摘要:无监督图像转换是计算机视觉领域中一个重要而又具有挑战性的问题。给定源域中的一幅图像,目标是学习目标域中对应图像的条件分布,而不需要看到任何对应图像对的例子。虽然这种条件分布本质上是多模态的,但现有的方法做了过度简化的假设,将其建模为确定性的一对一映射。因此,它们无法从给定的源域映像生成不同的输出。为了解决这一局限性,我们提出了一个多模态无监督图像到图像的转换(MUNIT)框架。我们假设可以将图像表示分解为域不变的内容代码和捕获特定域属性的样式代码。为了将图像转换到另一个域,我们将其内容代码与从目标域的样式空间中采样的随机样式代码重新组合。我们分析了提出的框架,并建立了几个理论结果。大量的实验与最先进的方法进行了比较,进一步证明了该框架的优势。此外,我们的框架允许用户通过提供一个示例样式图像来控制转换输出的样式。代码和预训练的模型是有用的-可以在https://github.com/nvlabs/MUNIT找到。
1 Introduction
在计算机视觉领域中的很多问题旨在将一张图像从一个域转换到另一个域,包括图像的超分辨率转换、颜色转换、图像修复、属性转换、风格转换等。因此,这种跨域图像到图像的转换设置受到了极大的关注[6-25]。当数据集包含成对的示例时,可以使用条件生成模型[6]或简单回归模型[13]来处理这个问题。在这里,我们关注的是更具有挑战性的设置,即当这种监督是不可用的。
在许多场景中,感兴趣的跨域映射是多模式的。例如,由于天气、时间、光线等原因,冬季场景在夏季可能会出现很多不同的样子。不幸的是,现有的技术通常采用确定性[8-10]或单峰[15]映射。结果,它们未能捕获可能输出的全部分布。即使通过注入噪声使模型变得随机,网络通常也会忽略它[6,26]。
本文针对多模态无监督图像-图像转换问题,提出了一个原则性框架。如图1 (a)所示:
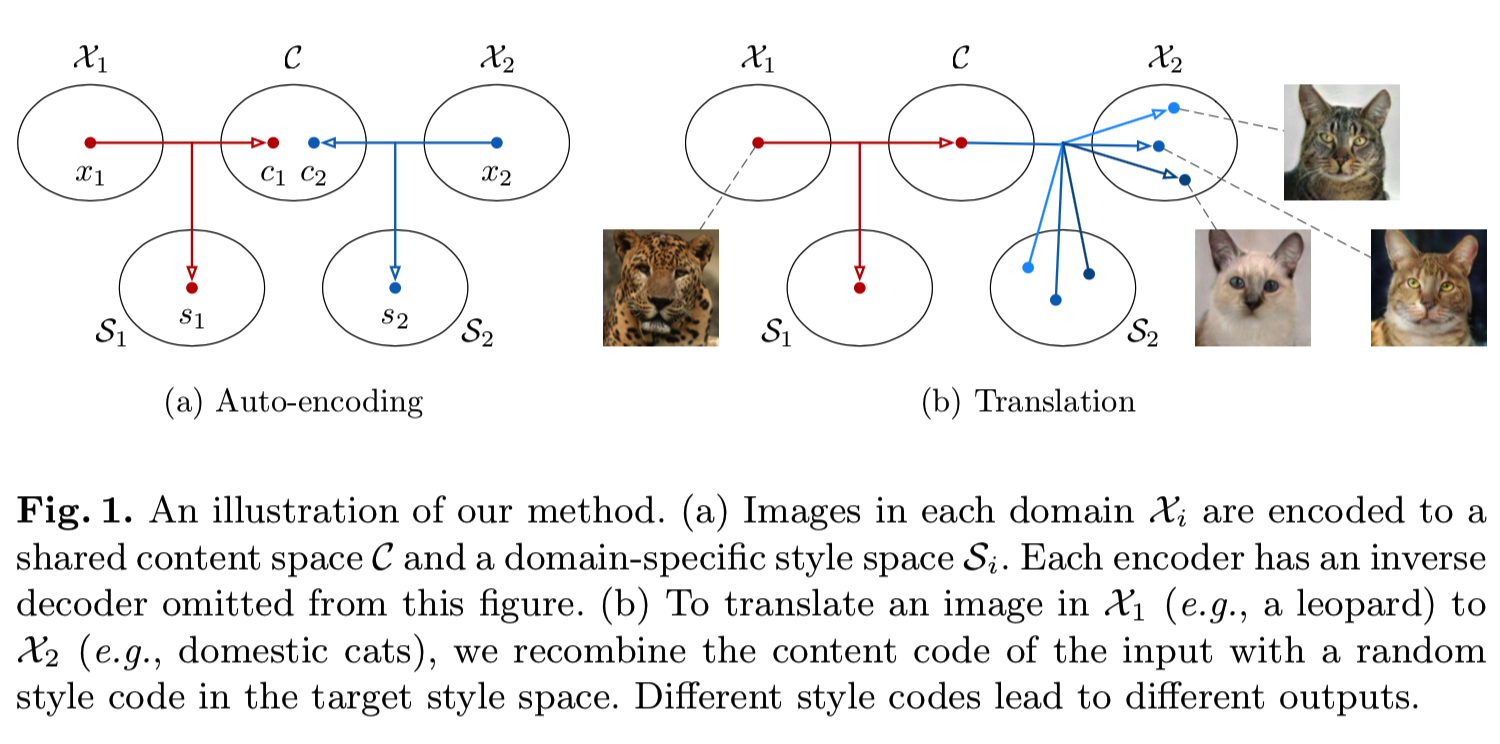
