- redis-主从复制是redis分布式的基础,redis的高可用离开了主从复制将无法进行
- sentinel是redis高可用的一种解决方案
- 由一个或者多个sentinel实例组成的sentinel系统可以监视任意多个主服务器以及主服务器下属的从服务器
- 并且在被监视的主服务器进入下线状态时,自动将下线主服务器下属的某个从服务器升级为新的主服务器
- 然后由新的主服务器代替已经下线的主服务器继续执行命令请求
-
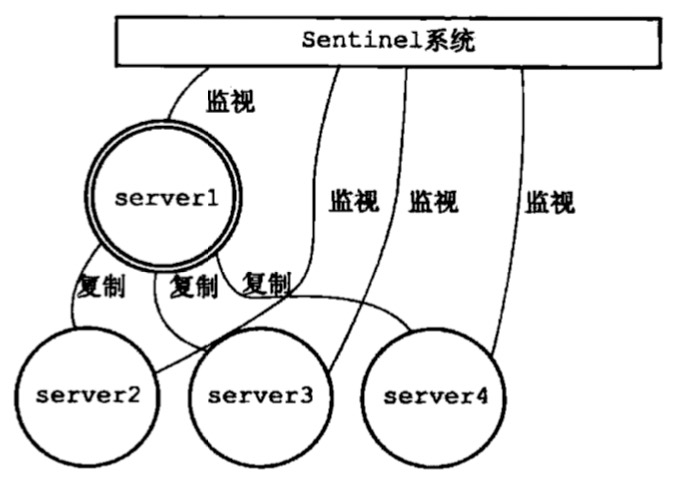
图一是正常状态下的sentinel体系,sentinel系统监视所有主从节点
- sentinel会向master建立两个异步网络连接:命令连接;_sentinel_:hello频道
- sentinel每十秒一次通过命令连接获取主服务器以及从服务器信息
- sentinel每两秒一次通过被监视服务器的_sentinel_:hello频道向其他sentinel宣告自己存在
- sentinel之间只存在命令连接
-
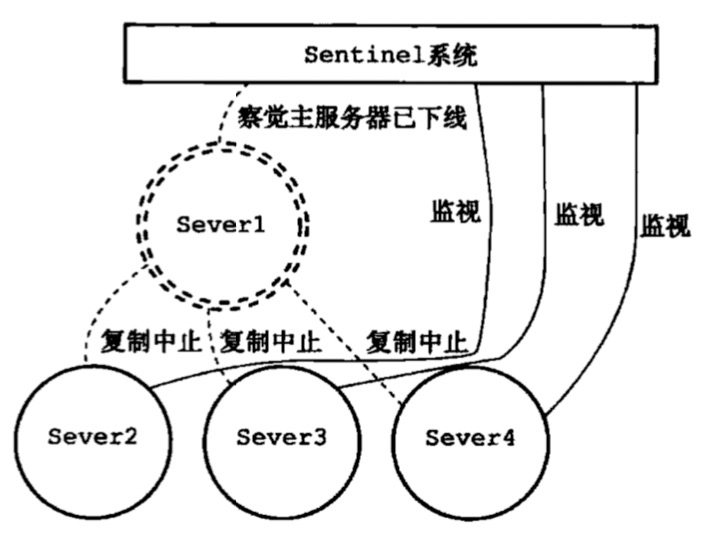
图二是当sentinel发现master挂掉的情况,主从复制会中断
- 主观下线:少数派sentinel认为master下线
- 客观下线:大多数sentinel认为master下线
-
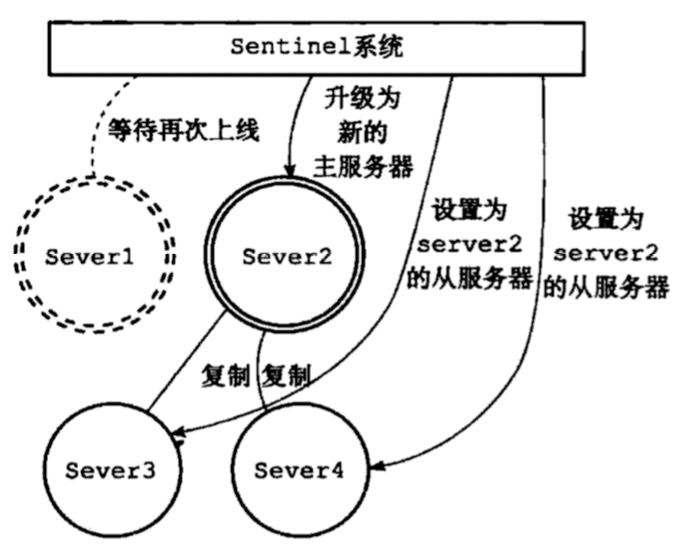
图三是sentinel开始执行容灾,会选择一个最优的slave节点升级为new-master节点设置新的主从关系,开始主从复制
- sentinel会选举一个领头sentinel来对下线服务器之心个故障转移
- 领头sentinel挑选一个最合理的slave(复制偏移量最大的节点)来晋升为new-master
- 已下线的master的所有slave都连接new-master开始主从复制
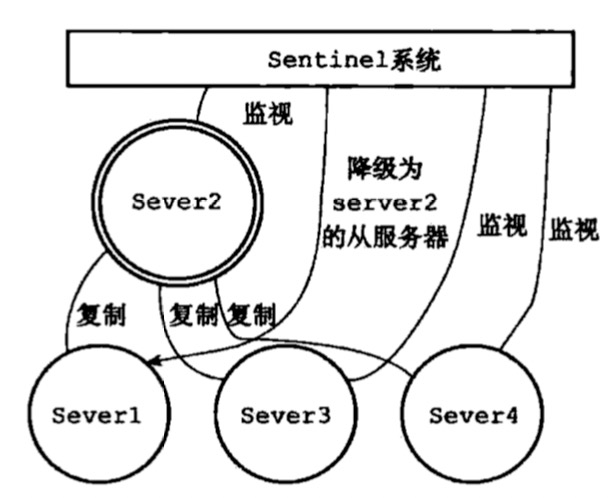
