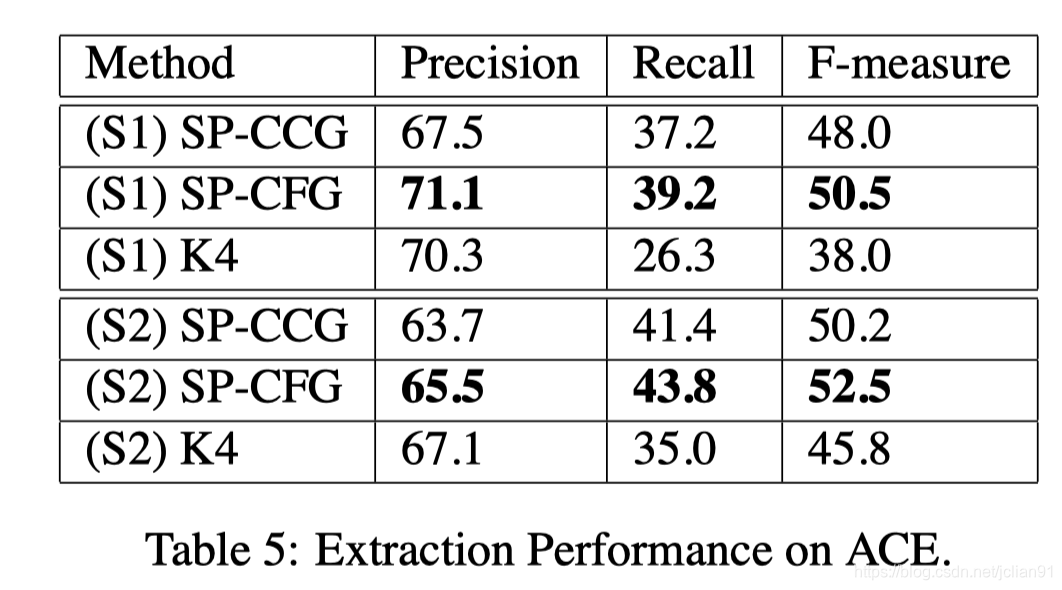
我们将该PDF文档上传至上述平台,点击“Upload PDF”按钮,再选择相应的PDF文档以及该表格所在的页码即可。PDF上传后,该表格所在的那一页如下图所示:
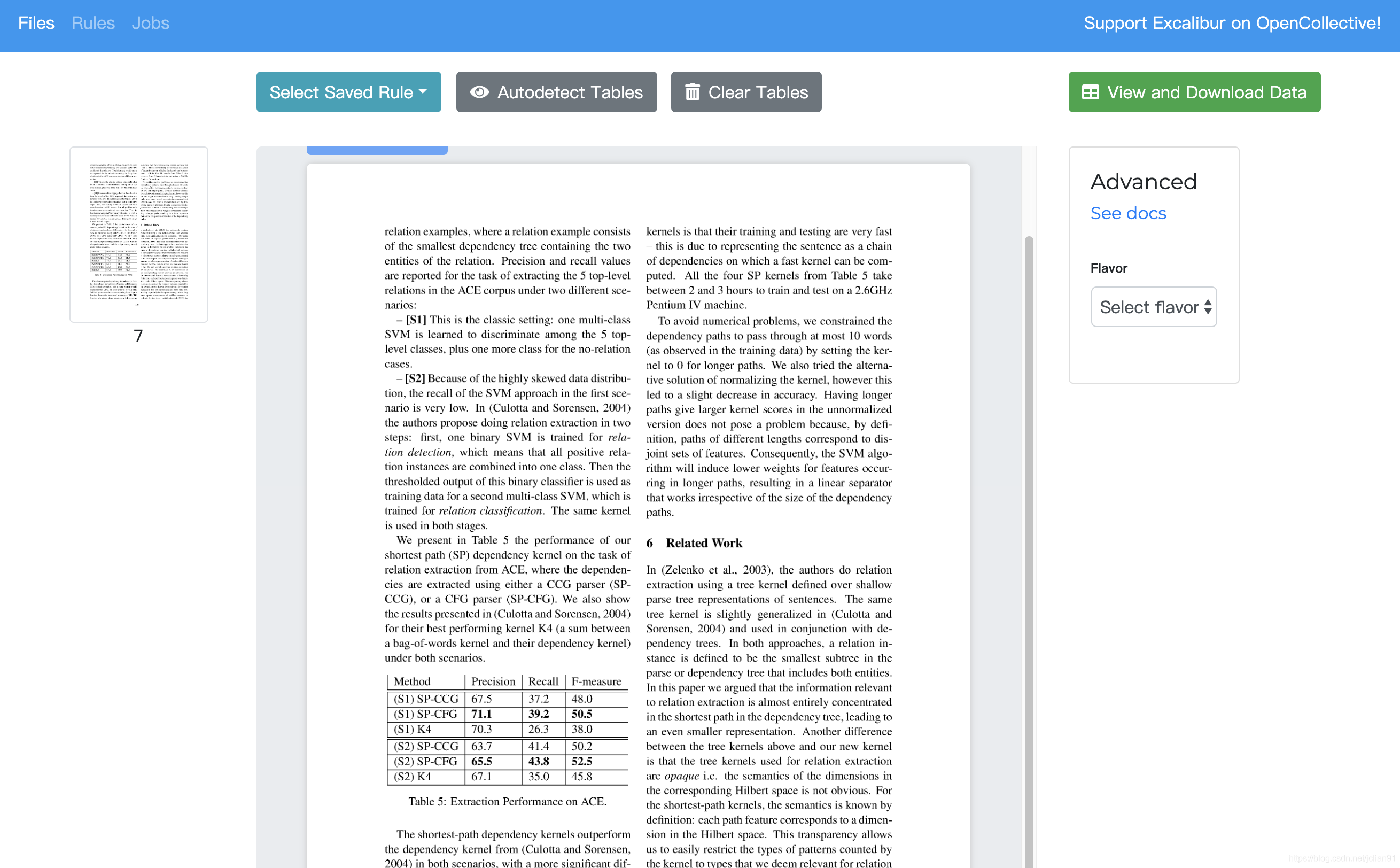
在右侧的Anvanced中的Flavor中选择“lattice”,并用鼠标框选出表格所在的区域,如下图:
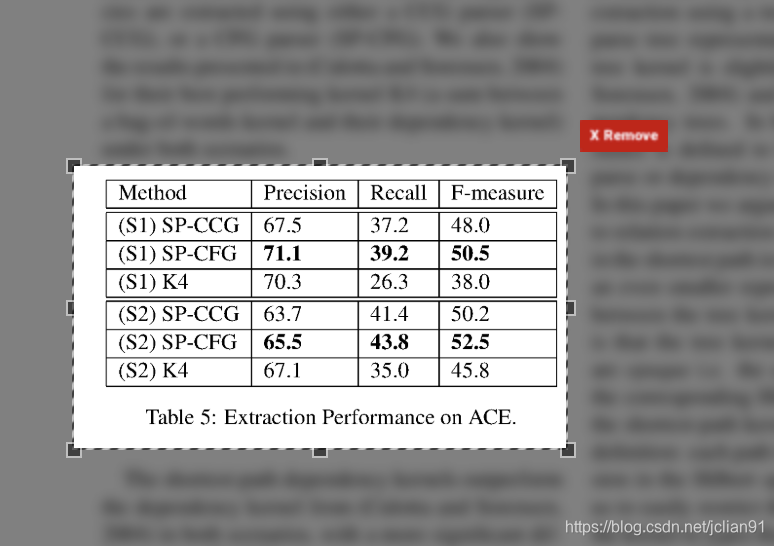
