基本概念
Hive用于解决海量结构化日志的数据统计问题。
Hive是基于Hadoop的一个数据仓库工具。本质是将HQL(Hive的查询语言)转化成MapReduce程序。
HIve处理的数据存储在HDFS
HIve分析数据底层的默认实现是MapReduce
执行程序运行在Yarn上
Hive的优缺点
优点:
可以快速进行数据分析,不需要写MapReduce程序。
MapReduce适合处理大数据,不适合处理小数据
缺点:
HQL表达能力有限,迭代式算法不能表达,粒度较粗,调优比较困难。
自定义函数类别:
- UDF
- UDAF
- UDTF
架构原理
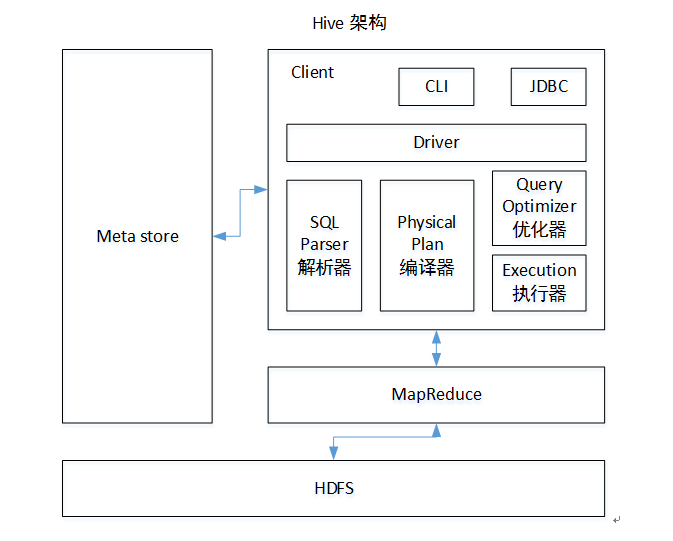
执行顺序:解析器-编译器-优化器-执行器
Hive与数据库对比
HIve相比数据库,读多写少,没有索引,需要暴力扫描所有数据,即使引入了MapReduce机制,也不适合实时查询,扩展性和Hadoop的是一致的,扩展性强。