我们的框架做了几个假设。我们首先假设图像的潜空间可以分解为内容空间和风格空间。我们进一步假设不同域中的图像共享一个公共的内容空间,而不是样式空间。为了将图像转换到目标域,我们将其内容编码与目标样式空间中的随机样式编码重新组合(图1 (b))。内容代码编码在转换期间应该保留的信息,而样式代码表示输入图像中不包含的其余变体。通过采样不同的风格编码,我们的模型能够产生不同的和多模态的输出。大量的实验证明了我们的方法在多模态输出分布建模中的有效性,以及与目前最先进的方法相比,它具有更好的图像质量。此外,内容和样式空间的分解允许我们的框架执行样例引导的图像转换,其中转换输出的样式由用户提供的目标域中的示例图像控制。
2 Related Works
Generative adversarial networks (GANs)生成对抗网络. GAN框架[27]在图像生成方面取得了良好的效果。在GAN训练中,一个生成器被训练来欺骗一个判别器,而判别器反过来又试图区分生成的样本和真实样本。已经提出了对GANs的各种改进,如多阶段生成[28-33]、更好的训练目标[34-39]以及与自动编码器的结合[40-44]。在这项工作中,我们使用GANs将转换后的图像与目标域中的真实图像进行对齐。
Image-to-image translation. Isola等人[6]提出了第一个基于条件GANs的图像到图像转换的统一框架,Wang等人将其扩展到生成高分辨率的图像。最近的研究也试图在没有监督的情况下学习图像转换。这个问题本质上是不适定的,需要额外的约束。一些工作强制转换以保留源域数据的某些属性,如像素值[21]、像素梯度[22]、语义特征[10]、类标签[22]或成对样本距离[16]。另一个常见的约束是周期一致性损失[7-9]。它强制要求,如果我们将一个图像转换到目标域并返回,我们应该获得原始图像。此外,Liu等人提出了UNIT框架,该框架假设一个共享的潜在空间,使得两个域中对应的图像映射到相同的潜在编码。
现有的大多数图像到图像的转换方法的一个重要限制是转换输出的多样性。为了解决这个问题,一些研究建议在相同的输入下同时产生多个输出,并鼓励它们不同[13,45,46]。尽管如此,这些方法只能生成离散数量的输出。Zhu等人提出了一种可以对连续分布和多模态分布进行建模的双循环模型。但是,上述所有方法都需要成对监督数据,而我们的方法不需要。一些同时进行的工作也认识到了这一局限性,并提出了CycleGAN/UNIT在多模态映射[47]/[48]中的扩展。
