卷积的目的是为了从输入中提取有用的特征。在图像处理中,有很多滤波器可以供我们选择。每一种滤波器帮助我们提取不同的特征。比如水平/垂直/对角线边缘等等。在CNN中,通过卷积提取不同的特征,滤波器的权重在训练期间自动学习。然后将所有提取到的特征“组合”以作出决定。
卷积的优势在于,权重共享和平移不变性。同时还考虑到了像素空间的关系,而这一点很有用,特别是在计算机视觉任务中,因为这些任务通常涉及识别具有空间关系的对象。(例如:狗的身体通常连接头部、四肢和尾部)。
单通道版本
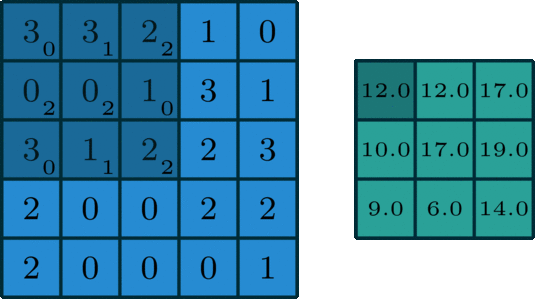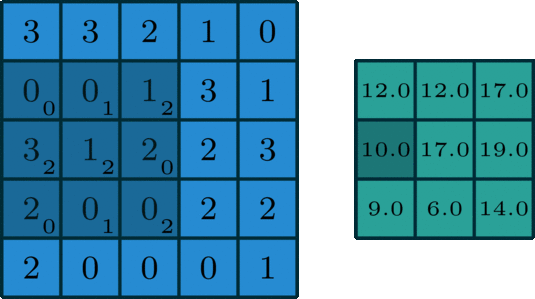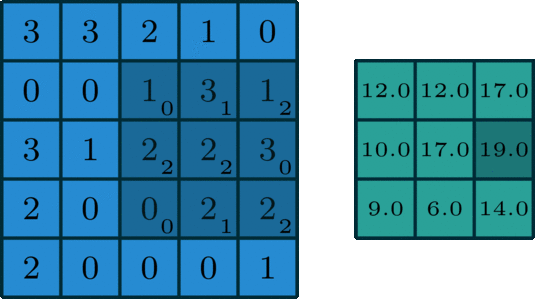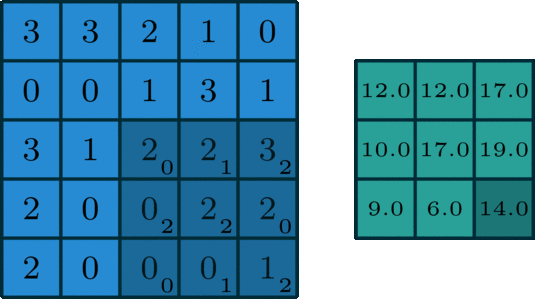
单个通道的卷积
在深度学习中,卷积是元素对元素的加法和乘法。对于具有一个通道的图像,卷积如上图所示。这里的滤波器是一个3x3的矩阵[[0,1,2],[2,2,0],[0,1,2]]。滤波器滑过输入,在每个位置完成一次卷积,每个滑动位置得到一个输出。(注意,在上面的例子中,stride=1, padding=0)
多通道版本

在很多应用中,我们需要处理多通道图片。最典型的例子就是RGB图像。

不同的通道强调原始图像的不同方面
另一个多通道数据的例子是CNN中的层。卷积网络通常由多个通道组成(通常为数百个通道)。每个通道描述前一层的不同方面。我们如何在不同深度的层之间进行转换?如何将深度为n的层转换为深度为m的下一层?
