实时目标跟踪是许多计算机视觉应用的重要任务,例如监控,基于感知的用户接口,增强实现、基于对象的视频压缩以及辅助驾驶等。
基本的运动检测
import cv2
import numpy as np
camera = cv2.VideoCapture(0)
es = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (9,4))
kernel = np.ones((5,5),np.uint8)
background = None
while (True):
ret, frame = camera.read()
if background is None:
background = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
background = cv2.GaussianBlur(background, (21, 21), 0)
continue
gray_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
gray_frame = cv2.GaussianBlur(gray_frame, (21, 21), 0)
diff = cv2.absdiff(background, gray_frame)
diff = cv2.threshold(diff, 25, 255, cv2.THRESH_BINARY)[1]
diff = cv2.dilate(diff, es, iterations = 2)
image, cnts, hierarchy = cv2.findContours(diff.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for c in cnts:
if cv2.contourArea(c) < 1500:
continue
(x, y, w, h) = cv2.boundingRect(c)
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.imshow("contours", frame)
cv2.imshow("dif", diff)
if cv2.waitKey(1000 / 12) & 0xff == ord("q"):
break
cv2.destroyAllWindows()
camera.release()

注意:进行模糊处理的原因:每个输入的视频都会因自然震动、光照变化或者摄像头本身等原因而产生噪声。对噪声进行平滑是为了避免在运动和跟踪时将其检测出来
在完成对帧的灰度转换和平滑后,就可计算与背景帧的差异(背景帧也需要进行灰度转换和平滑),并得到一个差分图。还需要应用阈值来得到衣服黑白图像,并通过下面的代码膨胀图像,从而对孔和缺陷进行归一化处理:
diff = cv2.absdiff(background, gray_frame)
diff = cv2.threshold(diff, 25, 255, cv2.THRESH_BINARY)[1]
diff = cv2.dilate(diff, es, iterations = 2)
注意,侵蚀和膨胀也可用做噪声滤波器,这和上面采用的模糊技术很像,侵蚀和膨胀可通过调用cv2.morphologyEx函数来获得,为了达到透明的目的。关于这点所有剩下要做的就是计算出的差分图中找到所有白色斑点的轮廓,并显示这些轮廓。或者对于矩形区域,只显示大于给定阈值的轮廓,所以,一些微小的变化不会显示,当然,这一切最终都由应用需求觉得,对于光照不变和噪声低的摄像头,可不设定轮廓最小尺寸的阈值。 显示矩形:
image, cnts, hierarchy = cv2.findContours(diff.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for c in cnts:
if cv2.contourArea(c) < 1500:
continue
(x, y, w, h) = cv2.boundingRect(c)
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.imshow("contours", frame)
cv2.imshow("dif", diff)
OpenCV提供了两个非常有用的函数:
- cv2.findContours:该函数计算一副图像中目标的轮廓
- cv2.boundinRect:该函数计算矩形的边界框
背景分割器:KNN、MOG2、GMG
OpenCV3中有三种背景分割器:KNN、MOG2、GMG,它们对应的算法用来计算 背景分割。
之前讨论过GrabCut和Watershed对前景检测和背景检测,为什么还需要BackgroundSubtractor类?
