本文转自 https://blog.csdn.net/Enmotech/article/details/80045576
作者 | 罗贵林: 云和恩墨技术工程师,具有8年以上的 Oracle 数据库工作经验,曾任职于大型的国家电信、省级财政、省级公安的维护,性能调优等。精通 Oracle 数据库管理,调优,问题诊断。擅长 SQL 调优,Oracle Rac 等维护,管理。
1 跨平台跨版本迁移方案对比
针对跨平台跨版本的迁移,主要有以下三种方式:数据泵、GoldenGate / DSG、XTTS,针对停机时间、复杂度、实施准备时间,做了以下列表比对:
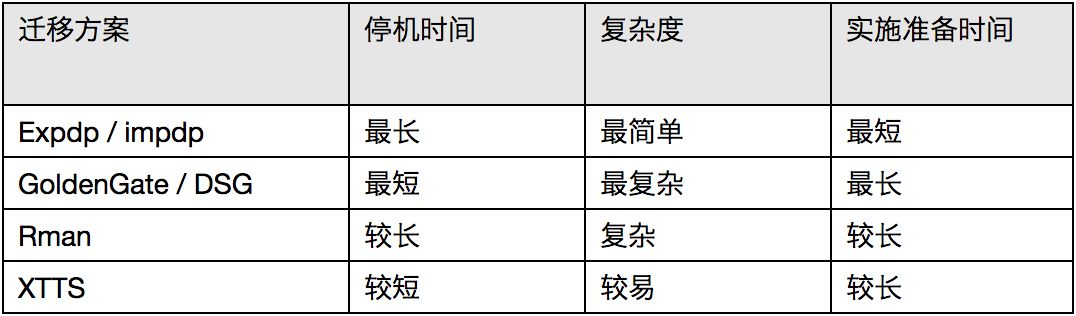
客户的需求都是最短停机时间,最少数据丢失。对于 GoldenGate / DSG 来说它的停机时间是最短的,但实施准备时间最长,复杂度最高;数据泵是停机时间最长,实施准备时间最短;XTTS 是介于这两者之间的,同时满足客户提出的短停机时间、低实施成本需求。
数据泵比较适用的场景就是数据量比较小、数据大概在 5T 以下,使用数据泵会方便很多。
GoldenGate / DSG 比较适用大数据量的数据分发,灾备库建设。
XTTS 是单次数据库跨平台、跨版本迁移利器,相同平台,相同版本迁移首选 rman。
在 Oracle11g 中的 RMAN 支持不同操作系统和不同 DB 版本之间的使用,关于 RMAN 的兼容性。如下图示:

注意以下操作系统的组合,这里假设 DB version 相同:
(1)For Oracle Database 10g Release 2 and above releases: --在 Oracle 10gR2 之后的版本,支持如下操作系统之间的 RMAN 操作: Solaris x86-64 <-> Linux x86-64 HP-PA <-> HP-IA Windows IA (64-bit) / Windows (64-bitItanium) <-> Windows 64-bit for AMD / Windows (x86-64) (2)For Oracle Database 11g Release 1 and above releases (requires minimum 11.1 compatible setting): --在 Oracle 11gR1 之后的版本,支持如下操作系统之间的 RMAN 操作,当然这里也包含第一条里提到的 10gR2 后的组合。 Linux <-> Windows (3)For Oracle Database 11g Release 2(11.2.0.2) and above releases: Solaris SPARC (64-bit) <-> AIX(64-bit) - Note: this platform combination is currently not supported due to Bug 12702521 --在 11gR2 中,因为 Bug 12702521 的存在,Solaris SPARC (64-bit) <-> AIX (64-bit) 这2个版本之间不能进行 RMAN 操作。
XTTS 同样须遵循 Oracle 升级路线:
Oracle 9i/10g/11g 数据库升级路线图(upgrade roadmap)

2 XTTS 各版本功能对比
XTTS (Cross Platform Transportable Tablespaces) 跨平台迁移表空间,是 Oracle 自10g 推出的一个用来移动单个表空间数据以及创建一个完整的数据库从一个平台移动到另一个平台的迁移备份方法。它是 Oracle 8i 开始就引入的一种基于表空间传输的物理迁移方法,命名为 TTS,不过 8i 的表空间迁移仅支持相同平台、相同块大小之间的表空间传输,从 Oracle 9i 开始,TTS 开始支持同平台中,不同块大小的表空间传输,这个时候很多数据库管理员就注意到了 TTS 在实际工作中的应用,不过由于每次移动表空间都需要停机、停业务,而 9i 的 TTS 只能在相同平台之间进行数据移动,相比 Oracle RMAN 本身的快捷方便,更多人更愿意选择使用 RMAN 进行数据备份、数据移动,基于 TTS 的这些缺点,Oracle 10g 时代引入了跨平台的表空间传输方案 XTTS,标志着第一代 XTTS 的诞生。
可以理解为 TTS 就是传输表空间,把表空间传输出去,数据从一个库传输到另外一个库,不支持增量备份,而 XTTS 是在 TTS 基础上做了一些更新,支持了跨平台,支持增量备份。
XTTS 各版本的功能比对如下,表一:XTTS 各版本功能比对表
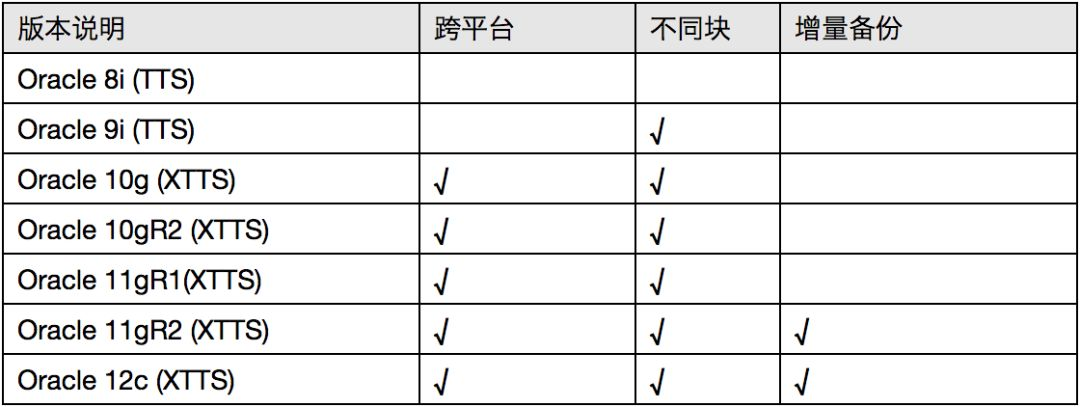
在 Oracle11gR2(推荐使用 11.2.0.4 及之后版本)以后,Oracle 推出了通过前滚数据文件,拷贝数据后再进行多次增量备份的 XTTS 来完成迁移过程,在这个过程中通过开启块跟踪特性,根据 SCN 号来执行一系列的增量备份,并且通过对块跟踪文件的扫描,来完成增量数据的增量备份应用,最后在通过一定的停机时间,在源库 read only 的状态下进行最后一次增量备份转换应用,使得整个迁移过程的停机时间同源库数据块的变化率成正比。这样大大的缩短了停机时间。
3 XTTS 前置条件检查
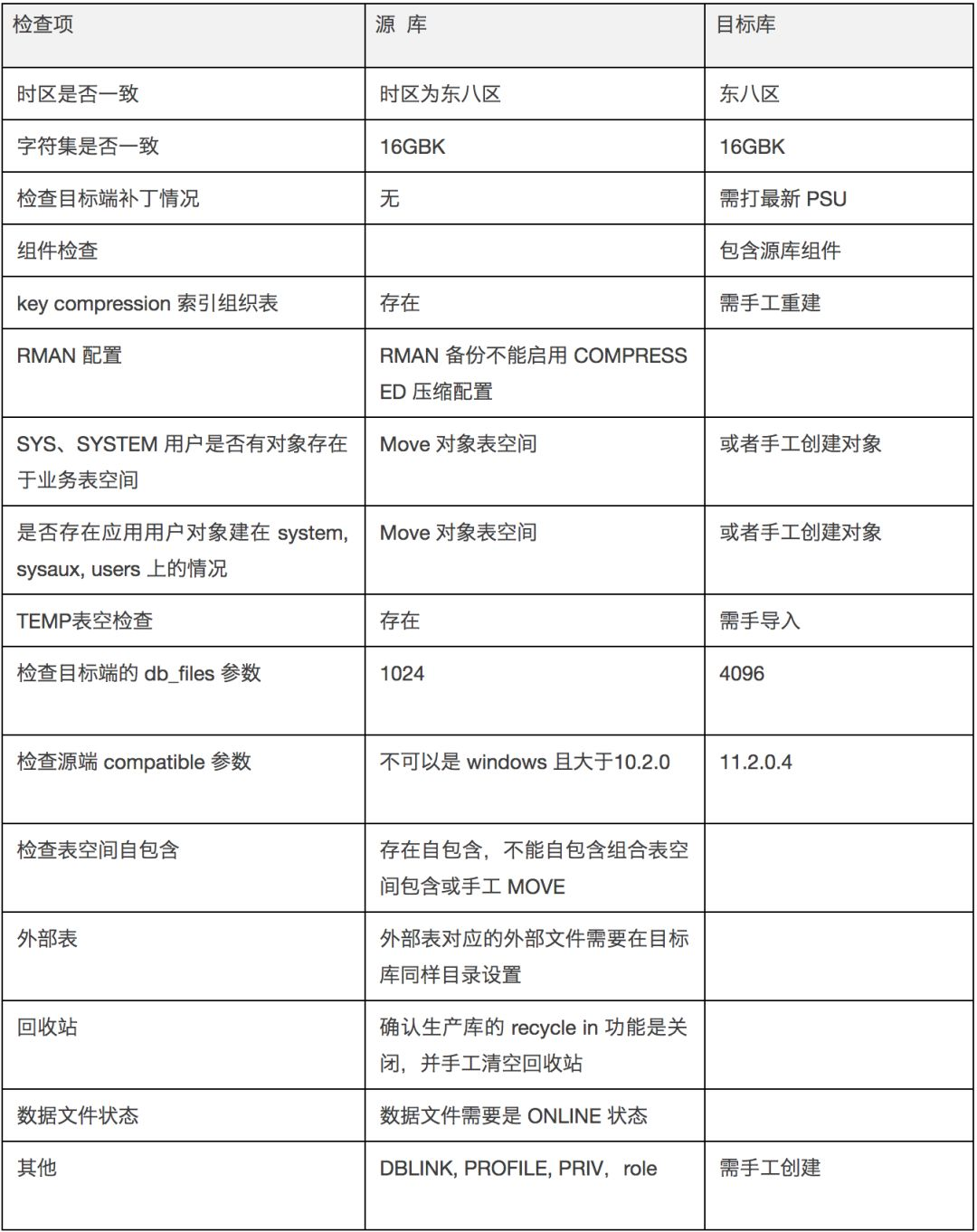
使用 XTTS 进行数据迁移需要具备的哪些前置条件?

可列出如下表格进行详细对比:
说明:
- 如果源端空间不够可以采用 NFS 磁盘挂载的方式,即将 Linux 的 NFS 文件系统挂载到中间环境(AIX 小机)的方式。
- XTTS 基于 RMAN 备份的方法,对于空间需求要求较高。
- 目标端新环境,提前安装并部署好 Oracle+ASM 环境,同时创建与现有生产库字符集一致的数据库。
4 XTTS 三种迁移方式
采用 XTTS 迁移方式,具备跨平台字序转换和全量初始化加增量 merge 的功能,非常适用于异构 OS 跨平台迁移,成为数据库实施人员中公认的大数据量跨平台迁移的最佳选择。
传统的 TTS 传输表空间要求数据由源端到目标端传输的整个过程中,表空间必须置于 read only 模式,严重影响业务可用性。XTTS 方式可以在业务正常运行的情况下,进行物理全量初始化,增量 block 备份,数据高低字节序转码,增量 block 应用,保持目标端与源端数据的同步,整个过程不影响源端数据库使用。在最后的增量 block 应用完毕后,利用停机窗口进行数据库切换,显著地减少了停机时间。
XTTS 技术主要通过 DBMS_FILE_TRANSFER、RMAN 备份、手工 XTTS 迁移三种方式来进行数据库迁移:
4.1 方式一:dbms_file_transfer
DBMS_FILE_TRANSFER 包是 Oracle 提供的一个用于复制二进制数据库文件或在数据库之间传输二进制文件的程序包,在 XTTS 迁移中,利用不同的参数进行数据文件传输转换完成迁移。
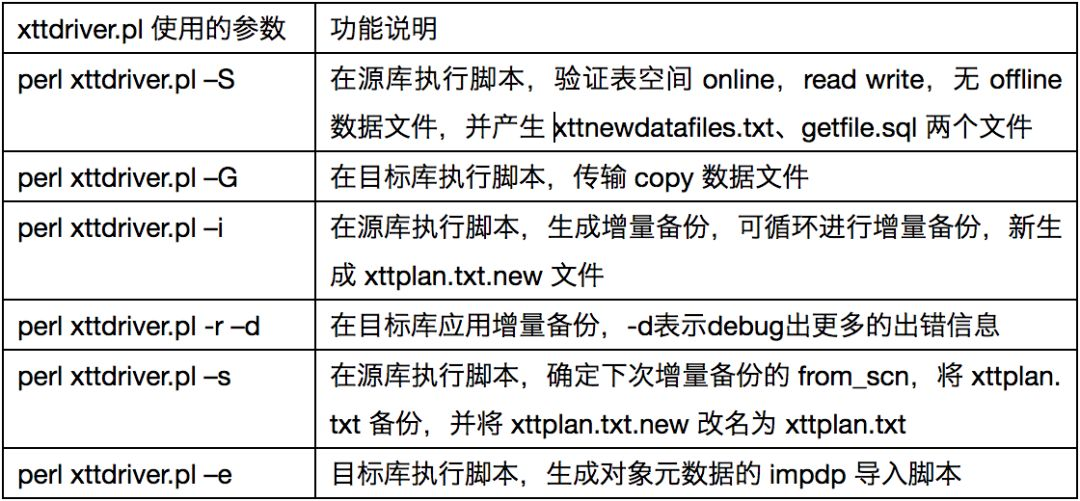
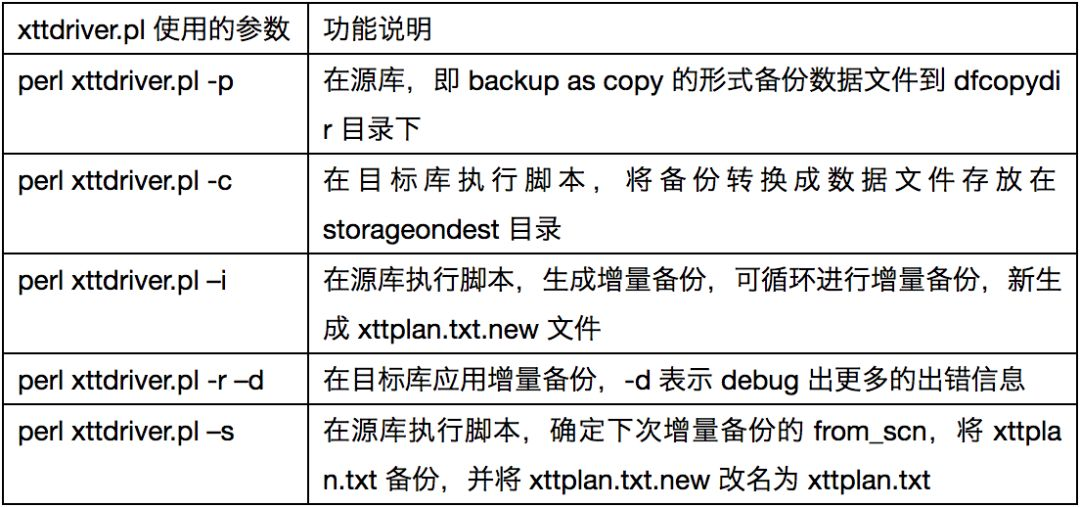
DBMS_FILE_TRANSFER 方式主要使用了 xttdriver.pl 脚本的以下几个参数:
4.2 方式二:RMAN Backup
RMAN Backup 方式是基于 RMAN 备份原理,通过使用 rman-xttconvert_2.0 包提供的参数,对数据库进行基于表空间的备份,将备份生产的备份集写到本地或者 NFS 盘上,然后在通过 rman-xttconvert_2.0 包中包含的不同平台之间数据文件格式转换的包对进行数据文件格式转换,最后通过记录的表空间 的FILE_ID 号与生产元数据的导入来完成。
RMAN Backup 方式主要使用了 xttdriver.pl 脚本的以下几个参数:
4.3 方式三:手工 XTTS 迁移
Oracle 提供的封装 perl 脚本仅支持目标系统 LINUX,而通过手工 XTTS 迁移的方式可以支持目标系统是 AIX、HP、SOLARIS 等 UNIX 系统,主要有如下几个阶段:
1)rman copy
rman target / <<eof
run{
allocate channel c1 type disk;
allocate channel c2 type disk;
backup as copy datafile 18,19,20,21,22........ format '/dump1/enmo/copy/enmo_%U';
release channel c1;
release channel c2;
}
EOF
</eof
2) 数据文件格式转换
