讲师介绍:
- 稳定性建设: 如何做到服务9999的稳定性即每年不可用时间不到1min
- 高性能系统: 滴滴运营广告系统即并发量很大
- 社招面试: 秒杀系统的设计与实现,其本质高并发高可用,这两方面的技术可直接决定公司技术水平,提现个人技术实力
概要:
- 基本知识和原理
- 减而治之
- cdn原理: 减少读的压力,如订单详情页下发到不同地方的cdn节点,访问加速,回源减少
- Nginx限流: 请求到达服务端(即接入层)如何做过载保护
- 异步队列概念: 如通过异步方式创建订单
- 分而治之
- Nginx负载均衡: 流量到达接入层,接入层分摊到每个server层
- 难点分析架构思路: 结合具体应用场景分析难点及如何架构
- 特征
- 写的强一致性: 抢购时不能发生超卖现象
- 读的弱一致性: 显示有库存,但下单不成功即减不了库存(如:12306,总库存和实际抢票的库存可以不一致)
- 难点
- 极致性能的实现: 可用上万台机器分摊流量达到负载均衡,但成本高; 应该提高单个服务的极致性能
- 高可用的保证
- 核心实现思路
- 极致性能的读服务实现: 需要实时读的库存数
- 极致性能的写服务实现: 扣库存,同时创建订单
- 极致性能的排队进度查询实现: 频繁查询排队进展
- 链路流量优化如何做: 流量第一次到达lvs层(Linux Virtual Server)->接入层->server层->客户端,如何减少每层流量,实现漏斗型流量过滤
- 兜底方案-高可用
- 高可用的 标准: 999和9999对应的标准
- 请求链路中每层高可用的实现原理: 每层出故障后该如何做
- 限流,一键降级和自动降级实现: 过载保护
目标:
- 掌握秒杀系统的核心实现
- 系统高可用的方法论学习
- 高并发场景的通用解决思路学习
工具使用与基础知识点介绍:
- 压测工具安装
- 原理: 通过多线程的模式,并发的访问某个接口,将对应的结果汇总统计展示出来
- yum -y install httpd-tools //通过yum命令安装ab压测工具
- ab -v //检查是否安装成功
- 检测接口最大qps(Queries-per-second)
- ab -n100 -c10 http://xxx
- 查看接口是否有优化空间,以达到单服务的性能极致
- 若接口性能无需优化,需要对接口进行限流,确保服务不会因为流量暴增挂掉
- Nginx限流配置
- 按连接数限速,即并发数(ngx_http_limit_conn_module)---限制客户端连接
- 按请求速率限速,按照ip限制单位时间内的请求书(ngx_http_limit_req_module)
- limit_req_zone $binary_remote_addr zone=mylimit:10m rate=1r/s; //创建规则; 以用户ip地址$binary_remote_addr为key;规则名是mylimit,申请了10M的空间;限制每秒1个请求
- limit_req zone=mylimit burst=1 nodelay; //应用规则; burst定义保留的缓存空间,nodelay如果burst设置的非常大时实现瞬间处理减少排队的等待时间
- ps aux | grep nginx //查看Nginx是否启动
