1.常用选项:
-E :开启扩展(Extend)的正则表达式。
-i :忽略大小写(ignore case)。
-v :反过来(invert),只打印没有匹配的,而匹配的反而不打印。
-n :显示行号
-w :被匹配的文本只能是单词,而不能是单词中的某一部分,如文本中有liker,而我搜寻的只是like,就可以使用-w选项来避免匹配liker
-c :显示总共有多少行被匹配到了,而不是显示被匹配到的内容,注意如果同时使用-cv选项是显示有多少行没有被匹配到。
-o :只显示被模式匹配到的字符串。
--color :将匹配到的内容以颜色高亮显示。
-A n:显示匹配到的字符串所在的行及其后n行,after
-B n:显示匹配到的字符串所在的行及其前n行,before
-C n:显示匹配到的字符串所在的行及其前后各n行,context2.常用表达式参数
\btom\b //“\b"中间tom代表是一个单词
\d 表示一个数字
\d{2}-\d{8}。 这里\d后面的{2}({8})的意思是前面\d必须连续重复匹配2次(8次)。
\s匹配任意的空白符,包括空格,制表符(Tab),换行符,中文全角空格等。
\w匹配字母或数字或下划线或汉字等。
. 匹配除换行符以外的任意字符
\d 匹配数字
\b 匹配单词的开始或结束
^ 匹配字符串的开始 //^和$匹配的是行
$ 匹配字符串的结束
^\d{5,12}$ //填写的QQ号必须为5位到12位数字
备注:"\d"等这些字符只有在perl{正则支持的相对完整} 中能够使用
转义):
\字符
重复):
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次cat 123.txt |grep '\bno\b'
#\b 牟定词首 或者词尾,上面表示只匹配no字符,多一个都不行
cat 123.txt |grep '^root.400$'
#^牟定行首,$牟定行尾,表示匹配以root开头,以400结尾的行
echo "111222333"|grep -o 1.2
#只显示匹配到的词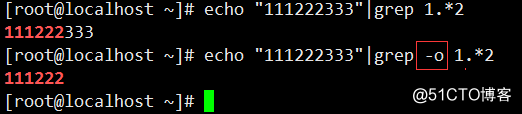
cat /etc/passwd|grep -n -A 1 '^root.*'
#显示root行,及下一行,还有行号
匹配数字
echo "123abcABC"|grep -o '[0-9]'
echo "2002 1945 1644 1892 1946"|grep -P '\b(20|19)[0-9]{2}\b'
#表示以20或者19开头后面两个字符为数字,{2}的意思是前面[0-9]必须匹配到两次,至少匹配到的是4位数,但是两个\b牟定的词首和词尾所以只能的是4位数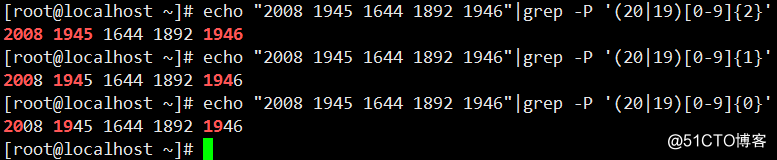
高级用法
echo "http://www.ylc520.com/"|grep -oP '.+(?=://)'
#输出结果 http, 表示以://为定界 往前匹配,.+ 表示任意字符出现1次或者多次
echo "http://www.ylc520.com/"|grep -oP '(?<=://).+'
#输出 www.ylc520.com/ ,表示以://为定界 往后匹配,.+ 表示任意字符出现1次或者多次
echo "http://www.ylc520.com/"|grep -oP '(?<=www.).(?=.com)'
#输出结果 ylc520 表示以www. 为定界往后匹配,同时以.com为定界往前匹配,.匹配任意字符任意长度