再点击“View and Download Data”按钮,就能得到从PDF解析表格后得到的数据了。截图如下:
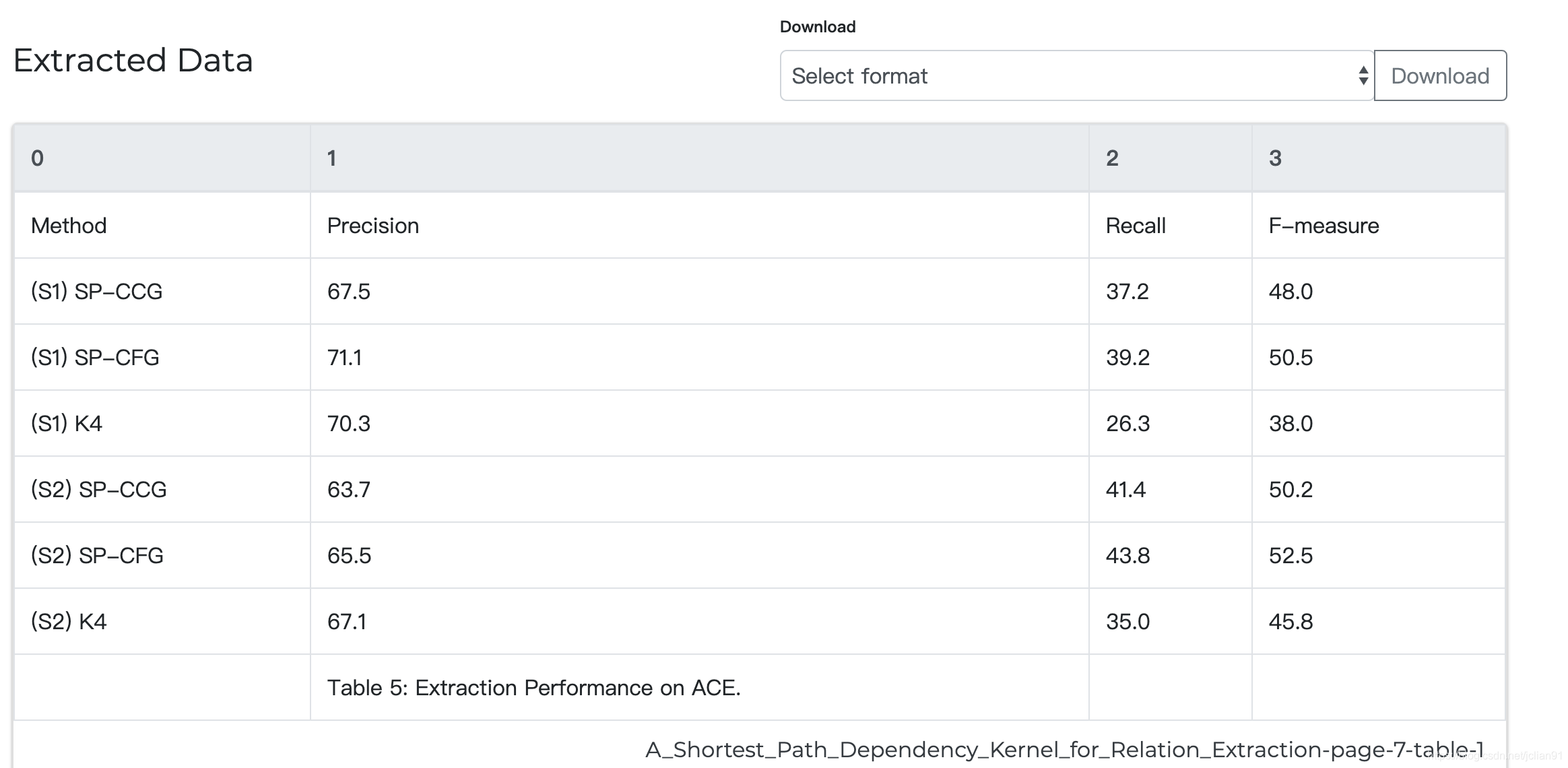
如果我们还想将这个表格解析后的结果保存为文件,则可以在Download旁的下拉框中选择一种保存的形式,并点击Download按钮。比如,笔者选择保存为csv文件,则下载后的文件如下:
"Method","Precision","Recall","F-measure"
"(S1) SP-CCG","67.5","37.2","48.0"
"(S1) SP-CFG","71.1","39.2","50.5"
"(S1) K4","70.3","26.3","38.0"
"(S2) SP-CCG","63.7","41.4","50.2"
"(S2) SP-CFG","65.5","43.8","52.5"
"(S2) K4","67.1","35.0","45.8"
"","Table 5: Extraction Performance on ACE.","",""我们可以发现,该表格解析后的结果还是相当漂亮的。
本次分享到此结束,感谢大家的阅读。
注意:本人现已开通微信公众号: Python爬虫与算法(微信号为:easy_web_scrape), 欢迎大家关注哦~~