- 图四是当old-master重启后会被作为新的slave节点挂在master下,执行主从同步复制
总结:
sentinel是在主从复制的基础上实现了对节点的监控和容灾,解决了主从复制模型中,无法自动容灾的问题
sentinel是运行在特殊模式下的redis服务器,使用与普通redis服务器不同的命令表
sentinel使用raft多数派选举算法来判定master下线,来执行选举,确保了不会出现脑裂的风险
sentinel最小数目三台,可以保证最基础的可用性容错性
redis-cluster
- sentinel模型虽然提供了高可用的保障,但是在大数据高并发下,单个redis实例闲的捉襟见肘
- 首先在内存上,单个redis内存不宜过大,否则会导致rdb文件过大
- 导致主从同步复制时全量复制时间过长;在实例重启恢复时也会消耗很长的数据加载时间
- 其次在cpu利用率上,单个redis实例只能利用单个核心
- 在多核的背景下,浪费机器资源;并且单个核心完成海量数据存取压力也很大
综上所述,redis集群方案就显得很重要,集群可以将众多小内存redis实例整合起来,将分布在多台机器上的cpu核心运算能力聚集起来,完成海量数据存储和高并发读写操作
redis集群是通过分片(sharding)来进行数据共享,并且提供复制和故障转移功能
redis是去中心化的集群模型
集群节点cluster-node
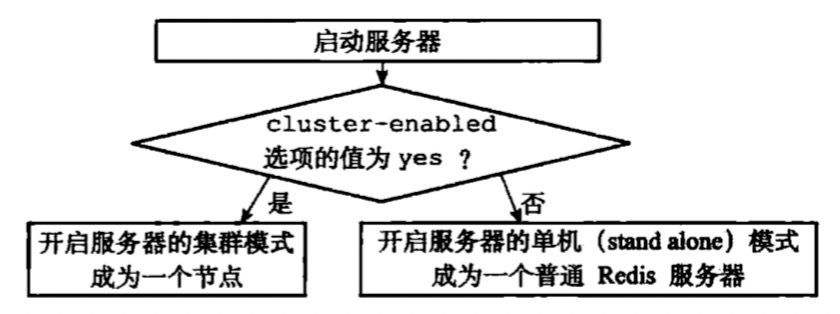
- node是组成集群的基本单位,就是一个运行在集群模式下的redis服务器,redis服务器会在启动时根据cluster-enabled配置选项是否为yes来决定是否开启集群模式
-
集群中节点在集群运行中会继续使用单机模式中的服务器组件:
扫描二维码关注公众号,回复: 8164199 查看本文章
-
- 节点会继续使用文件事件来处理命令请求和命令回复
- 节点会继续使用时间事件通过serverCron来处理周期任务;集群模式下serverCron函数会执行集群的clusterCron函数
- 节点依旧可以使用rdb或者aof持久化方式来实现redis数据持久化
