1.采用哪些方式可以获取大数据?
(1)通过业务系统或者互联网端的服务器自动汇聚(系统日志采集,网络数据采集(通过网络爬虫实现)),如业务数据、用户行为数据等。
(2)通过卫星、摄像机和传感器等硬件设备自动汇聚,如遥感数据、交通数据等。
(3)通过整理汇聚,如商业景气数据、人口普查数据等。
2.常用大数据采集工具有哪些?
(1)Apache Chukwa,一个针对大型分布式系统的数据采集系统,其构建在Hadoop之上,使用HDFS作为存储。
(2)Flume,一个功能完备的分布式日志采集、聚合和传输系统。在Flume中,外部输入称为Source(源),系统输出称为Sink(接收端),Channel(通道)将源和接收端链接在一起。
(3)Scrible,facebook开源的日志收集系统。
(4)Kafka,当下流行的分布式发布、订阅消息系统,也可用于日志聚合。不仅具有高可拓展性和容错性,而且具有很高的吞吐量。特点是快速的、可拓展的、分布式的、分区的和可复制的。
3.简述什么是Apache Kafka数据采集。
Apache Kafka 是当下流行的分布式发布、订阅消息系统,被设计成能够高效地处理大量实时数据,其特点是快速的、可拓展的、分布式的、分区的和可复制的。Kafka是用Scala语言编写的,虽然置身于Java阵营,但其并不遵循JMS规范。

4.Topic可以有多少个分区,这些分区有什么用?
一个Topic可以有多个分区,这些分区可以作为并行处理的单元,从而使Kafka有能力高效地处理大量数据。
5.Kafka抽象具有哪种模式的特征消费组?
Kafka提供一种单独的消费者抽象,此抽象具有两种模式的特征消费组:Queuing和Publish-Subscribe。
6.简述数据预处理的原理。
数据预处理(Data Preprocessing)是指在对数据进行挖掘以前,需要对原始数据进行清理、集合和变换等一系列处理工作,以达到挖掘算法进行知识获取研究所要求的最低规范和标准。通过数据预处理工作,可以使残缺的数据完整,并将错误的数据纠正、多余的数据去除,进而将所需的数据进行数据集成。数据预处理的常见方法有数据清洗、数据集成和数据变换。
7.数据清洗有哪些方法?
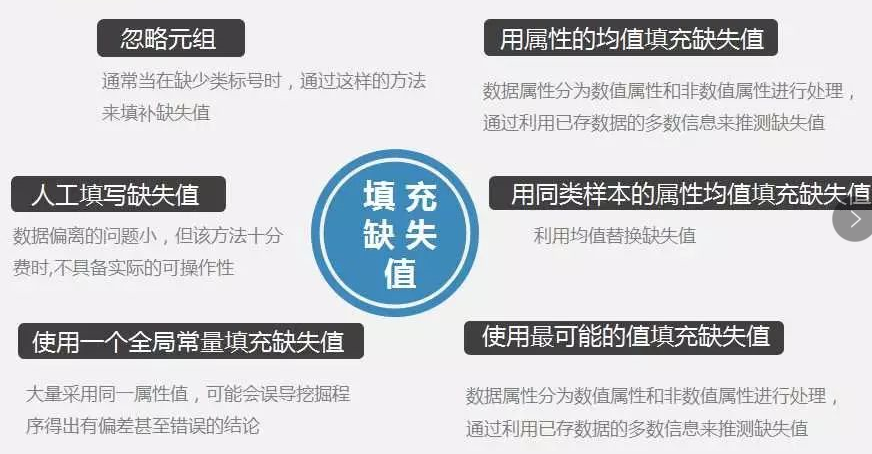
(1)填充缺失值。常用处理方法:忽略元组、人工填写缺失值、使用一个全局变量填充缺失值、用属性的均值填充缺失值、用同类样本的属性均值填充缺失值、使用最可能的值填充缺失值。
(2)光滑噪声数据。方法:分箱、回归、聚类。
(3)数据清洗过程,包括检测偏差和纠正偏差。


8.数据集成需要重点考虑的问题有哪些?
9.数据变换主要涉及哪些内容?
10.分别简述常用ETL工具。