我们的问题与多域图像到图像的转换有关[19,49,50]。具体来说,当我们知道每个域有多少个模式,每个样本属于哪个模式时,就可以将每个模式视为一个单独的域,利用多域图像到图像的转换技术来学习每一对模式之间的映射,从而实现多模态转换。然而,一般来说,我们并不认为这些信息是可用的。此外,我们的随机模型可以表示连续的输出分布,而[19,49,50]仍然对每一对域使用确定性模型。
Style transfer. 风格转换的目的是在保留图像内容的同时修改图像的风格,这与图像之间的转换密切相关。在这里,我们区分了示例引导的风格转换(目标样式来自单个示例)和集合样式转换(目标样式由一组图像定义)。经典的风格转换方法[5,51 - 56]通常处理前者问题,而图像到图像的转换方法已被证明在后者的[8]中表现良好。我们将展示我们的模型能够解决这两个问题,这得益于它对内容和样式的清晰表示。
Learning disentangled representations. 我们的工作从最近关于解耦表征学习的著作中获得灵感。例如,InfoGAN[57]和β-VAE[58]提出了在没有监督的情况下学习解耦表征。其他一些作品[59-66]侧重于将内容从风格中解耦出来。虽然很难定义内容/风格,不同的作品有不同的定义,但我们将“内容”称为底层空间结构,将“风格”称为结构的渲染。在我们的设置中,有两个域共享相同的内容分布,但具有不同的样式分布。
3 Multimodal Unsupervised Image-to-image Translation
3.1 Assumptions
令x1∈Χ1, x2∈X2是来自两个不同图像域的图像。在无监督的图像到图像的转移设置中,我们从两个边缘分布p(x1)和p(x2)中抽取样本,不访问联合分布p(x1,x2)。我们的目标是使用习得的图像-图像转换模型p(x1→2|x1)和p(x2→1|x2)来估计p(x2|x1)和p(x1|x2)两个条件句,其中x1→2是将x1转换为x2产生的样本(类似于x2→1)。一般来说,p(x2|x1)和p(x1|x2)是复杂的多模态分布,在这种情况下,确定性转换模型不能很好地工作。