- 节点依旧使用发布订阅模块来执行publish,subscribe命令
- 节点会继续使用复制模块进行节点的复制工作
集群分片-槽指派
redis集群通过分片的方式来保存数据库中的键值对:
- 集群的整个数据库被分为16384个槽(slot)
- 数据库中的每个key都属于这16384个槽中的一个
- 集群中每个节点都可以处理最少0个最多16384个槽(slot)
- 当数据库中的16384个槽都有节点处理-集群处于上线状态
- 当数据库中有任意一个槽没有得到节点处理-集群处于下线状态
槽定位:
- cluster默认会对key值使用crc16算法进行hash得到一个整数值
- 然后用这个整数对16383进行取模得到具体槽位
- cluster允许用户强制某个key挂在特定的槽位上

-
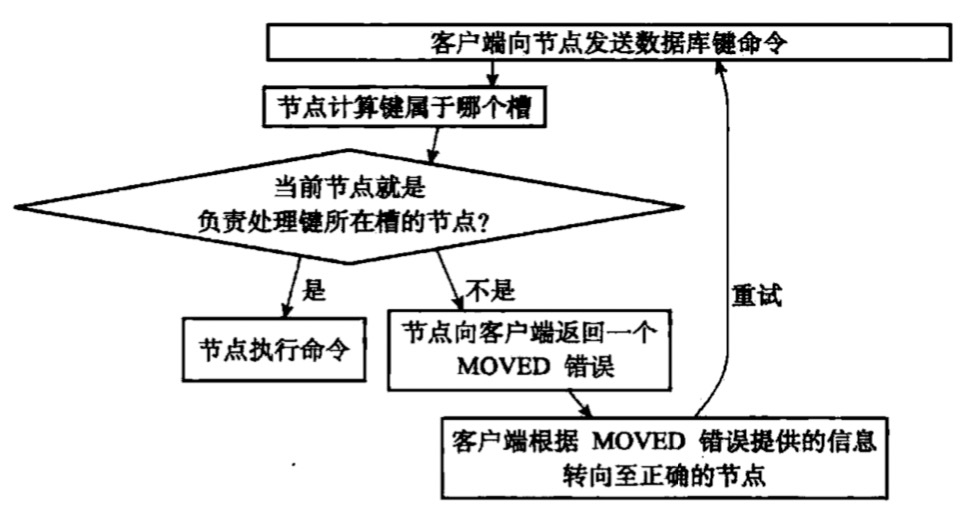
当客户端向节点发送数据库命令时,接受命令的节点会计算出命令要处理的数据库属于哪个槽,并且检查这个歌槽是否指派给了自己
- 如果key所在的槽正好指派到了当前节点,那么节点直接执行命令
- 如果key所在槽未指派给当前节点,节点会向客户端返回一个moved错误,指引客户端转向正确节点执行命令
节点数据库
- 集群节点保存键值对以及键值对过期的方式与单机redis服务器对键值对以及过期处理方式完全相同
- 集群节点只能使用0号数据库,而单机数据库没有这种限制
- 集群节点会使用clusterState结构中的slots_to_keys跳跃表来保存slot与key的关系
总结
redis-cluster是一个去中心化的集群,每个单独节点都与单机redis节点功能一致
redis-cluster基于分片实现数据共享,一共16384个槽对应集群中的主节点
redis-cluster中slot对应的是master-node节点,slave-node只负责与master同步复制
redis-cluster中主节点失效,会从slave中选择合理slave晋升为新master
r