convert from platform 'HP-UX IA (64-bit)' datafile '/dump1/ccm/vvstart_tabs.dbf' format '+FLASHDATA/ORCL/DATAFILE/vvstart_new_01.dbf';
3) 增量备份
set until scn=1850 backup incremental from scn 1000 datafile 18,19,20,21,22...... format '/dump1/enmo/incr/copy_%d_%T_%U';3;
4) 增量转换和应用
增量转换: sys.dbms_backup_restore.backupBackupPiece(bpname => '/dump1/enmo/incr/copy_ORCL_20160707_78ra40o7_1_1', fname => '/dump1/enmo/incr/copy_ORCL_20160707_78ra40o7_1_1_conv',handle => handle,media=> media, comment=> comment, concur=> concur,recid=> recid,stamp => stamp, check_logical => FALSE,copyno=> 1, deffmt=> 0, copy_recid=> 0,copy_stamp => 0,npieces=> 1,dest=> 0,pltfrmfr=> 4); 增量应用: sys.dbms_backup_restore.restoreBackupPiece(done => done, params => null, outhandle => outhandle,outtag => outtag, failover => failover);
三种方式的目标端数据库版本均需要为 11.2.0.4 版本或者以上,如果在使用过程中,目标库的版本是 11.2.0.3 或者更低,那么需要创建一个单独的 11.2.0.4 版本数据库作为中间库来在目标端进行数据文件的格式转换,而使用 DBMS_FILE_TRANSFER 包目标端的数据库版本必须是 11.2.0.4。
5 XTTS 初始参数说明
XTTS 是基于一组 rman-xttconvert_2.0 的脚本文件包来实现跨平台的数据迁移,主要包含 Perl script xttdriver 和 xttdriver Perl 脚本。Perl script xttdriver.pl 是备份、转换、应用的执行脚本,xtt.properties 是属性文件,其中包含 XTTS 配置的路径、参数。
rman-xttconvert_2.0 包参数说明如下表:

6 XTTS 迁移步骤(使用 RMAN 备份方法)
主要有以下步骤:
1)初始化参数设置;
2)将源端数据文件传输到目标系统;
3)转换数据文件为目标系统的字节序;
4)在源端创建增量备份,并传输到目标端;
5)在目标端恢复增量备份;
6)重复多次操作4和5步骤;
7)将源端数据库表空间设置为 READ ONLY 模式;
8)最后一次执行4和5步骤;
9)在源端导出元数据,并在目标端导入;
10)将目标端的数据库表空间设置为 READ WRITE;
11)数据验证。
6.1 XTTS 迁移准备阶段
6.1.1 生产库打开块跟踪特性
如果源库是 11g,需要先禁用延时段特性 不然 xtts 不会将空表导入目标库。
alter system set deferred_segment_creation=false sid='*' scope=spfile;
首先在生产库上打开块跟踪功能。
alter database enable block change tracking using file '/home/oracle/xtts/block_change_tracking.log';
6.1.2 传输表空间前自包含检查
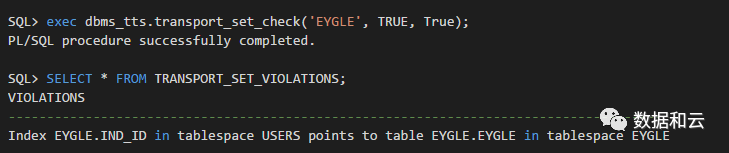
首先对表空间做自包含检查,检查出 Index 存在自包含问题,需要重建或者最后创建:
SQL> execute dbms_tts.transport_set_check(‘DATATBS ’,true); SQL> select * from transport_set_violations;
XXXX 创建在 USERS 表空间,需要提前迁移至 DATATBS 表空间。
Drop index XXXX;
CREATE INDEX XXXX ON "LUOKLE"."BI_LUOKLEINSTRUCTION" ("SENDTIME", "STATUS", "RECLUOKLE", "CREATORORGID", "CREATETIME") TABLESPACE DATATBS parallel 8;
Alter index XXXX noparallel;
由于 XTTS 最后导入元数据时候不支持临时表,所以需要提前查出系统临时表信息。
select dbms_metadata.get_ddl('TABLE',TABLE_NAME,owner) from dba_tables where TEMPORARY='Y' and owner=XXX;
需要手工创建的临时表有X个,以下脚本导入元数据之后手工执行。
CREATE GLOBAL TEMPORARY TABLE XXX
( "_ID" NUMBER,
"STATUS" CHAR(1)
) ON COMMIT PRESERVE ROWS ;
在表空间传输的中,要求表空间集为自包含的,自包含表示用于传输的内部表空间集没有引用指向外部表空间集。自包含分为两种:一般自包含表空间集和完全(严格)自包含表空间集。
常见的以下情况是违反自包含原则的:
- 索引在内部表空间集,而表在外部表空间集(相反地,如果表在内部表空间集,而索引在外部表空间集,则不违反自包含原则);
- 分区表一部分区在内部表空间集,一部分在外部表空间集(对于分区表,要么全部包含在内部表空间集中,要么全不包含);
- 如果在传输表空间时同时传输约束,则对于引用完整性约束,约束指向的表在外部表空间集,则违反自包含约束;如果不传输约束,则与约束指向无关;
- 表在内部表空间集,而 lob 列在外部表空间集,则违反自包含约束。
通常可以通过系统包 DBMS_TTS 来检查表空间是否自包含,验证可以以两种方式执行:非严格方式和严格方式。
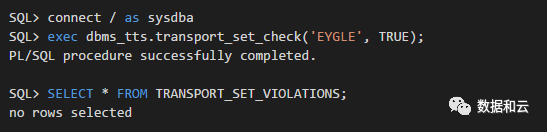
以下是一个简单的验证过程,假定在 eygle 表空间存在一个表 eygle,其上存在索引存储在 USERS 表空间:
SQL> create table eygle as select rownum id ,username from dba_users; SQL> create index ind_id on eygle(id) tablespace users;
以SYS用户执行非严格自包含检查(full_check=false):
执行严格自包含检查(full_check=true):
反过来对于 USERS 表空间来说,非严格检查也是无法通过的:
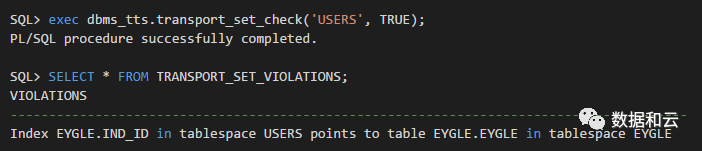
但是可以对多个表空间同时传输,则一些自包含问题就可以得到解决:

6.1.3 目标端创建数据库并修改部分参数
在目标环境需要提前安装好 GI 和 Oracle 软件,并创建监听、拷贝生产环境的 TNS 和新数据库,并修改部分数据库参数:
create directory xtts_dir as 'home/oracle/xtts/'; grant read,write on directory xtts3 to public;
调整以下参数:
alter system set "_optimizer_adaptive_cursor_sharing"=false sid='*' scope=spfile; alter system set "_optimizer_extended_cursor_sharing"=none sid='*' scope=spfile; alter system set "_optimizer_extended_cursor_sharing_rel"=none sid='*' scope=spfile; alter system set "_optimizer_use_feedback"=false sid ='*' scope=spfile; alter system set deferred_segment_creation=false sid='*' scope=spfile; alter system set event='28401 trace name context forever,level 1' sid='*' scope=spfile; alter system set resource_limit=true sid='*' scope=spfile; alter system set resource_manager_plan='force:' sid='*' scope=spfile; alter system set "_undo_autotune"=false sid='*' scope=spfile; alter system set "_optimizer_null_aware_antijoin"=false sid ='*' scope=spfile; alter system set "_px_use_large_pool"=true sid ='*' scope=spfile; alter system set audit_trail=none sid ='*' scope=spfile; alter system set "_partition_large_extents"=false sid='*' scope=spfile; alter system set "_index_partition_large_extents"= false sid='*' scope=spfile; alter system set "_use_adaptive_log_file_sync"=false sid ='*' scope=spfile; alter system set disk_asynch_io=true sid ='*' scope=spfile; alter system set db_files=2000 scope=spfile; alter profile "DEFAULT" limit PASSWORD_GRACE_TIME UNLIMITED; alter profile "DEFAULT" limit PASSWORD_LIFE_TIME UNLIMITED; alter profile "DEFAULT" limit PASSWORD_LOCK_TIME UNLIMITED; alter profile "DEFAULT" limit FAILED_LOGIN_ATTEMPTS UNLIMITED; exec dbms_scheduler.disable( 'ORACLE_OCM.MGMT_CONFIG_JOB' ); exec dbms_scheduler.disable( 'ORACLE_OCM.MGMT_STATS_CONFIG_JOB' ); BEGIN DBMS_AUTO_TASK_ADMIN.DISABLE( client_name => 'auto space advisor', operation => NULL, window_name => NULL); END; / BEGIN DBMS_AUTO_TASK_ADMIN.DISABLE( client_name => 'sql tuning advisor', operation => NULL, window_name => NULL); END; /
6.1.4 源端保留用户信息和权限
源端保留用户信息和权限:
spool create_user_LUOKLE.sql
select 'create user '||username||' identified by values '||''''||password||''''||';' from dba_users where default_tablespace in('TEST');
spool off
角色权限的语句:
spool grant_role_priv_LUOKLE.sql
select 'grant '||GRANTED_ROLE||' to '||grantee||';' from dba_role_privs where grantee in(select username from dba_users where default_tablespace in('TEST'));
spool off
sys 权限的赋权语句:
spool grant_sys_priv_LUOKLE.sql
select 'grant '||privilege||' to '||grantee||';' from dba_sys_privs where grantee in(select username from dba_users where default_tablespace in('TEST'));
spool off
对表空间的配额权限语句:
spool unlimited_tablespace_LUOKLE.sql
select 'alter user '||username||' quota unlimited on DATATBS ||';' from dba_users where default_tablespace in('TEST');
spool off
附:若后期存在用户与其他非本用户的对象权限问题,如 Schema A 对 Schema B 上表的访问和操作等权限,可以使用以下语句在源库检索出权限,并在目标端数据库进行赋权即可:
set line 200
set pages 0
spool grant_tab_priv.sql
select 'grant ' || privilege || ' on ' || owner || '.' || table_name || ' to ' || grantee || ';'
from dba_tab_privs
where owner in (select username from dba_users where default_tablespace in('TEST'))
or grantee in (select username from dba_users where default_tablespace in('TEST''))
and privilege in('SELECT','DELETE','UPDATE','INSERT') and grantable='NO'
union
select 'grant ' || privilege || ' on ' || owner || '.' || table_name || ' to ' || grantee || ' with grant option;'
from dba_tab_privs
where owner in (select username from dba_users where default_tablespace in('TEST'))
or grantee in (select username from dba_users where default_tablespace in('TEST'))
and privilege in('SELECT','DELETE','UPDATE','INSERT') and grantable='YES';
spool off
6.2 XTTS 迁移初始化阶段
6.2.1 源端更改配置文件 xtt.properties
更改以下参数:
tablespaces=TEST,TEST_INDEX platformid=13 dfcopydir=/home/oracle/xtts/bak backupformat=/home/oracle/xtts/bakincr stageondest=/home/oracle/xtts/bak storageondest=+DATA/oracle11gasm/datafile backupondest=+DATA/oracle11gasm/datafile asm_home=/u01/app/grid/product/11.2.0/grid asm_sid=+ASM parallel=2 rollparallel=2 getfileparallel=2
更改配置之后,将整个 rman-xttconvert 目录传输至目标端。
6.2.2 源端进行迁移初始化
在源端进行初始化,即 backup as copy 的形式备份数据文件到 /aix_xtts/bak 下。
more full_backup.sh export TMPDIR=/aix_xtts perl xttdriver.pl -p
执行脚本进行全备:
nohup sh ./full_back.sh >full_back.log &
初始化之后产生 xttplan.txt rmanconvert.cmd;
xttplan.txt 记录了当前 SCN,也就是下次需要增量的开始 SCN;
rmanconvert.cmd 记录了文件转换的名字。