- tail -f /var/log/nginx/error.log //nginx错误日志
- 限流算法介绍
- 令牌桶算法(例上述规则
- 匀速生产令牌: 每500ms生产一个令牌并将令牌放入令牌桶,1s产生两个令牌
- 令牌桶: 请求过来从令牌桶中扣除令牌,桶中无令牌则返回503
- 好处: 限制请求的速度; 应对突发流量
- 漏桶算法
- 漏桶: 请求排队, 桶存在大小, 队列均匀流出,桶满则溢出,返回503
- 和令牌桶区别: 不能处理突发流量
- 计数器: 单位时间计数器计数即可,一般在 应用程序中写的较多
- cdn介绍(Content Delivery Network): qps固定的情况下,提示单服务性能(流量拦截)
- 作用:缩短访问路径,减少源站压力,提高内容响应速度,为源站提供安全保护
- 原理
- 传统c/s架构: 客户端直接请求server,导致访问量极大
- cdn架构: 根据客户端所在位置返回一个最近的cdn IP给客户端; 无缓存回源(源server)
- 同一个域名访问的是不同的cdn服务器,涉及dns解析,通过域名解析ip和端口
- 普通域名解析(即未经过cdn加速的域名解析)客户端(浏览器,app)
- gethostbyname("www.test.com")//获取域名的ip和端口
- gethostbyname{
生成查询DNS服务器的消息(域名,class,记录类型)
通过UDP协议向(最近的)DNS服务器发送消息
(DNS服务器查看本地缓存有没有该域名,没有向根域名请求该域名对应的ip和端口)
接受DNS服务器返回的消息并读取出ip地址返回
}
- 拿到ip地址直接访问对应服务器
- DNS解析原理
- 任何一台DNS服务器都保留根域信息
- 上级DNS服务器保管着所有下级DNS服务器的信息
- 客户端访问最近的DNS服务器,DNS服务器无缓存则请求root,root告诉DNS该域名需要访问某个子服务器,请求该子服务器后也会返回DNS应该访问的下级服务器
- 图解
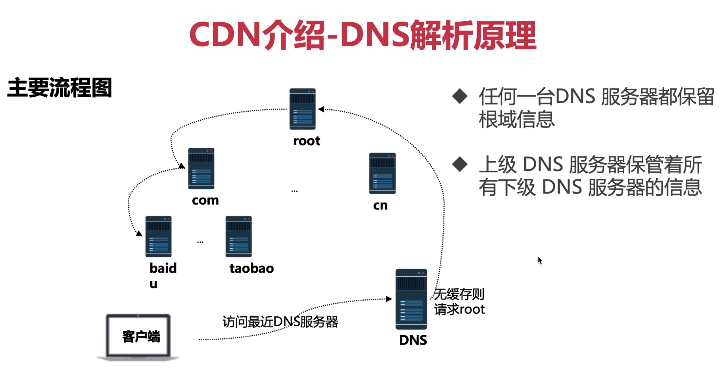
- DNS服务器数据存储格式
CNAME记录: 类似查询转发,该记录不能直接使用IP,只能是另一个主机的别名.CDN是利用该记录来指定CDN服务器,如果有A记录与CNAME记录同时存在,则只使用A记录
- CDN原理: 通过CNAME方式把某个已加速过的域名解析到另一个CDN服务商提供的dns解析的服务器

- 大型网站架构
- 主要结构(每层间有心跳检测,可及时将问题机器摘除,通过集群的方式确保服务高可用)
- 客户端: 请求某个地址时,通过dns/cdn加速到达,可能会回源至网站最外层router
- router(路由器/交换机): 使用Ospf负载均衡将流量负载至多个lvs机器上
- lvs层(lvs1,lvs2..): 四层负载均衡,流量到达后,不解析包内容,修改tcp头后转发给接入层
- 接入层(nginx1,nginx2..): 七层负载均衡,解析包内容,根据域名进行跳转至对应server层,同一个域名可以做到负载均衡的效果如ip做哈希来达到分流的效果
- server层(nginx+fpm,nginx+fpm..)