因为BackgroundSubtractor类是专门用于视频分析的。
用BackgroundSubtractorKNN来实现运动检测
#-*- coding=utf-8 -*-
import cv2
import numpy as np
#汽车跟踪
knn = cv2.createBackgroundSubtractorKNN(detectShadows = True)
es = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (20,12))
camera = cv2.VideoCapture("surveillance_demo/traffic.flv")
def drawCnt(fn, cnt):
if cv2.contourArea(cnt) > 1400:
(x, y, w, h) = cv2.boundingRect(cnt)
cv2.rectangle(fn, (x, y), (x + w, y + h), (255, 255, 0), 2)
while True:
ret, frame = camera.read()
if not ret:
break
#背景分割器,该函数计算了前景掩码
fg = knn.apply(frame.copy())
fg_bgr = cv2.cvtColor(fg, cv2.COLOR_GRAY2BGR)
bw_and = cv2.bitwise_and(fg_bgr, frame)
draw = cv2.cvtColor(bw_and, cv2.COLOR_BGR2GRAY)
draw = cv2.GaussianBlur(draw, (21, 21), 0)
draw = cv2.threshold(draw, 10, 255, cv2.THRESH_BINARY)[1]
draw = cv2.dilate(draw, es, iterations = 2)
image, contours, hierarchy = cv2.findContours(draw.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for c in contours:
drawCnt(frame, c)
cv2.imshow("motion detection", frame)
if cv2.waitKey(1000 / 12) & 0xff == ord("q"):
break
camera.release()
cv2.destroyAllWindows()
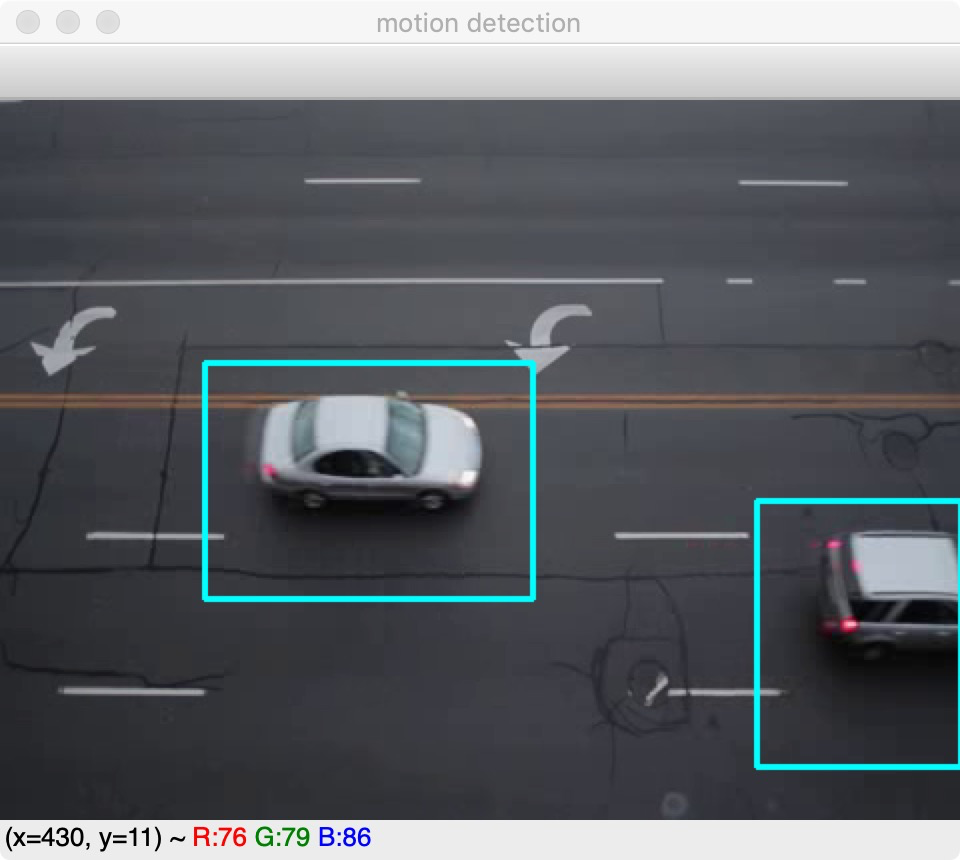
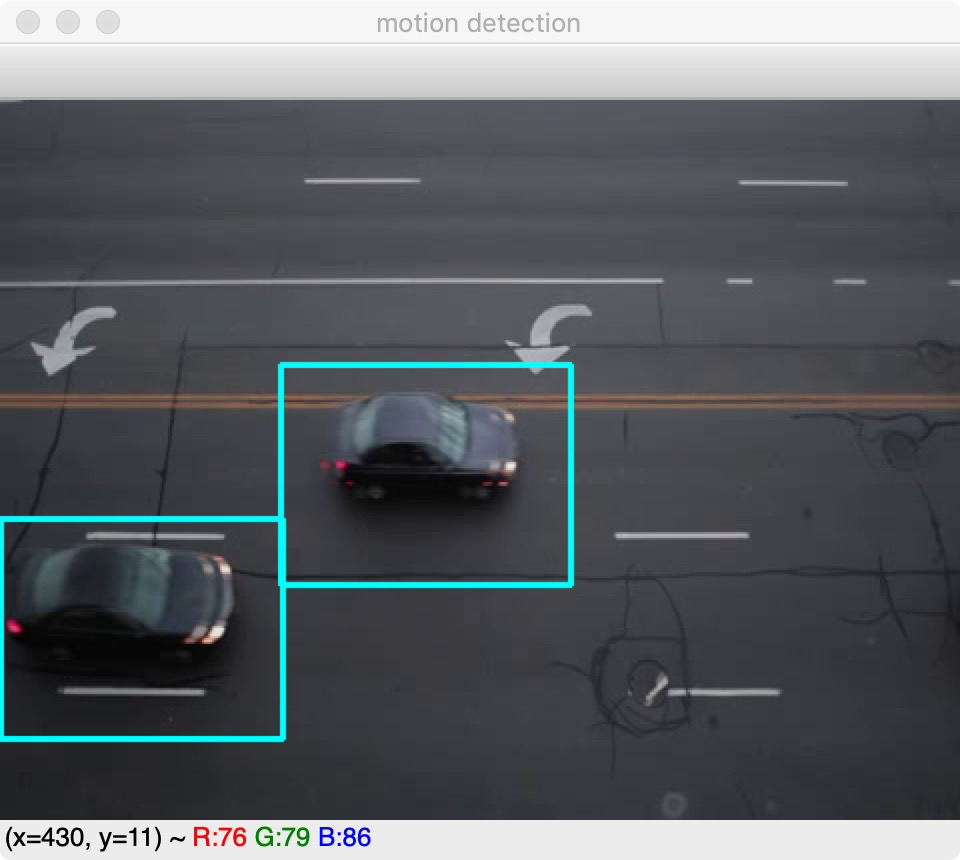
一旦获得了前景掩码,就可设定阈值:前景掩码含有前景的白色值以及阴影的灰色值,因此,在阈值化图像中,将非纯白色(244~255)的所有像素都设为0,而不是为1.
均值漂移和CAMShift
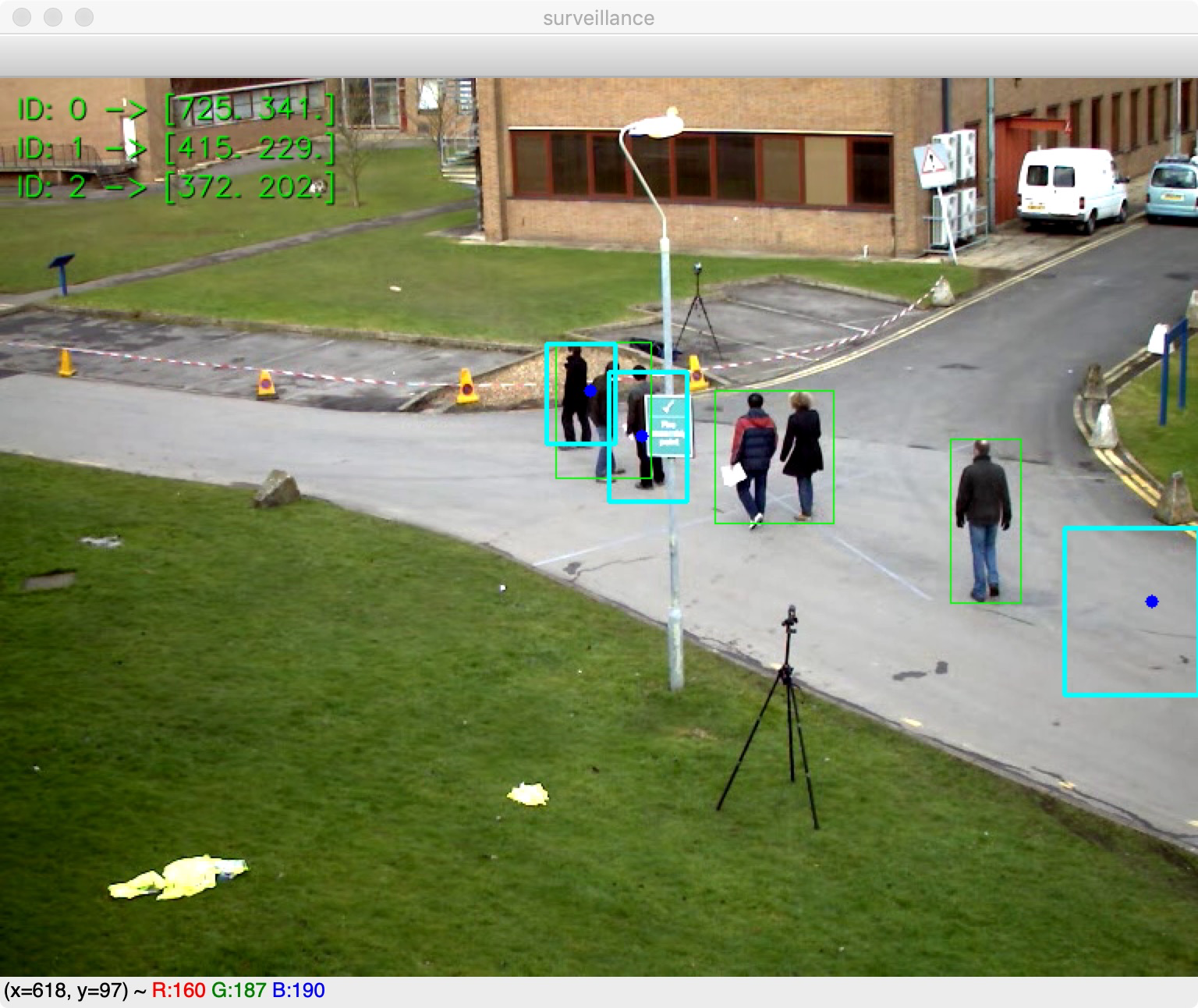
背景分割是一种非常有效的技术,但并不是进行视频中目标跟踪唯一可用的技术,均值漂移是一种目标跟踪算法,该算法寻找概率函数离散样本的最大密度(例如,感兴趣的图像区域),并且重新计算在下一帧中的最大密度,该算法给出了目标的移动方向。
步骤:
- 1.检查第一帧
- 2.检查后面输入的帧,从场景的开始通过背景分割器来识别场景中的行人。
- 3.为每个行人建立ROI,并利用Kalman/CAMShift来跟踪行人ID。
- 4.检查下一帧是否有进入场景的新行人
#! /usr/bin/python
"""Surveillance Demo: Tracking Pedestrians in Camera Feed
The application opens a video (could be a camera or a video file)
and tracks pedestrians in the video.
"""