[oracle@oracle11gasm xtts]$ cat rmanconvert.cmd host 'echo ts::TEST'; convert from platform 'Linux x86 64-bit' datafile '/home/oracle/xtts/bak/TEST_5.tf' format '+DATA/oracle11gasm/datafile/%N_%f.xtf' parallelism 2; host 'echo ts::TEST_INDEX'; convert from platform 'Linux x86 64-bit' datafile '/home/oracle/xtts/bak/TEST_INDEX_6.tf' format '+DATA/oracle11gasm/datafile/%N_%f.xtf' parallelism 2;
6.2.3 转换初始化文件至 ASM 中
由于使用了 NFS 不需要再次传输 /aix_xtts/bak,修改 xtt.properties 文件:
修改备库 xtt.properties 文件:
增加:
asm_home=/oracle/app/grid/11.2.0.4 asm_sid=+ASM
该步骤中,我们需要在 Linux 目标端主机上完成,进行全库的数据文件转换,通过脚本直接将数据文件转换到 ASM DISKGROUP 中。
注意:该转换步骤中,我们只需要转换我们需要传输的业务表空间即可,也就是 DATATBS 。
如下是全库的转换脚本:
more convert.sh export XTTDEBUG=1 export TMPDIR=/aix_xtts perl xttdriver.pl -c
执行脚本进行转换:
nohup sh ./convert.sh >convert.log &
并且在目标的 storageondest 目录下会生成经转换后的数据文件拷贝。
日志如下:
-------------------------------------------------------------------- Parsing properties -------------------------------------------------------------------- -------------------------------------------------------------------- Done parsing properties -------------------------------------------------------------------- -------------------------------------------------------------------- Checking properties -------------------------------------------------------------------- -------------------------------------------------------------------- Done checking properties -------------------------------------------------------------------- -------------------------------------------------------------------- Performing convert -------------------------------------------------------------------- -------------------------------------------------------------------- Converted datafiles listed in: /xtts/xttnewdatafiles.txt
转换成功之后会生成 xttnewdatafiles.txt,该文件为数据文件在 ASM MAP 关系表,即 file_id 和数据文件名对应表,增量恢复需要。
如果没有产生需要手工创建,命令格式如下:
[oracle@oracle11gasm xtts]$ cat xttnewdatafiles.txt ::TEST 5,+DATA/oracle11gasm/datafile/test_5.xtf ::TEST_INDEX 6,+DATA/oracle11gasm/datafile/test_index_6.xtf
6.3 XTTS 迁移增量备份恢复
6.3.1 生产库进行第一次增量备份
由于生产库每天的归档极大,因此需要进行多次增量备份,并将增量备份传输到目标端 Linux 的新环境,并应用增量备份,其中初始化产生的 xttplan.txt 文件记录了增量 SCN 起始位置,这里我们只需要对需要传输的表空间进行增量备份即可:
more do_incr.sh export TMPDIR=/aix_xtts perl xttdriver.pl –i
执行脚本进行增量备份:
nohup sh ./do_incr.sh >do_incr_1.log &
backup incremental from scn 13827379581 第一次增量备份开始的 SCN,由 -p 初始化产生;
增量8天的数据时间花费100分钟,产生增量文件40G。
[root@ecmsdb01plk xtts]# cat xttplan.txt.new --增量备份生成新的 xttplan.txt.new 文件 DATATBS ::::14000344337 --下一次增量备份开始的 SCN [oracle@oracle11g bakincr]$ pwd /home/oracle/xtts/bakincr [oracle@oracle11g bakincr]$ ls -lrt -rw-r----- 1 oracle oinstall 49152 Apr 1 08:00 0gsv7s0v_1_1 -rw-r----- 1 oracle oinstall 49152 Apr 1 08:00 0hsv7s10_1_1
第一次增量备份之后产生的2个配置文件为 tsbkupmap.txt 和 incrbackups.txt,这两个为增量与数据文件对应关系配置,在做增量恢复时候需要用到。
[oracle@oracle11gasm xtts]$ cat tsbkupmap.txt TEST_INDEX::6:::1=0hsv7s10_1_1 TEST::5:::1=0gsv7s0v_1_1 [oracle@oracle11gasm xtts]$ cat incrbackups.txt /home/oracle/xtts/bakincr/0hsv7s10_1_1 /home/oracle/xtts/bakincr/0gsv7s0v_1_1
通过 FTP 传输增量文件至目标 LINUX 环境。
ftp> put a0rj69fq_1_1 200 PORT command successful. 150 Opening data connection for a0rj69fq_1_1. 226 Transfer complete. 23119626240 bytes sent in 1395 seconds (1.618e+04 Kbytes/s) local: a0rj69fq_1_1 remote: a0rj69fq_1_1 ftp> ftp> ftp>put 9vrj66jc_1_1 200 PORT command successful. 150 Opening data connection for 9vrj66jc_1_1. 226 Transfer complete. 22823591936 bytes sent in 1381 seconds (1.614e+04 Kbytes/s) local: 9vrj66jc_1_1 remote: 9vrj66jc_1_1
两个窗口并行传输,花费时间25分钟,由于第一次增量数据较大整体消耗2个小时。
6.3.2 目标端进行第一次增量恢复
增量恢复前需要检查 xttnewdatafiles.txt(数据文件在 ASM 中 MAP 关系表)、tsbkupmap.txt 和 incrbackups.txt(增量与数据文件对应关系配置)、xttplan.txt(下次需要增量的开始 SCN)这些配置文件是否存在,如不存在会出现报错。
将增量备份集放置 /home/oracle/xtts/bak下,做增量恢复:
more restore_incr.sh export TMPDIR=/home/oracle/xtts perl xttdriver.pl -r
执行脚本进行增量恢复:
nohup sh ./restore_incr.sh >restore_incr.log &
第一次增量转换加恢复40G数据耗时30分钟。

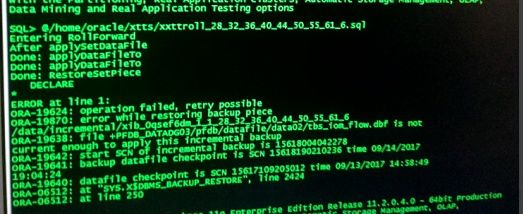
如果在-r应用报 ORA-19638 错误,则需要把 xttplan.txt 使用前一次或前二次的。(因为多次的-i和-s会对 xttplan.txt 进行修改)