在描述这个过程之前,我们先介绍一些术语:layers(层)、channels(通道)、feature maps (特征图)、filters(滤波器)、kernels(卷积核)。从层次结构来看,层和滤波器的概念处于同一水平,而通道和卷积核在下一级结构中。通道和特征图是同一个事情。一层可以有多个通道(或者说特征图)。如果输入的是一个RGB图像,那么就会有3个通道。“channel"通常被用来描述"layer"的结构。相似的,"kernel"是被用来描述”filter”的结构。
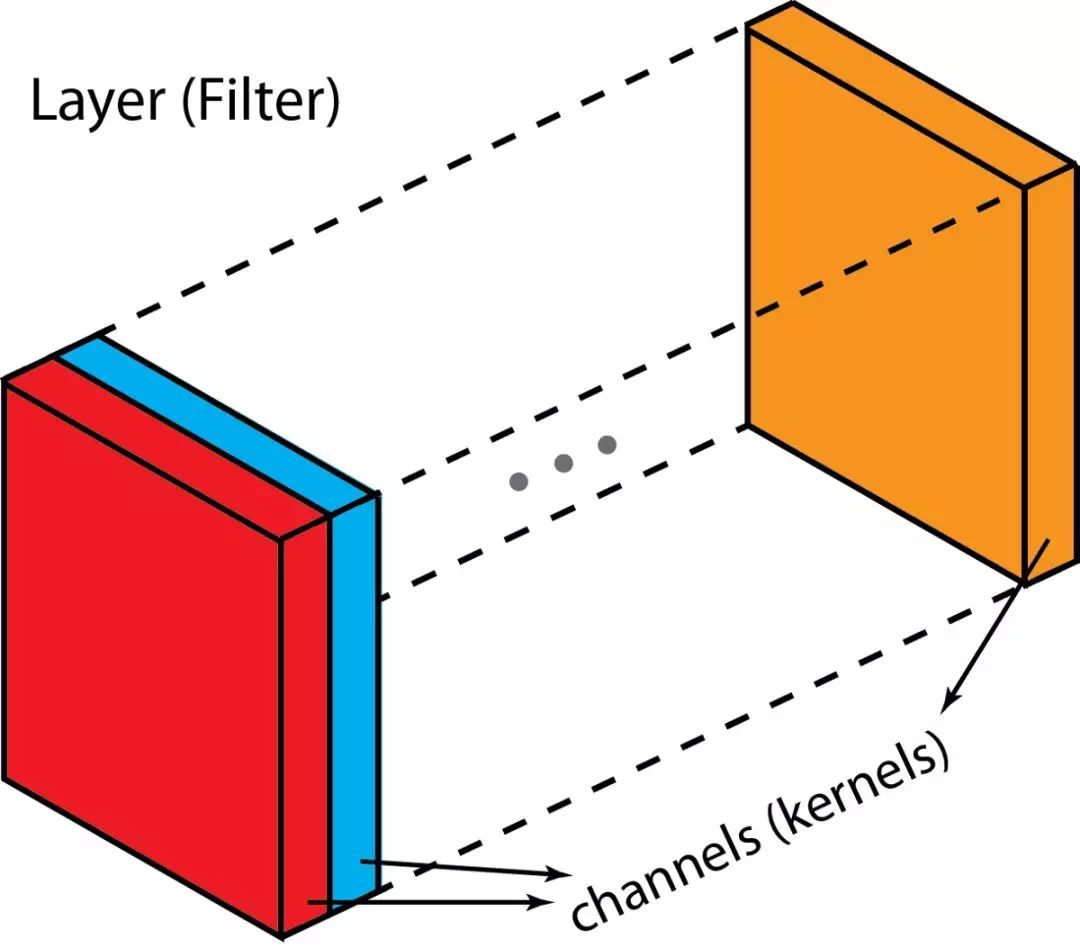
filter和kernel之间的不同很微妙。很多时候,它们可以互换,所以这可能造成我们的混淆。那它们之间的不同在于哪里呢?一个"kernel"更倾向于是2D的权重矩阵。而'filter"则是指多个Kernel堆叠的3D结构。如果是一个2D的filter,那么两者就是一样的。但是一个3Dfilter, 在大多数深度学习的卷积中,它是包含kernel的。每个卷积核都是独一无二的,主要在于强调输入通道的不同方面。
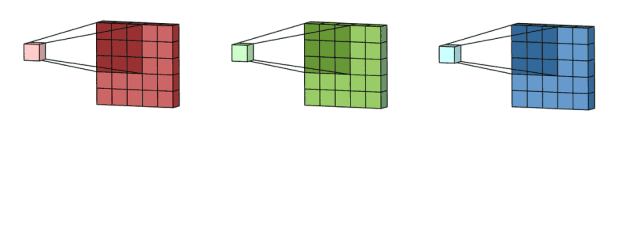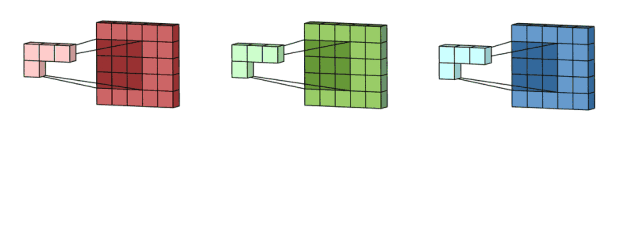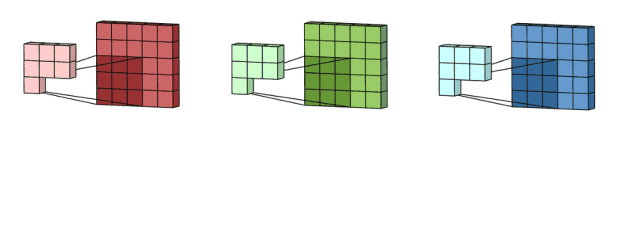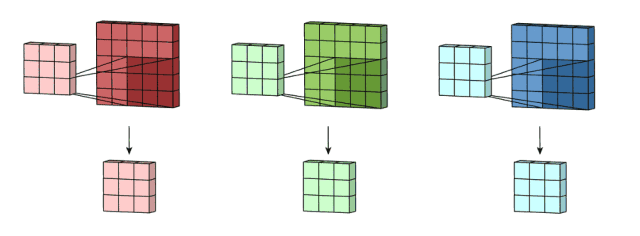
讲了概念,下面我们继续讲解多通道卷积。将每个内核应用到前一层的输入通道上以生成一个输出通道。这是一个卷积核过程,我们为所有Kernel重复这样的过程生成多个通道。然后把这些通道加在一起形成单个输出通道。下图:
输入是一个5x5x3的矩阵,有三个通道。filter是一个3x3x3的矩阵。首先,filter中的每个卷积核分别应用于输入层的三个通道。执行三次卷积,产生3个3x3的通道。