__author__ = "joe minichino"
__copyright__ = "property of mankind."
__license__ = "MIT"
__version__ = "0.0.1"
__maintainer__ = "Joe Minichino"
__email__ = "[email protected]"
__status__ = "Development"
import cv2
import numpy as np
import os.path as path
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("-a", "--algorithm",
help = "m (or nothing) for meanShift and c for camshift")
args = vars(parser.parse_args())
def center(points):
"""calculates centroid of a given matrix"""
x = (points[0][0] + points[1][0] + points[2][0] + points[3][0]) / 4
y = (points[0][1] + points[1][1] + points[2][1] + points[3][1]) / 4
return np.array([np.float32(x), np.float32(y)], np.float32)
font = cv2.FONT_HERSHEY_SIMPLEX
class Pedestrian():
"""Pedestrian class
each pedestrian is composed of a ROI, an ID and a Kalman filter
so we create a Pedestrian class to hold the object state
"""
def __init__(self, id, frame, track_window):
"""init the pedestrian object with track window coordinates"""
# set up the roi
self.id = int(id)
x,y,w,h = track_window
self.track_window = track_window
self.roi = cv2.cvtColor(frame[y:y+h, x:x+w], cv2.COLOR_BGR2HSV)
roi_hist = cv2.calcHist([self.roi], [0], None, [16], [0, 180])
self.roi_hist = cv2.normalize(roi_hist, roi_hist, 0, 255, cv2.NORM_MINMAX)
# set up the kalman
self.kalman = cv2.KalmanFilter(4,2)
self.kalman.measurementMatrix = np.array([[1,0,0,0],[0,1,0,0]],np.float32)
self.kalman.transitionMatrix = np.array([[1,0,1,0],[0,1,0,1],[0,0,1,0],[0,0,0,1]],np.float32)
self.kalman.processNoiseCov = np.array([[1,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,1]],np.float32) * 0.03
self.measurement = np.array((2,1), np.float32)
self.prediction = np.zeros((2,1), np.float32)
self.term_crit = ( cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 1 )
self.center = None
self.update(frame)