为了解决这个问题,我们做了一个部分共享的潜在空间假设。具体来说,我们假设每个图像xi∈Xi是由两个域共享的一个内容潜在编码c∈C和一个特定于单个域的风格潜码si∈Si生成的。换句话说,来自联合分布的一对相应的图像(x1,x2)是由x1 = G∗1(c,s1)和x2 = G∗2(c,s2)生成的,其中c,s1,s2是来自一些以前的分布,G∗1,G∗2是底层的生成器。我们进一步假设G∗1和G∗2是确定性函数,它们的逆编码器是E∗1= (G∗1)-1和E∗2= (G∗2)-1。我们的目标是学习底层带有神经网络的生成器和编码器函数。注意,尽管编码器和解码器是确定性的,但由于s2的依赖性,p(x2|x1)是一个连续的分布。
我们的假设与UNIT[15]中提出的共享潜在空间假设密切相关。虽然UNIT假设了一个完全共享的潜在空间,但是我们假设只有部分潜在空间(内容)可以跨域共享,而其他部分(样式)是特定于域的,当跨域映射是多对多时,这是一个更合理的假设。
3.2 Model
图2展示了我们的模型及其学习过程的概述:
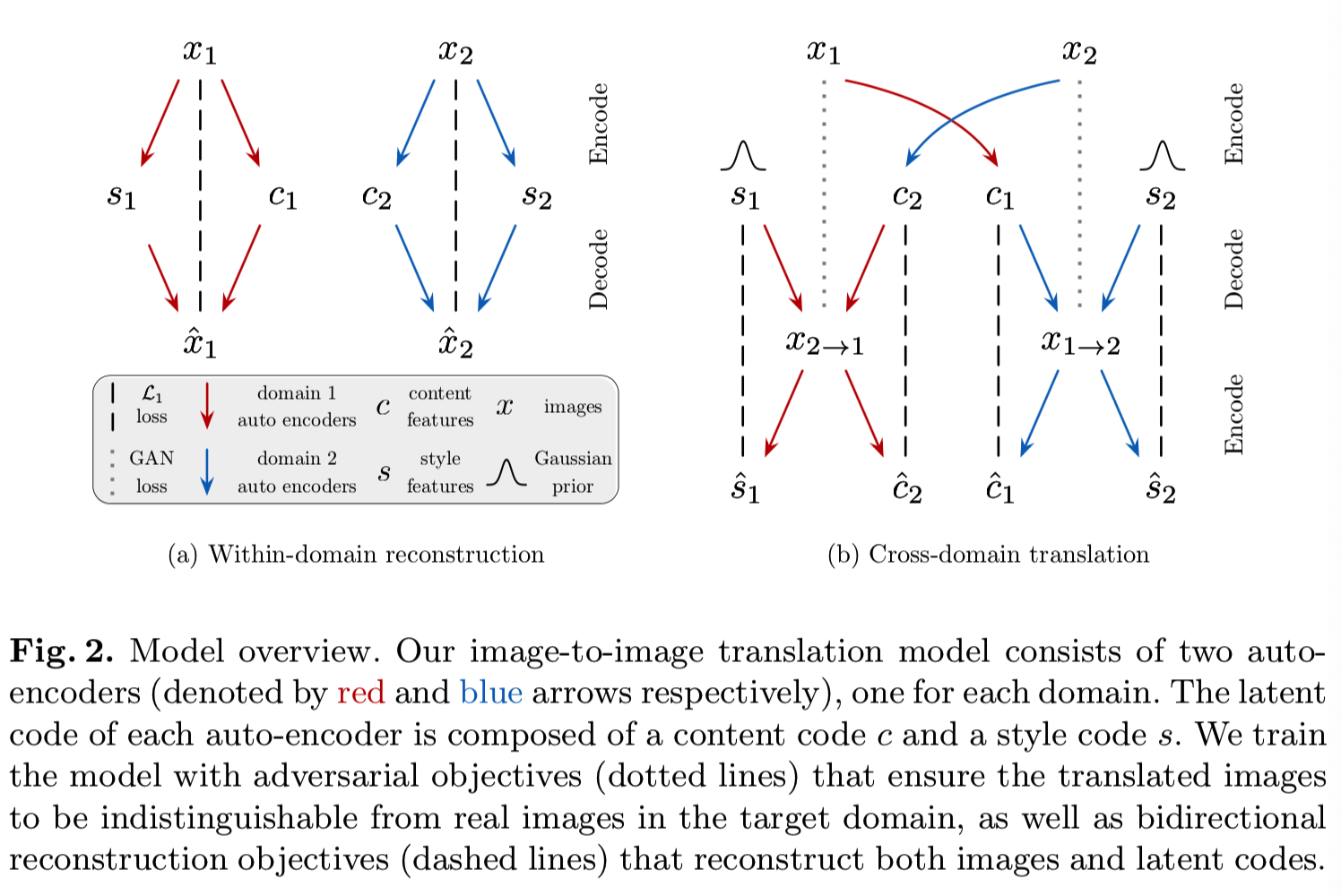
类似于Liu等人[15],我们的转换模型包含用于每个域 Xi (i = 1, 2)的Ei编码器和译码器Gi。如图2(a)所示,每个自动编码器的潜在编码——编码器映像成内容编码si和样式编码ci,在(ci, si) =(Eis (Xi), Eis (Xi)) = Ei (Xi)。图像到图像的转换是由交换encoder-decoder对实现的,如图2中所示(b)。例如,将一个图像x1∈X1转换为X2,我们首先提取其内容潜在编码c1 = Ec1 (x1)和随机绘制来自先验分布q (s2)∼N(0, I)的风格潜在编码s2。然后,我们使用G2生成最终的输出图像x1→2 = G2 (c1, s2)。我们注意到,虽然先验分布是单模态的,但由于解码器的非线性,输出图像的分布可以是多模态的。
我们的损失函数包括一个双向的重建损失,确保编码器和解码器是反向的,以及一个将转换图像的分布匹配到目标域中的图像分布的对抗性损失。
Bidirectional reconstruction loss双向重建损失. 为了了解编码器和解码器之间的反方向关系,我们使用了目标函数,该函数鼓励在 图像→潜在编码→图像(图像重构) 和潜在编码→图像→潜在编码 上进行重构:
Image reconstruction图像重构. 给定一个从数据分布中采样的图像,我们应该能够在编码和解码后重建它。