- nginx负载均衡算法介绍
- Round-robin(轮询)
- Weight-round-robin(带权轮询)
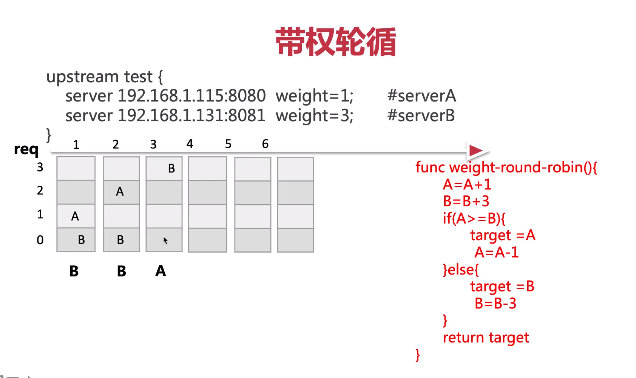
- Ip-hash(Ip哈希)
- 消息队列
- 消息队列实为链表,头插尾出,高并发下容易发生堵塞,为避免消息丢失,可通过写入实时消息队列进行延时处理
- 实时队列: 如海底捞排队
- 延时队列: 基于触发的时间进行排队,如订单
- 作用
- 提高请求响应速度,如创建订单后的流程,发push,短信提醒等
- 瞬间高并发下,可起到削锋,如双十一0点并发创建订单
- 延时队列,时间维度任务触发,如发货提醒
秒杀系统的难点分析与架构原则:
- 使用场景及预估并发量
- 商城活动抢购,优惠券,定时抢购 有效写100+ 并发抢1w+
- 小米商城手机抢购 有效写1w+ 并发抢100w+
- 12306抢票 有效写1w+ 并发抢100w+
- 天猫双十一凌晨促销秒杀 有效写10w+ 并发抢1000w+
- 特点
- 抢购人数远多于库存,读写并发巨大
- 库存少,有效写少
- 写需要强一致性,商品不能卖超
- 读强一致性要求不高(与库存存储方案有关)
- 难点
- 稳定性难
- 高并发下,某个小依赖可能直接造成雪崩
- 流量预期难精确,过高也造成雪崩
- 分布式集群,机器多,出故障的概率高
- 准确性难
- 库存,抢购成功数,创建订单数之间的一致性
- 高性能难
- 有限成本下需要做到极致的性能
- 架构原则
- 稳定性
- 减少第三方依赖,同事自身服务部署也需要做到隔离
- (接口进行)压测,(针对接口最大容量进行)限流,(用户被限流后展示503页面无法抢购)降级确保核心服务可用
- 需要健康度检查机制,整个链路避免单点
- 高性能
- 缩短单请求访问路径,减少IO
- 减少接口数,降低吞吐数据量,请求次数减少
- 目标: 满足高并发且高可用的秒杀系统
秒杀系统的核心实现:
- 秒杀服务核心实现
- 满足基本需求,做到单服务极致性能
- 扣库存
- 查库存(实时查询)和排队进度(创建订单量大时,扣库存操作跟不上)
- 查订单详情,创建订单,支付订单(该条属于订单中心; 以上两个为秒杀服务,挑战大)
- 请求链路流量优化,从客户端到服务端每层优化: 实现流量漏斗
- 稳定性建设
- 场景示例:某件商品1000库存,100w并发读,100w并发抢购
- 扣库存方案
- 下单减库存×
- 流程: 并发请求->创建订单->扣库存->支付 (创建订单与扣库存通过事务方式绑定)
- 问题: 创建订单扣完库存后并不去支付,存在恶意下单但不会出现超卖
- 支付减库存×
- 流程: 并发请求->创建订单->支付->扣库存 (支付与扣库存通过事务方式绑定,保持强一致性)
- 问题: 订单超卖,导致订单支付不了
- 预扣库存√
- 流程: 并发请求->扣库存->创建订单->支付(扣库存与创建订单通过事务方式绑定)
- 问题: 不支付库存卖不出
- 解决: 订单创建后,设置订单时效,订单失效后库存恢复避免不支付库存卖不出的问题
- 原因: 秒杀系统并发量大,创建订单及支付都涉及IO
- 该部分问题
- 问题: 下单减库存的第一个方案 ,创建订单同时库存减,但是不是支付,同样也是可以设置支付时效啊,与第三个方案感觉差不多呢? 不理解老师说的
- 解答: 方案一(下单减库存)和方案三(预扣库存)模式其实差不多,就像 do..while... 和 while 的区别,都可以用支付时效控制回收库存,但是方案一相对方案三 I/O 开销更高
- 问题: 预扣库存的方案中也存在恶意下单的问题啊,恶意用户减完库存后但是不支付,这样其他人只能等这批订单超时了,如果此时我再批量下单减完库存是不是可以一直让目标玩家抢不到商品
- 解决:确实是这样的。但是,对于这样的用户你可以记录下来,让他在第二次秒杀的时候丧失资格。
- 极致性能的扣库存服务如何实现
- 本质: 程序有没有对CPU进行有效的压榨
- 减少上下文切换(如go语言中的携程概念,基于线程实现,将线程分为多个时间段,线程不进行切换;通过单线程方式保证不做切换,但会造成阻塞I/O; 单线程不会充分使用多核cpu优势,可实行单机部署多实例方式提高cpu使用率)