6.3.3 生成下次增量所需 SCN 配置文件
$ perl xttdriver.pl -s
-------------------------------------------------------------------- Parsing properties -------------------------------------------------------------------- -------------------------------------------------------------------- Done parsing properties -------------------------------------------------------------------- -------------------------------------------------------------------- Checking properties -------------------------------------------------------------------- -------------------------------------------------------------------- Done checking properties -------------------------------------------------------------------- Prepare newscn for Tablespaces: 'DATATBS ' Prepare newscn for Tablespaces: '' Prepare newscn for Tablespaces: '' Prepare newscn for Tablespaces: '' Prepare newscn for Tablespaces: '' Prepare newscn for Tablespaces: '' Prepare newscn for Tablespaces: '' Prepare newscn for Tablespaces: '' Prepare newscn for Tablespaces: '' Prepare newscn for Tablespaces: '' Prepare newscn for Tablespaces: '' Prepare newscn for Tablespaces: '' Prepare newscn for Tablespaces: '' Prepare newscn for Tablespaces: '' Prepare newscn for Tablespaces: '' Prepare newscn for Tablespaces: '' New /oraexport/xtts/xttplan.txt with FROM SCN's generated [root@ecmsdb01plk xtts]# cat xttplan.txt DATATBS ::::14000344337
生产环境执行如上命令,产生最新 xttplan.txt 文件,下次增量备份开始 SCN 为 14000344337。
6.3.4 生产库进行第二次增量备份
生产环境进行第二次增量备份,此次增量备份一天数据:
more do_incr.sh export TMPDIR=/home/oracle/xtts perl xttdriver.pl –i
执行脚本进行增量备份:
nohup sh ./do_incr.sh >do_incr_1.log &
backup incremental from scn 14000344337 第二次增量备份开始的 SCN。
第二次增量备份一天数据耗时5分钟。产生文件12G,通过 FTP 并行传输花费10分钟,总体二次增量备份一天数据耗时20分钟。
6.3.5 目标端进行第二次增量恢复
xttplan.txt 使用前一次的。
二次增量恢复一天数据,耗时15分钟:
[oracle@ecmsdb01plk scripts_linux]$ perl xttdriver.pl -r -d
6.4 XTTS 正式迁移

切割准备工作示意图
6.4.1 停止业务
业务部门停止应用程序。数据库检查当前会话,需要杀掉已经存在的会话。
set lines 132 pages 1111 trim on trims on spo machine_before_upgrade.txt select inst_id, machine, count(*) from gv$session where username!='SYS' group by inst_id, machine; spo off
Kill 掉任然连接到数据库的会话:
SELECT 'kill -9 '||SPID FROM V$PROCESS WHERE ADDR IN (SELECT PADDR FROM V$SESSION WHERE USERNAME != 'SYS'); 或 select 'alter system kill session '''||sid||','||serial#||''' immediate;' from v$session where USERNAME != 'SYS';
6.4.2 生成最后一次增量备份 SCN 配置文件
$ perl xttdriver.pl -s
使用 xttdriver.pl –s生成最后一个 SCN 增量配置文件(即最后一次增量备份开始的SCN),也可以手工修改 xttplan.txt。
6.4.3 生产库将表空间设置为只读
将业务表空间设置为只读模式,并开始最后一次的增量备份。
sqlplus / as sysdba alter tablespace DATAtBS read only;
6.4.4 最后一次增量备份
在源端中间环境进行最后一次增量备份:
more do_incr.sh export TMPDIR=/home/oracle/xtts perl xttdriver.pl –i 执行脚本进行备份: nohup sh ./do_incr.sh >do_incr_1.log &
按照之前每天增量备份加传输大概耗时30分钟,在增量备份同时可以进行元数据的导出。
6.4.5 导出元数据(XTTS 元数据以及其他对象元数据)
在这个步骤中,我们可以并行同时导出 XTTS 的元数据以及其他的元数据,例如数据库存储过程,函数。触发器等等。
导出传输表空间元数据命令如下:
create or replace directory xtts3 as '/oraexport/xtts/ ' exp \'/ as sysdba \' transport_tablespace=y tablespaces='DATATBS ' file=/oraexport/xtts/exp_DATATBS_xtts.dmp log=/oraexport/xtts/exp_DATATBS_xtts.log STATISTICS=none parallel=8 expdp \'/ as sysdba\' dumpfile=tts.dmp directory=xtts_dir logfile=expdp_xtts.log transport_tablespaces=TEST,TEST_INDEX exclude=STATISTICS;
导出元数据耗时2分钟。
导出其他对象数据如下:
expdp \'/ as sysdba\' directory=xtts_dir dumpfile=expdp_LUOKLE_meta.dmp logfile=expdp_LUOKLE_meta.log CONTENT=metadata_only SCHEMAS=LUOKLE parallel=2;
导出其他数据耗时15分钟。
导出完成之后,将 dmp 文件传输到 Linux。
6.4.6 最后一次应用增量备份
将备份集放置 /oradata2 下,做增量恢复:
more restore_incr.sh export TMPDIR=/home/oracle/xtts perl xttdriver.pl -r -d 执行脚本进行增量恢复: nohup sh ./restore_incr.sh >restore_incr.log &
根据之前增量恢复一天数据大概耗时15分钟。
6.4.7 导入 XTTS 元数据
通过如下命令将 xtts 表空间元数据导入到目标新库中:
create or replace directory xtts_dir as '/home/oracle/xtts/'; impdp \'/ as sysdba\' dumpfile=expdp_tts.dmp directory=xtts_dir transport_tablespace=y datafiles='+DATA/ORACLE11GASM/DATAFILE/test_5.xtf,+DATA/ORACLE11GASM/DATAFILE/test_index_6.xtf';