![]()
Latent reconstruction潜在编码重构. 给定一个在转换时从潜在分布中抽取的潜在编码(风格和内容),我们应该能够在解码和编码后对其进行重构。
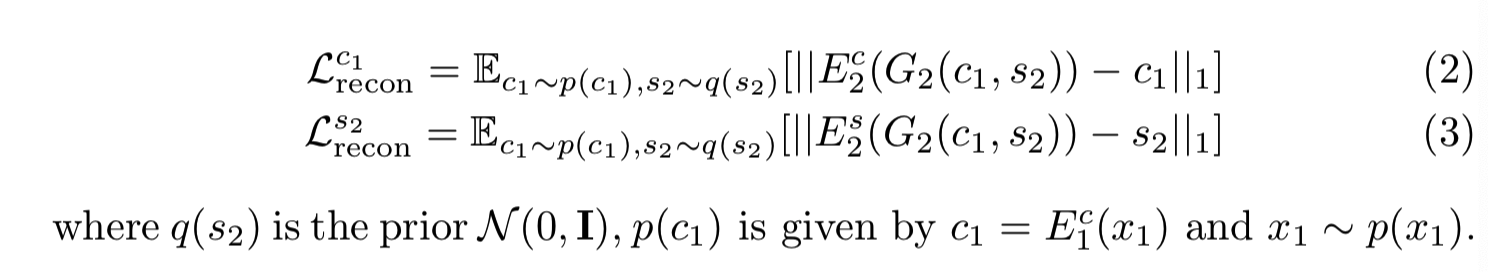
我们注意到其他损失术语Lx2recon、Lc2recon和Ls1recon的定义方式类似。我们使用L1重构损失,因为它鼓励清晰的输出图像。
Ls1recon的风格重建损失让人联想到之前研究[11,31,44,57]中使用的潜在重建损失。它鼓励不同的输出具有不同的风格代码。内容重构损失Lc2recon鼓励转换后的图像保留输入图像的语义内容。
Adversarial loss对抗损失. 我们使用GANs来匹配转换后图像的分布到目标数据的分布。换句话说,我们的模型生成的图像应该与目标域中的真实图像难以区分。
![]()
D2是尝试去区分转换后图像和X2中的真实图像的判别器。D1和损失Lx2GAN的定义是相似的
Total loss总体损失. 我们联合去训练编码器、解码器和判别器来优化最终目标,即对抗性损失和双向重构损失项的加权和。
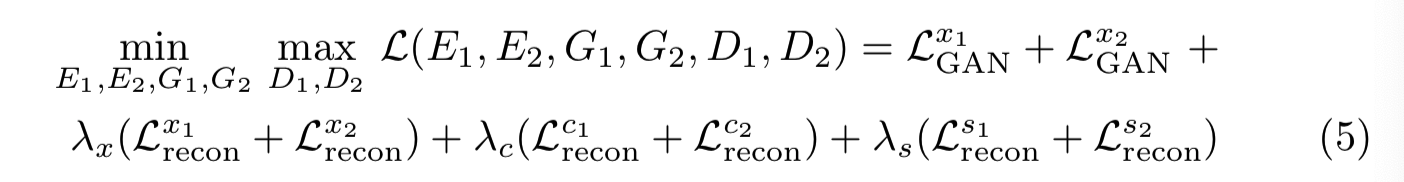
λx、λc和λs是控制重构项重要性的权重
4 Theoretical Analysis
我们现在建立了框架的一些理论性质。具体地,我们证明了最小化所提出的损失函数会导致:
1)编码和生成过程中潜在分布的匹配
2)由我们的框架引起的两个联合图像分布的匹配
3)强制一个弱形式的循环一致性约束。
所有的证明都在附录A中给出。
首先,我们注意到,当转换后的分布与数据分布匹配且编码器和译码器为逆时,Eq.(5)中的总损失最小。
Proposition命题 1 . 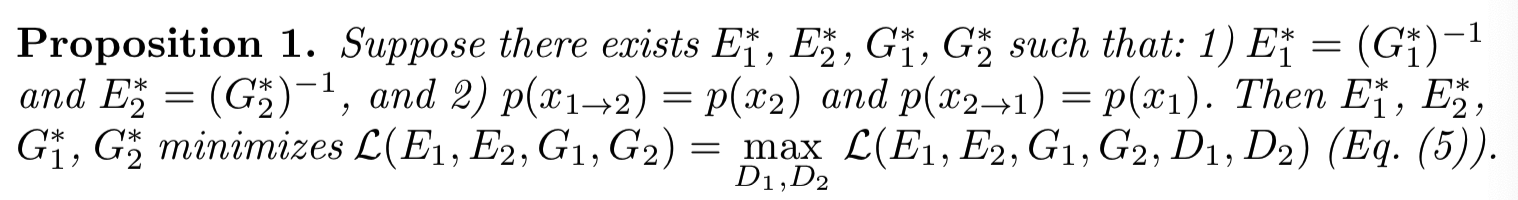
Latent Distribution Matching潜在分布匹配. 在图像生成方面,现有的自动编码器和GANs相结合的研究需要将编码的潜在分布与解码器在生成时接收到的潜在分布进行匹配,在潜在空间中使用KLD损失[15,40]或对抗损耗[17,42]。如果解码器在生成过程中接收到一个非常不同的潜在分布,那么自动编码器训练将无助于GAN训练。虽然我们的损失函数不包含明确鼓励潜在分布匹配的项,但它具有隐式匹配它们的效果。