- 减少阻塞式I/O: I/O主要包含rpv调用(远程通信:接口/redis查询/mysql查询等)/磁盘读写(文件读写)
- 无IO怎么做
- 拆解: 扣库存与写订单分开,秒杀系统仅提供扣库存服务
- 用内存: 调用远程redis,可实现单机单服务10w的qps
- 用本地内存
- 步骤
- 初始化库存到本地库存
- 本地减库存,成功则进行统一减库存,失败则返回
- 统一减库存成功则写入MQ(可用redis),异步创建订单
- 告知用户抢购成功
- 好处:
- 统一减库存,可以防止因为机器的增减导致超买超卖现象
- 本地减库存: php可以通过apcu扩展实现, go使用单线程不存在强锁过程
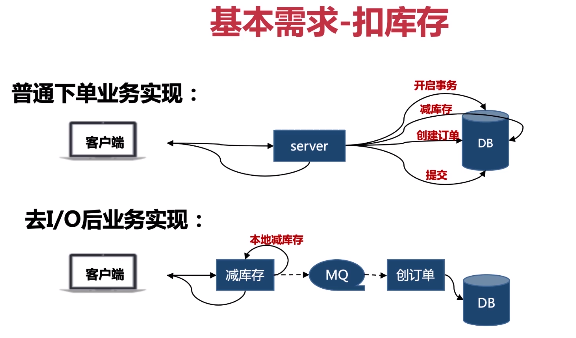
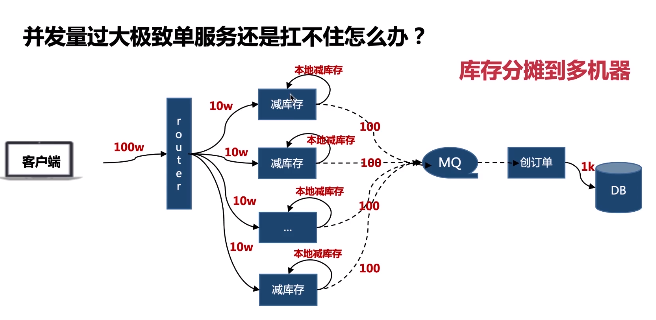
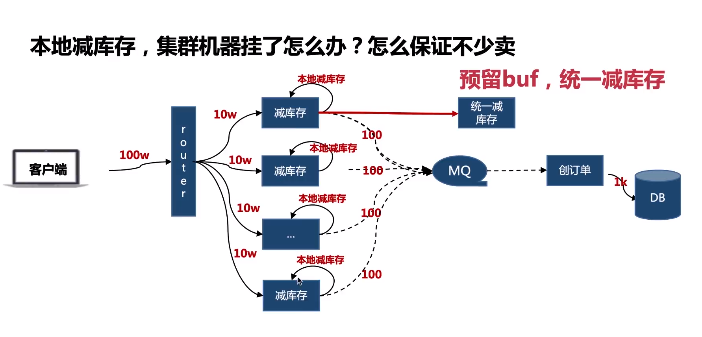
- 扣库存实现
- 因为php的fpm是一个多进程模型
- 多进程间修改某块共享内存时存在抢锁,频率高的话影响性能
- cpu单核的话,多进程进行切换,开销巨大
- 基类base.php
1 <?php 2 class Base{ 3 static $redisObj; 4 /*通过单例方式初始化一个redis连接*/ 5 static function conRedis($config = array()){ 6 if(self::$redisObj) return self::$redisObj; 7 self::$redisObj = new \Redis(); 8 self::$redisObj->connect('127.0.0.1', 6379); 9 return self::$redisObj; 10 } 11 /*接口输出格式化*/ 12 static function output($data = array(), $errNo = 0, $errMsg = 'ok'){ 13 $res['errno'] = $errNo; 14 $res['errmsg'] = $errMsg; 15 $res['data'] = $data; 16 echo json_encode($res); 17 exit(); 18 } 19 }
- api.php
1 <?php 2 include('base.php'); 3 class Api extends Base 4 { 5 //共享信息,存储在redis中,以hash表的形式存储,%s变量代表的是商品id 6 static $userId; 7 static $productId; 8 static $REDIS_REMOTE_HT_KEY = "product_%s"; //共享信息key 9 static $REDIS_REMOTE_TOTAL_COUNT = "total_count"; //商品总库存 10 static $REDIS_REMOTE_USE_COUNT = "used_count"; //已售库存 11 static $REDIS_REMOTE_QUEUE = "c_order_queue"; //创建订单队列 12 static $APCU_LOCAL_STOCK = "apcu_stock_%s"; //总共剩余库存 13 static $APCU_LOCAL_USE = "apcu_stock_use_%s"; //本地已售多少 14 static $APCU_LOCAL_COUNT = "apcu_total_count_%s"; //本地分库存分摊总数 15 public function __construct($productId, $userId) 16 { 17 self::$REDIS_REMOTE_HT_KEY = sprintf(self::$REDIS_REMOTE_HT_KEY, $productId); 18 self::$APCU_LOCAL_STOCK = sprintf(self::$APCU_LOCAL_STOCK, $productId); 19 self::$APCU_LOCAL_USE = sprintf(self::$APCU_LOCAL_USE, $productId); 20 self::$APCU_LOCAL_COUNT = sprintf(self::$APCU_LOCAL_COUNT, $productId); 21 self::$APCU_LOCAL_COUNT = sprintf(self::$APCU_LOCAL_COUNT, $productId); 22 self::$userId = $userId; 23 self::$productId = $productId; 24 } 25 static function clear(){ 26 apcu_delete(self::$APCU_LOCAL_STOCK); 27 apcu_delete(self::$APCU_LOCAL_USE); 28 apcu_delete(self::$APCU_LOCAL_COUNT); 29 30 } 31 /*查剩余库存*/ 32 static function getStock() 33 { 34 $stockNum = apcu_fetch(self::$APCU_LOCAL_STOCK); 35 if ($stockNum === false) { 36 $stockNum = self::initStock(); 37 } 38 self::output(['stock_num' => $stockNum]); 39 } 40 /*抢购-减库存*/ 41 static function buy() 42 { 43 $localStockNum = apcu_fetch(self::$APCU_LOCAL_COUNT); 44 if ($localStockNum === false) { 45 $localStockNum = self::init(); 46 } 47 $localUse = apcu_inc(self::$APCU_LOCAL_USE);//本已卖 + 1 48 if ($localUse > $localStockNum) {//抢购失败 大部分流量在此被拦截 49 echo 1; 50 self::output([], -1, '该商品已售完'); 51 } 52 //同步已售库存 + 1; 53 if (!self::incUseCount()) {//改失败,返回商品已售完 54 self::output([], -1, '该商品已售完'); 55 } 56 //写入创建订单队列 57 self::conRedis()->lPush(self::$REDIS_REMOTE_QUEUE, json_encode(['user_id' => self::$userId, 'product_id' => self::$productId])); 58 //返回抢购成功 59 self::output([], 0, '抢购成功,请从订单中心查看订单'); 60 } 61 /*创建订单*/ 62 /*查询订单*/ 63 /*总剩余库存同步本地,定时执行就可以*/ 64 static function sync() 65 { 66 $data = self::conRedis()->hMGet(self::$REDIS_REMOTE_HT_KEY, [self::$REDIS_REMOTE_TOTAL_COUNT, self::$REDIS_REMOTE_USE_COUNT]); 67 $num = $data['total_count'] - $data["used_count"]; 68 apcu_add(self::$APCU_LOCAL_STOCK, $num); 69 self::output([], 0, '同步库存成功'); 70 } 71 /*私有方法*/ 72 //库存同步 73 private static function incUseCount() 74 { 75 //需要查远端的总库存和已经售卖的计数 76 //同步远端库存时,需要经过lua脚本,保证不会出现超卖现象 77 //因为redis是单进程模型,可有效的避免两个用户同时进行查库存和扣库存 78 $script = <<<eof 79 local key = KEYS[1] 