def __del__(self):
print "Pedestrian %d destroyed" % self.id
def update(self, frame):
# print "updating %d " % self.id
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
back_project = cv2.calcBackProject([hsv],[0], self.roi_hist大专栏 OpenCV目标跟踪 - 黄超贤 class="p">,[0,180],1)
if args.get("algorithm") == "c":
ret, self.track_window = cv2.CamShift(back_project, self.track_window, self.term_crit)
pts = cv2.boxPoints(ret)
pts = np.int0(pts)
self.center = center(pts)
cv2.polylines(frame,[pts],True, 255,1)
if not args.get("algorithm") or args.get("algorithm") == "m":
ret, self.track_window = cv2.meanShift(back_project, self.track_window, self.term_crit)
x,y,w,h = self.track_window
self.center = center([[x,y],[x+w, y],[x,y+h],[x+w, y+h]])
cv2.rectangle(frame, (x,y), (x+w, y+h), (255, 255, 0), 2)
self.kalman.correct(self.center)
prediction = self.kalman.predict()
cv2.circle(frame, (int(prediction[0]), int(prediction[1])), 4, (255, 0, 0), -1)
# fake shadow
cv2.putText(frame, "ID: %d -> %s" % (self.id, self.center), (11, (self.id + 1) * 25 + 1),
font, 0.6,
(0, 0, 0),
1,
cv2.LINE_AA)
# actual info
cv2.putText(frame, "ID: %d -> %s" % (self.id, self.center), (10, (self.id + 1) * 25),
font, 0.6,
(0, 255, 0),
1,
cv2.LINE_AA)
def main():
# camera = cv2.VideoCapture(path.join(path.dirname(__file__), "traffic.flv"))
camera = cv2.VideoCapture(path.join(path.dirname(__file__), "768x576.avi"))
# camera = cv2.VideoCapture(path.join(path.dirname(__file__), "..", "movie.mpg"))
# camera = cv2.VideoCapture(0)
history = 20
# KNN background subtractor
bs = cv2.createBackgroundSubtractorKNN()
# MOG subtractor
# bs = cv2.bgsegm.createBackgroundSubtractorMOG(history = history)
# bs.setHistory(history)
# GMG
# bs = cv2.bgsegm.createBackgroundSubtractorGMG(initializationFrames = history)
cv2.namedWindow("surveillance")