根据之前测试结果导入时间为10分钟左右。
6.4.8 目标端新库将表空间设置为读写模式
将业务表空间设置为可读写模式:
sqlplus / as sysdba alter tablespace DATATBS read write;
6.4.9 目标端新库导入其他对象元数据
impdp \'/ as sysdba\' dumpfile=expdp_LUOKLE_meta.dmp directory=xtts_dir
STATISTICS 如果不使用之前统计信息可用排除,最后收集。
根据之前测试耗时15分钟左右,XTTS 已完成表空间迁移。
7 XTTS 迁移后检查
7.1 更改用户默认表空间
更改用户默认表空间,将用户默认表空间设置与源数据库保持一致:
@default_tablespace.sql 源端执行: spool default_tablespace.sql select 'alter user '||username||' default tablespace '||default_tablespace||';' from dba_users where default_tablespace in(‘DATATBS ’); spool off 添加表空间配额权限: @unlimited_tablespace.sql 源库: select 'alter user '||username||' quota unlimited on '|| default_tablespace||';' from dba_users where default_tablespace in (‘DATATBS ’);
7.2 数据库对象并行重编译
exec utl_recomp.recomp_parallel(32); set echo off feedback off timing off verify off set pagesize 0 linesize 500 trimspool on trimout on Set heading off; set feedback off; set echo off; Set lines 999; spool compile.sql select 'alter '|| decode(object_type,'SYNONYM',decode(owner,'PUBLIC','PUBLIC SYNONYM '||object_name, 'SYNONYM '||OWNER||'.'||OBJECT_NAME)||' compile;', decode(OBJECT_TYPE ,'PACKAGE BODY','PACKAGE',OBJECT_TYPE)|| ' '||owner||'.'||object_name||' compile '|| decode(OBJECT_TYPE ,'PACKAGE BODY','BODY;',' ;')) from dba_objects where status<>'VALID' order by owner,OBJECT_NAME; spool off @compile.sql
正式环境没有无效对象。
7.3 数据库对象数据比对
运行数据库对比脚本,通过创建 dblink,运行相关的数据库对象比对脚本。这里我们主要比对了存储过程,函数,触发器,试图,索引,表等等。
创建到生产环境 DB LINK
CREATE DATABASE LINK TEST_COMPARE CONNECT TO SYSTEM IDENTIFIED BY password xxx USING 'xxxx:1521/xxxx';
使用如下脚本对比数据库中对象个数:
SELECT OWNER, OBJECT_NAME, OBJECT_TYPE
FROM DBA_OBJECTS@TEST_COMPARE
WHERE OBJECT_NAME NOT LIKE 'BIN%'
AND OBJECT_NAME NOT LIKE 'SYS_%'
AND OWNER IN ('LUOKLE')
MINUS
SELECT OWNER, OBJECT_NAME, OBJECT_TYPE
FROM DBA_OBJECTS
WHERE OBJECT_NAME NOT LIKE 'BIN%'
AND OBJECT_NAME NOT LIKE 'SYS_%'
AND OWNER IN ('LUOKLE');
或
源库:
select object_type,count(*) from dba_objects where owner
in (select username from 源库) group by object_type;
目标:
select object_type,count(*) from dba_objects where owner
in (select username from 目标库) group by object_type;
如果索引缺失可能是由于没有存放在传输的表空间所以需要重新创建,而缺失的表可能是临时表,需要手工创建。
使用如下脚本进行创建:
CREATE INDEX "LUOKLE"."IDX_XXX" ON "LUOKLE"."BI_XXXX" TABLESPACEDATATBS parallel 8;
Alter index "LUOKLE"."IDX_XX" noparallel;
CREATE GLOBAL TEMPORARY TABLE "LUOKLE"."TEMP_PAY_BATCH_CREATE_INSTR"
( "BATCH_ID" NUMBER,
"STATUS" CHAR(1)
) ON COMMIT PRESERVE ROWS ;
使用 hash 函数进行数据对比
两边分别创建存放 hash 数据的表
create table system.get_has_value (dbname varchar2(20),owner varchar2(30),table_name varchar2(100),value varchar2(100),error varchar2(2000));
创建需要验证的表:
create sequence system.sequence_checkout_table start with 1 increment by 1 order cycle maxvalue 10 nocache;
CREATE TABLE SYSTEM.checkout_table as select sys_context('USERENV', 'INSTANCE_NAME') dbnme,owner,table_name, system.sequence_checkout_table.NEXTVAL groupid from dba_tables where owner='LUOKLE'
结果显示:
1 SELECT owner, groupid, COUNT (*)
2 FROM SYSTEM.checkout_table
3* GROUP BY owner, groupid,dbnme Order by owner,groupid
14:05:21 SQL> SELECT owner, groupid, COUNT (*)
14:05:31 2 FROM SYSTEM.checkout_table
14:05:32 3 GROUP BY owner, groupid,dbnme Order by owner,groupid;
OWNER GROUPID COUNT(*)
------------------------------ ---------- ----------
LUOKLE 1 32
LUOKLE 2 31
LUOKLE 3 31
LUOKLE 4 31
LUOKLE 5 31
LUOKLE 6 31
LUOKLE 7 31
LUOKLE 8 31
LUOKLE 9 31
LUOKLE 10 31
创建 hash 函数
grant select on sys.dba_tab_columns to system;
CREATE OR REPLACE PROCEDURE SYSTEM.get_hv_of_data (
avc_owner VARCHAR2,
avc_table VARCHAR2)
AS
lvc_sql_text VARCHAR2 (30000);
ln_hash_value NUMBER;
lvc_error VARCHAR2 (100);
BEGIN
SELECT 'select /*+parallel(a,25)*/sum(dbms_utility.get_hash_value('
|| column_name_path
|| ',0,power(2,30)) ) from '
|| owner
|| '.'