80 local field1 = KEYS[2] 81 local field2 = KEYS[3] 82 local field1_val = redis.call('hget', key, field1)//总库存 83 local field2_val = redis.call('hget', key, field2)//已经售卖的计数 84 if(field1_val>field2_val) then 85 return redis.call('HINCRBY', key, field2,1) 86 end 87 return 0 88 eof; 89 //eval()执行lua脚本的方法 90 return self::conRedis()->eval($script,[self::$REDIS_REMOTE_HT_KEY, self::$REDIS_REMOTE_TOTAL_COUNT, self::$REDIS_REMOTE_USE_COUNT] , 3); 91 } 92 /*初始化本地数据*/ 93 private static function init() 94 { 95 apcu_add(self::$APCU_LOCAL_COUNT, 150); 96 apcu_add(self::$APCU_LOCAL_USE, 0); 97 } 98 static function initStock(){ 99 $data = self::conRedis()->hMGet(self::$REDIS_REMOTE_HT_KEY, [self::$REDIS_REMOTE_TOTAL_COUNT, self::$REDIS_REMOTE_USE_COUNT]); 100 $num = $data['total_count']- $data["used_count"]; 101 apcu_add(self::$APCU_LOCAL_STOCK, $num); 102 return $num; 103 } 104 } 105 try{ 106 $act = $_GET['act']; 107 $product_id = $_GET['product_id']; 108 $user_id = $_GET['user_id']; 109 $obj = new Api($product_id, $user_id); 110 if (method_exists($obj, $act)) { 111 $obj::$act(); 112 die; 113 } 114 echo 'method_error!'; 115 } catch (\Exception $e) { 116 echo 'exception_error!'; 117 var_dump($e); 118 }
- 创建,支付订单
- 与扣库存服务隔离
- 用户收到抢购成功,页面跳转到订单中心去支付订单
- 图解: MQ异步创建订单

- 读商品信息页
- 与库存服务隔离
- 商品库一主多从提高读能力
- 页面静态化+缓存+db实现即可
- 排队进度查看(创建订单海量,怎么解决高性能查排队进展的问题)
- 结构
- 数组A: 例大小1000
- Hash表B: 通过key查找value,通过hash函数计算得到索引位置
- 思路
- 数组A存储排队中,待创建订单的用户;数组B用作索引,存储uid对应在数组A中的索引位置
- 每次从数组A中依次消费数据,并记录最近消费的索引值X
- 用户来查排队进展时,从hash表B中取出该uid对应存储的索引值Y
- 索引值Y - 索引值X = 排队进度值
- 高性能读库存(强一致性要求低)
- 读取本地库存,无则主动拉取一次,有则返回
- 异步脚本定时同步库存至本地
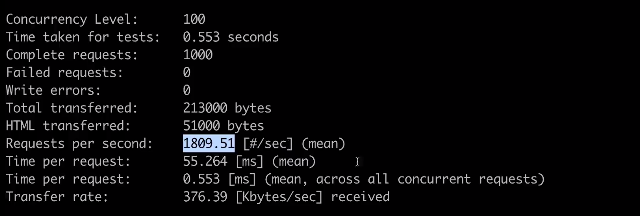
- 对接口进行压测
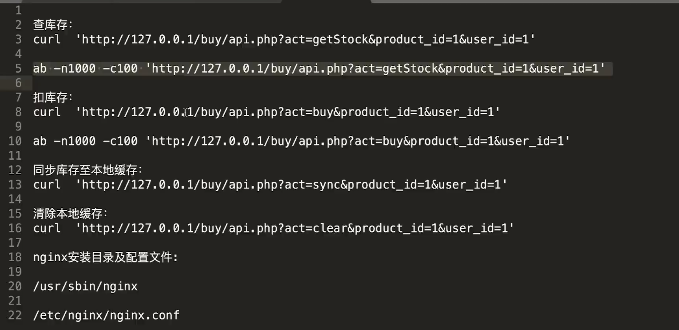
qps1800 启动了一个fpm,单进程

- 总结
- 读场景
- 读商品详情
- 读库存
- 读排队进度
- 写场景
- 扣库存
- 写订单
- 高性能服务: 单性能多携程及异步I/O方式实现的
- 链路如何实现漏斗形流量