一、索引是什么
索引,在MySQL中也叫“键(key)”,是存储引擎用于快速找到记录的一种数据结构。如果把数据库的一张表比作一本书,那索引则是这本书的目录,通过目录,我们能快速找到我们想要的主题所对应的页码。索引的作用即类似于书的目录,帮助我们快速定位到相关数据行的位置。
好的索引能使查询的性能提高几个数量级,而差的索引在大数据量的表中甚至会使性能极具下降。“最优”的索引有时比一个“好的”索引性能要好两个数量级。
二、索引有哪些类型
索引有很多种类型,可以为不同的场景提供更好的性能。在MySQL中,索引是在存储引擎层而非服务器层实现的,而不同的存储引擎的索引的工作方式并不一样,且不是所有的存储引擎都支持所有类型的索引。同时,值得一提的是,不同的存储引擎对同一类型的索引,其底层的实现一般是不同的。
MySQL支持以下几种类型的索引。
(1)B-Tree索引
(2)哈希索引
(3)空间数据索引(R-Tree)
(4)全文索引
(5)其他索引类别
下面我将一一展开进行介绍。
三、 B-Tree索引
(一)B-Tree索引只是一个统称术语
B-Tree索引是最常见的索引类型,它使用B-Tree数据结构来存储数据,大多数MySQL引擎都支持这种索引。(Archive引擎是一个例外:5.1之前Archive不支持任何索引,直到5.1才开始支持单个自增列AUTO_INCREMENT的索引。)
在MySQL中,“B-Tree”只是一个术语的统称,因为不同的存储引擎可能使用的是其他存储结构来实现这种索引,但仅仅只是命名为“B-Tree”。例如,NDB集群存储引擎内部实际上使用了T-Tree结构存储这种索引;InnoDB则使用的是B+Tree结构存储这种索引。只是它们都将其命名为“B-Tree”。
(二)B-Tree索引在不同引擎中的差异
不同的存储引擎使用B-Tree索引的方式也不同,性能也各有不同,各有优劣。下面拿MyISAM 和InnoDB进行对比。
表3-1 MyISAM和InnoDB中B-Tree的相关差异
|
|
MyISAM |
InnoDB |
| 存储方式 |
前缀压缩技术 |
按照原数据格式 |
| 引用方式 |
通过数据的物理位置引用被索引的行 |
根据主键引用被索引的行 |
(三)InnoDB的B-Tree技术实现是B+Tree
上面我们也提到,InnoDB的B-Tree索引从技术上来说实际上是B+Tree实现的,这种实现使得所有的值都是按照顺序存储的(所以很适合查找范围数据),并且每一个叶子页到根的距离相同。MyISAM使用的结构有所不同,但基本思想类似。
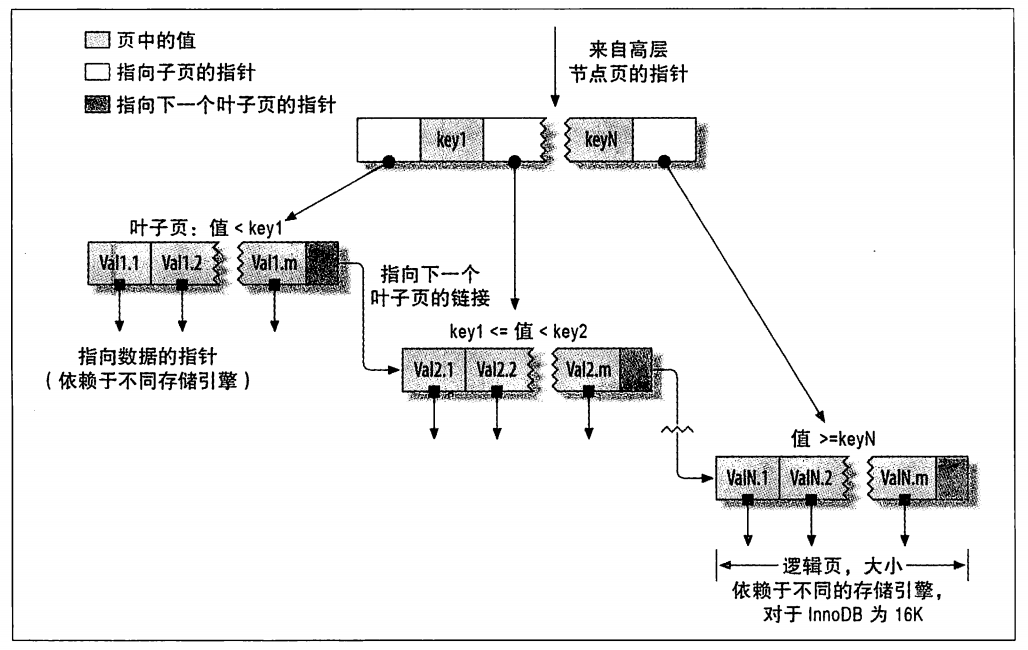
图3.1 建立在B-Tree结构上的索引(从技术上来说是B+Tree)
B-Tree索引能够加快访问数据的速度,靠的就是上面这种数据结构。它使得存储引擎不再需要进行全表扫描来获取所需数据,取而代之的是从索引的根节点开始搜索。
根节点中存放了指向子节点的指针,存储引擎根据这些指针向下层查找。通过比较节点页的值和要查找的值可以找到合适的指针进入下层子节点,这些指针实际上定义了子节点页中值的上限和下限。最终存储引擎要么能找到对应的值,要么该记录不存在。叶子节点页有相应的指针,但叶子节点的指针不是指向其他的节点页,而是指向被索引的数据(不同引擎的“指针”类型不同)。
这里值得一提的是,树的深度和表的大小直接相关,表的数据量越大,树的层数越多。
(四)创建一个多列索引
CREATE TABLE People ( last_name varchar(50) not null, first_name varchar(50) not null, dob date not null, gender enum(‘m’,‘f’) not null, key(last_name,first_name,dob) );
索引对多个值进行排序的依据是CREATE TABLE语句中定义索引时列的顺序。
(五)B-Tree索引支持的查询类型