|| table_name
|| ' a '
INTO LVC_SQL_TEXT
FROM (SELECT owner,
table_name,
column_name_path,
ROW_NUMBER ()
OVER (PARTITION BY table_name
ORDER BY table_name, curr_level DESC)
column_name_path_rank
FROM ( SELECT owner,
table_name,
column_name,
RANK,
LEVEL AS curr_level,
LTRIM (
SYS_CONNECT_BY_PATH (column_name, '||''|''||'),
'||''|''||')
column_name_path
FROM ( SELECT owner,
table_name,
'"' || column_name || '"' column_name,
ROW_NUMBER ()
OVER (PARTITION BY table_name
ORDER BY table_name, column_name)
RANK
FROM dba_tab_columns
WHERE owner = UPPER (avc_owner)
AND table_name = UPPER (avc_table)
AND DATA_TYPE IN ('TIMESTAMP(3)',
'INTERVAL DAY(3) TO SECOND(0)',
'TIMESTAMP(6)',
'NVARCHAR2',
'CHAR',
'BINARY_DOUBLE',
'NCHAR',
'DATE',
'RAW',
'TIMESTAMP(6)',
'VARCHAR2',
'NUMBER')
ORDER BY table_name, column_name)
CONNECT BY table_name = PRIOR table_name
AND RANK - 1 = PRIOR RANK))
WHERE column_name_path_rank = 1;
EXECUTE IMMEDIATE lvc_sql_text INTO ln_hash_value;
lvc_sql_text :=
'insert into system.get_has_value(owner,table_name,value) values(:x1,:x2,:x3)';
EXECUTE IMMEDIATE lvc_sql_text USING avc_owner, avc_table, ln_hash_value;
commit;
DBMS_OUTPUT.put_line (
avc_owner || '.' || avc_table || ' ' || ln_hash_value);
EXCEPTION
WHEN NO_DATA_FOUND
THEN
lvc_error := 'NO DATA FOUND';
lvc_sql_text :=
'insert into system.get_has_value(owner,table_name,error) values(:x1,:x2,:x3)';
EXECUTE IMMEDIATE lvc_sql_text USING avc_owner, avc_table, lvc_error;
commit;
WHEN OTHERS
THEN
lvc_sql_text :=
'insert into system.get_has_value(owner,table_name,value) values(:x1,:x2,:x3)';
EXECUTE IMMEDIATE lvc_sql_text USING avc_owner, avc_table, SQLERRM;
commit;
END;
/
sqlplus system/oracle<<EOF
set heading off linesize 170 pagesize 0 feedback off echo off trimout on trimspool on termout off verify of
exit
EOF
nohup ./check_source.sh LUOKLE 1 >./source_LUOKLE_cd_1.log 2>&1 &
nohup ./check_source.sh LUOKLE 2 >./source_LUOKLE_cd_1.log 2>&1 &
nohup ./check_source.sh LUOKLE 3 >./source_LUOKLE_cd_1.log 2>&1 &
nohup ./check_source.sh LUOKLE 4 >./source_LUOKLE_cd_1.log 2>&1 &
nohup ./check_source.sh LUOKLE 5 >./source_LUOKLE_cd_1.log 2>&1 &
nohup ./check_source.sh LUOKLE 6 >./source_LUOKLE_cd_1.log 2>&1 &
nohup ./check_source.sh LUOKLE 7 >./source_LUOKLE_cd_1.log 2>&1 &
nohup ./check_source.sh LUOKLE 8 >./source_LUOKLE_cd_1.log 2>&1 &
nohup ./check_source.sh LUOKLE 9 >./source_LUOKLE_cd_1.log 2>&1 &
nohup ./check_source.sh LUOKLE 10 >./source_LUOKLE_cd_1.log 2>&1 &
checkdata_source.sh
date
sqlplus system/oracle<<EOF
set heading off linesize 170 pagesize 0 feedback off
spool source_check_$1_$2.sql
SELECT 'exec system.get_hv_of_data('''
|| owner
|| ''','''
|| table_name
|| ''')'
FROM system.checkout_table
WHERE owner = UPPER ('$1') and groupid=$2
AND table_name NOT IN (SELECT table_name
FROM dba_tables
WHERE owner = UPPER ('$1')
AND iot_type IS NOT NULL)
AND table_name IN (SELECT table_name
FROM ( SELECT table_name, COUNT (*)
FROM dba_tab_columns
WHERE owner = UPPER ('$1')
AND DATA_TYPE IN ('TIMESTAMP(3)',
'INTERVAL DAY(3) TO SECOND(0)',
'TIMESTAMP(6)',
'NVARCHAR2',
'CHAR',
'BINARY_DOUBLE',
'NCHAR',
'DATE',
'RAW',
'VARCHAR2',
'NUMBER')
GROUP BY table_name
HAVING COUNT (*) > 0))
ORDER BY table_name;
spool off
set serveroutput on
@source_check_$1_$2.sql
exit;
EOF
date
运行 hash 计算函数脚本,在LINUX环境对 LUOKLE 下所有表进行 hash 计算耗时30分钟,总共311张表,有52张表没有计算出 hash 经分析发现这些表为空表。
SQL> select count(*) from LUOKLE.XXXX;
COUNT(*)
----------
0
7.4 数据库对象间权限比对处理
对比源库和目标库数据库的对象级别间权限,如若权限不一致建议将源库跑出的 grant_tab_privs.log 到目标端执行。
复核对象上的 select 和 DML 权限赋予给用户
@grant_tab_privs.sql
源库:
select 'grant ' || privilege || ' on ' || owner || '.' || table_name || ' to ' || grantee || ';' from dba_tab_privs where (grantee in(select username from dba_users where default_tablespace in(‘DATATBS ’)) or owner in(select username from dba_users where default_tablespace in(DATATBS ))) and privilege in('SELECT','DELETE','UPDATE','INSERT') and grantable='NO'
union
select 'grant ' || privilege || ' on ' || owner || '.' || table_name || ' to ' || grantee || ' with grant option;' from dba_tab_privs where (grantee in(select username from dba_users where default_tablespace in(DATATBS )) or owner in(select username from dba_users where default_tablespace in(DATATBS ))) and privilege in('SELECT','DELETE','UPDATE','INSERT') and grantable='YES';
7.5 收集统计信息
为了防止同时收集统计信息,造成系统资源的消耗,建议提前关闭后台自动收集统计信息的任务。
exec DBMS_AUTO_TASK_ADMIN.DISABLE(client_name => 'auto optimizer stats collection',operation => NULL,window_name => NULL);
查看柱状图信息:
select count(*),owner,table_name,column_name from dba_tab_histograms group by owner,table_name,column_name having count(*) > 2;
手工运行收集脚本:
exec DBMS_STATS.SET_GLOBAL_PREFS('CONCURRENT','TRUE');设置并发收集模式
exec
dbms_stats.gather_database_stats(
estimate_percent =>dbms_stats.AUTO_SAMPLE_SIZE, ///// for all columns size repeat
METHOD_OPT=>'FOR ALL COLUMNS SIZE 1',