pedestrians = {}
firstFrame = True
frames = 0
fourcc = cv2.VideoWriter_fourcc(*'XVID')
out = cv2.VideoWriter('output.avi',fourcc, 20.0, (640,480))
while True:
print " -------------------- FRAME %d --------------------" % frames
grabbed, frame = camera.read()
if (grabbed is False):
print "failed to grab frame."
break
fgmask = bs.apply(frame)
# this is just to let the background subtractor build a bit of history
if frames < history:
frames += 1
continue
th = cv2.threshold(fgmask.copy(), 127, 255, cv2.THRESH_BINARY)[1]
th = cv2.erode(th, cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3,3)), iterations = 2)
dilated = cv2.dilate(th, cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (8,3)), iterations = 2)
image, contours, hier = cv2.findContours(dilated, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
counter = 0
for c in contours:
if cv2.contourArea(c) > 500:
(x,y,w,h) = cv2.boundingRect(c)
cv2.rectangle(frame, (x,y), (x+w, y+h), (0, 255, 0), 1)
# only create pedestrians in the first frame, then just follow the ones you have
if firstFrame is True:
pedestrians[counter] = Pedestrian(counter, frame, (x,y,w,h))
counter += 1
for i, p in pedestrians.iteritems():
p.update(frame)
firstFrame = False
frames += 1
cv2.imshow("surveillance", frame)
out.write(frame)
if cv2.waitKey(110) & 0xff == 27:
break
out.release()
camera.release()
if __name__ == "__main__":
main()
-
该进程的核心自傲与背景分割对象,它能识别感兴趣的区域和与之相对应的运动目标。 当进程启动时,会提取每个区域,实例化Pedestrian类,传递ID,帧以及跟踪窗口的坐标,进而提取ROI的HSV直方图。
-
计算给定ROI的直方图,设置卡尔曼滤波器,并将其与对象的属性(self.kalman)关联
-
在update方法中,传递当前帧并将其装换为HSV,这样可以计算行人HSV直方图的反向投影。
-
使用CAMShift或均值漂移来跟踪行人的运动,并根据 行人的实际位置校正卡尔曼滤波器。
- 以点的形式来绘制CAMShift/均值漂移(包括周围的矩形)和卡尔曼滤波器,因此可以看到卡尔曼滤波器和CAMShift/均值漂移一点点接近,除非突然的动作会导致卡尔曼滤波器重新调整。
- 最后在图像的左上角打印行人的信息。