MySQL的B-Tree索引适用于全键值、键值范围或键前缀查找,其中键前缀查找只适用于根据最左前缀的查找。前面所述的索引可细分为如下几种类型。
(1)全值匹配
全值匹配指的是和索引中的所有列进行匹配。
例如上面的People表的索引(last_name,first_name,dob)可以用于查找last_name=’Zeng’,first_name=’Chuang’,dob=’1996-01-01’的人。这就是使用了索引中的所有列进行匹配,即全值匹配。
(2)匹配最左前缀
可以只使用索引的第一个列进行匹配。
例如可以用于查找last_name=’Zeng’的人,即用于查找姓为Zeng的人,这里只使用了索引的最左列进行匹配,即匹配最左前缀。
(3)匹配列前缀
可以只匹配某一列的值的开头部分。
例如可以用于查找last_name LIKE ‘Z%’的人,即用于查找所有以Z开头的姓的人,这里只使用了索引最左列的前缀进行匹配,即匹配列前缀。
(4)匹配范围值
可以只适用索引的第一列查找符合某个范围内的数据。
例如可以用于查找last_name BETWEEN ‘Qiu’ AND ‘Zeng’的人,即用于查找姓在Qiu和Zeng之间的人,这里只使用了索引最左列的前缀进行范围匹配,即匹配范围值。
(5)精确匹配某一列并范围匹配另外一列
可以使第一列全匹配,第二列范围匹配。
例如可以用于查找last_name=’Zeng’ AND first_name LIKE ’C%’的人,即用于查找姓是Zeng,名字以C开头的人,这里使用了索引的最左列精确匹配,第二列进行范围匹配,即精确匹配某一列并范围匹配另外一列。
(6)只访问索引的查询
查询只需访问索引,而无须访问数据行。
例如select last_name, first_name where last_name=’Zeng’; 这里只查询索引所包含的last_name和first_name列,则无须读取数据行。
(六)B-Tree索引的限制
根据上面介绍的B-Tree索引支持的查询类型,我们可以知道,它同样会存在一些限制。
(1)只能按照索引的最左列开始查找。
例如People表中的索引无法用于查找first_name为’Chuang’的人,也无法查找某个特定生日的人,因为这两个列都不是最左数据列。
(2)只能按照索引最左列的最左前缀进行匹配。
例如People表中的索引无法查找last_name LIKE ‘%eng’的人,虽然last_name就是此索引的最左列,但MySQL索引无法查找以‘eng’结尾的last_name的记录。
(3)只能按照索引定义的顺序从左到右进行匹配,不能跳过索引中的列。
例如People表中的索引无法用于查找last_name=’Zeng’ AND bod=’1996-01-01’的人,因为MySQL无法跳过索引中的某一列而使用索引中最左列和排在末尾的列进行组合。如果不指定索引中中间的列,则MySQL只能使用索引的最左列,即第一列。
(4)如果查询中有某个列的范围查询,则其右边所有列都无法使用索引优化查找。
例如有这样一个查询:where last_name=’Zeng’ AND first_name LIKE ’C%’ AND dob=’1996-01-01’; 这个查询只能使用索引的前两列,因为这里LIKE是一个范围条件,则first_name后面的索引列都将失效。(优化点:尽量不要在索引列中使用LIKE等范围条件,改用多个等于条件来替代,保证后面的索引列能生效。)
阅读到这里,我们应该明白了索引列的顺序是多么的重要,上面的这些限制都和索引列的顺序有关。在性能优化时,可能需要使用相同的列但顺序不同的索引来满足不同类型的查询需求。
四、哈希索引
未完待续,欢迎持续关注。
参考文献
[1]Baron Scbwartz, Peter Zaitsev, Vadim Tkacbenko. 高性能MySQL[M].第三版.北京:电子工业出版社, 2013:141-146