options=> 'GATHER',degree=>8,
granularity =>’all’,
cascade=> TRUE
);
select * from dba_scheduler_jobs where schedule_type = 'IMMEDIATE' and state = 'RUNNING';
收集数据字典统计信息:
exec DBMS_STATS.GATHER_DICTIONARY_STATS(degree=>16);
固定对象的统计信息:
EXECUTE DBMS_STATS.GATHER_FIXED_OBJECTS_STATS;
开启默认收集
exec DBMS_AUTO_TASK_ADMIN.ENABLE(client_name => 'auto optimizer stats collection',operation => NULL,window_name => NULL);
exec DBMS_STATS.SET_GLOBAL_PREFS('CONCURRENT','false');
以下为测试过程:
13:23:41 SQL> select count(*),owner,table_name,column_name from dba_tab_histograms 13:23:45 2 where owner='LUOKLE' 13:23:46 3 group by owner,table_name,column_name 13:23:46 4 having count(*) > 2; no rows selected Elapsed: 00:00:00.10 13:28:06 SQL> exec dbms_stats.gather_database_stats(estimate_percent =>dbms_stats.AUTO_SAMPLE_SIZE,METHOD_OPT=>'FOR ALL COLUMNS SIZE 1',options=> 'GATHER',degree=>8, granularity =>'all',cascade=> TRUE); PL/SQL procedure successfully completed. Elapsed: 00:26:51.34 13:55:05 SQL>
全库统计信息收集耗时26分钟
13:57:14 SQL> exec DBMS_STATS.GATHER_DICTIONARY_STATS(degree=>16); PL/SQL procedure successfully completed. Elapsed: 00:00:18.94
7.6 修改 job 参数
show parameter job_queue_processes; alter system set job_queue_processes=100 scope=both;
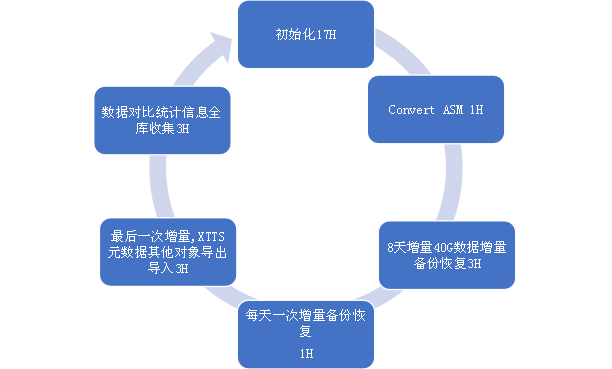
8 XTTS 迁移测试耗时(20T)
9 XTTS 迁移测试问题记录
expdp \'/ as sysdba\' directory=xtts dumpfile=expdp_LUOKLE_meta0822.dmp logfile=expdp_LUOKLE_meta0822.log CONTENT=metadata_only SCHEMAS=LUOKLE 15:06 开始到出 ORA-39014: One or more workers have prematurely exited. ORA-39029: worker 1 with process name "DW00" prematurely terminated ORA-31671: Worker process DW00 had an unhandled exception. ORA-04030: out of process memory when trying to allocate 3704 bytes (kkoutlCreatePh,kkotbi : kkotbal) ORA-06512: at "SYS.KUPW$WORKER", line 1887 ORA-06512: at line 2
在做元数据导出时候后台报大量 ORA-04030 错误,经过分析为 AMM 问题,通过关闭 AMM 手工管理内存解决。
10g 的 sga_target 设置为0
Errors in file /oracle/app/oracle/diag/rdbms/LUOKLE/orcl1/trace/orcl1_ora_13107324.trc (incident=28001): ORA-04030: out of process memory when trying to allocate 32808 bytes (TCHK^cadd45dc,kggec.c.kggfa)
经过分析发现 AIX stack 设置偏小导致,修改限制解决。
ERROR IN CONVERSION ORA-19624: operation failed, retry possible ORA-19505: failed to identify file "/aix_xtts/oradata2/f8rdl6vi_1_1" ORA-27037: unable to obtain file status Linux-x86_64 Error: 2: No such file or directory Additional information: 3 ORA-19600: input file is backup piece (/aix_xtts/oradata2/f8rdl6vi_1_1) ORA-19601: output file is backup piece (/aix_xtts/incr/xib_f8rdl6vi_1_1_6_8_10_12_14_16_18_20_22_) CONVERTED BACKUP PIECE/aix_xtts/incr/xib_f8rdl6vi_1_1_6_8_10_12_14_16_18_20_22_ PL/SQL procedure successfully completed. ERROR IN CONVERSION ORA-19624: operation failed, retry possible ORA-19505: failed to identify file "/aix_xtts/oradata2/f9rdl70m_1_1" ORA-27037: unable to obtain file status Linux-x86_64 Error: 2: No such file or directory Additional information: 3 ORA-19600: input file is backup piece (/aix_xtts/oradata2/f9rdl70m_1_1) ORA-19601: output file is backup piece (/aix_xtts/incr/xib_f9rdl70m_1_1_7_9_11_13_15_17_19_21_23_) CONVERTED BACKUP PIECE/aix_xtts/incr/xib_f9rdl70m_1_1_7_9_11_13_15_17_19_21_23_
经过分析发现增量备份没有放在对应目录导致。
failed to create file "/xtts/incr/xib_f9rdl70m_1_1_7_9_11_13_15_17_19_21_23_" ORA-27040: file create error, unable to create file Linux-x86_64 Error: 13: Permission denied Additional information: 1 ORA-19600: input file is backup piece (/xtts/oradata2/f9rdl70m_1_1) ORA-19601: output file is backup piece (/xtts/incr/xib_f9rdl70m_1_1_7_9_11_13_15_17_19_21_23_) CONVERTED BACKUP PIECE/xtts/incr/xib_f9rdl70m_1_1_7_9_11_13_15_17_19_21_23_ PL/SQL procedure successfully completed. ERROR IN CONVERSION ORA-19624: operation failed, retry possible ORA-19504: failed to create file "/xtts/incr/xib_f8rdl6vi_1_1_6_8_10_12_14_16_18_20_22_" ORA-27040: file create error, unable to create file Linux-x86_64 Error: 13: Permission denied Additional information: 1 ORA-19600: input file is backup piece (/xtts/oradata2/f8rdl6vi_1_1) ORA-19601: output file is backup piece (/xtts/incr/xib_f8rdl6vi_1_1_6_8_10_12_14_16_18_20_22_) CONVERTED BACKUP PIECE/xtts/incr/xib_f8rdl6vi_1_1_6_8_10_12_14_16_18_20_22_
NFS 目录权限问题导致不行读写,修改权限解决。
NFS 问题:
mount: 1831-008 giving up on: 192.168.1.100:/xtts vmount: Operation not permitted. # nfso -p -o nfs_use_reserved_ports=1 Setting nfs_use_reserved_ports to 1 Setting nfs_use_reserved_ports to 1 in nextboot file # mount -o cio,rw,bg,hard,nointr,rsize=32768,wsize=32768,proto=tcp,noac,vers=3,timeo=600 10.20.28.21:/xtts /aix_xtts
10 总结
XTTS 支持跨平台跨版本迁移,操作起来比较方便,由于停机时间较短,可以较轻松完成迁移工作,在大数据量的跨平台跨版本迁移场景中,建议作为首选方案。
建议在做 XTTS 迁移的时候减少批次,批次越多,增量备份的数据越少,数据越少,最后停机时间越短,但是这个过程如果做太多就越容易出错。一般使用一次增量备份再做一次正式迁移,甚至初始化后直接做正式迁移。
11 附录 - xttdriver.pl 脚本使用说明
详见:11G - Reduce Transportable Tablespace Downtime using Cross Platform Incremental Backup (文档 ID 1389592.1)