Proposition命题 2 .
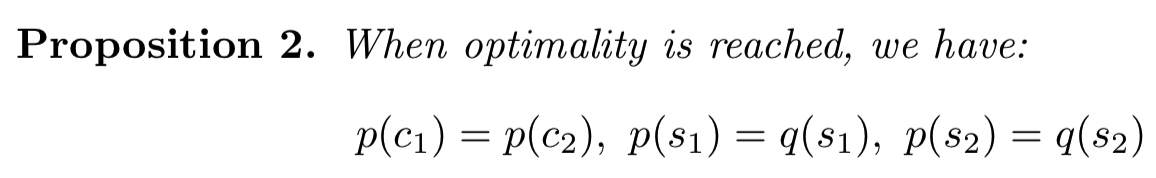
上述命题表明,编码后的风格分布在最优解上与它们的高斯先验相匹配。此外,编码的内容分布与生成时的分布相匹配,即来自其他域的编码分布。这表明内容空间变成了域不变的。
联合分布匹配Joint Distribution Matching. 我们的模型学习了两个条件分布p(x1→2|x1)和p(x2→1|x2),它们与数据分布一起定义了两个联合分布p(x1,x1→2)和p(x2→1,x2)。由于它们都被设计成近似相同的潜在联合分布p(x1,x2),因此它们彼此一致是可取的,即 p(x1, x1→2)= p(x2→1,x2)
联合分布匹配为无监督图像到图像的转换提供了一个重要的约束条件,是近年来许多方法成功的基础。在这里,我们证明了我们的模型与联合分布的最优解相匹配。
Proposition命题 3 .
![]()
Style-augmented Cycle Consistency风格增强的循环一致性. 联合分布匹配可以通过循环一致性约束[8]来实现,假设转换模型是确定的,边缘是匹配的[43,67,68]。然而,我们注意到这个约束对于多模态图像的转换来说太大了。事实上,我们在附录A中证明了,如果强制执行循环一致性,转换模型将退化为确定函数。在接下来的命题中,我们证明了我们的框架允许一种较弱形式的循环一致性,即图像风格扩展的循环一致性,它存在于图像风格联合空间中,更适合于多模态图像的转换。
Proposition命题 4 .

直观地说,风格增强的循环一致性意味着,如果我们将图像转换到目标域并使用原始风格将其转换回来,我们应该获得原始图像。风格增强的循环一致性是隐含的双向重建损失,但显式执行它可能对某些数据集有用:
![]()
5 Experiments
5.1 Implementation Details
图3显示了我们的自动编码器的结构。它由内容编码器、样式编码器和联合解码器组成。我们还在PyTorch[69]中提供了一个开源的实现,https://github.com/nvlabs/MUNIT。
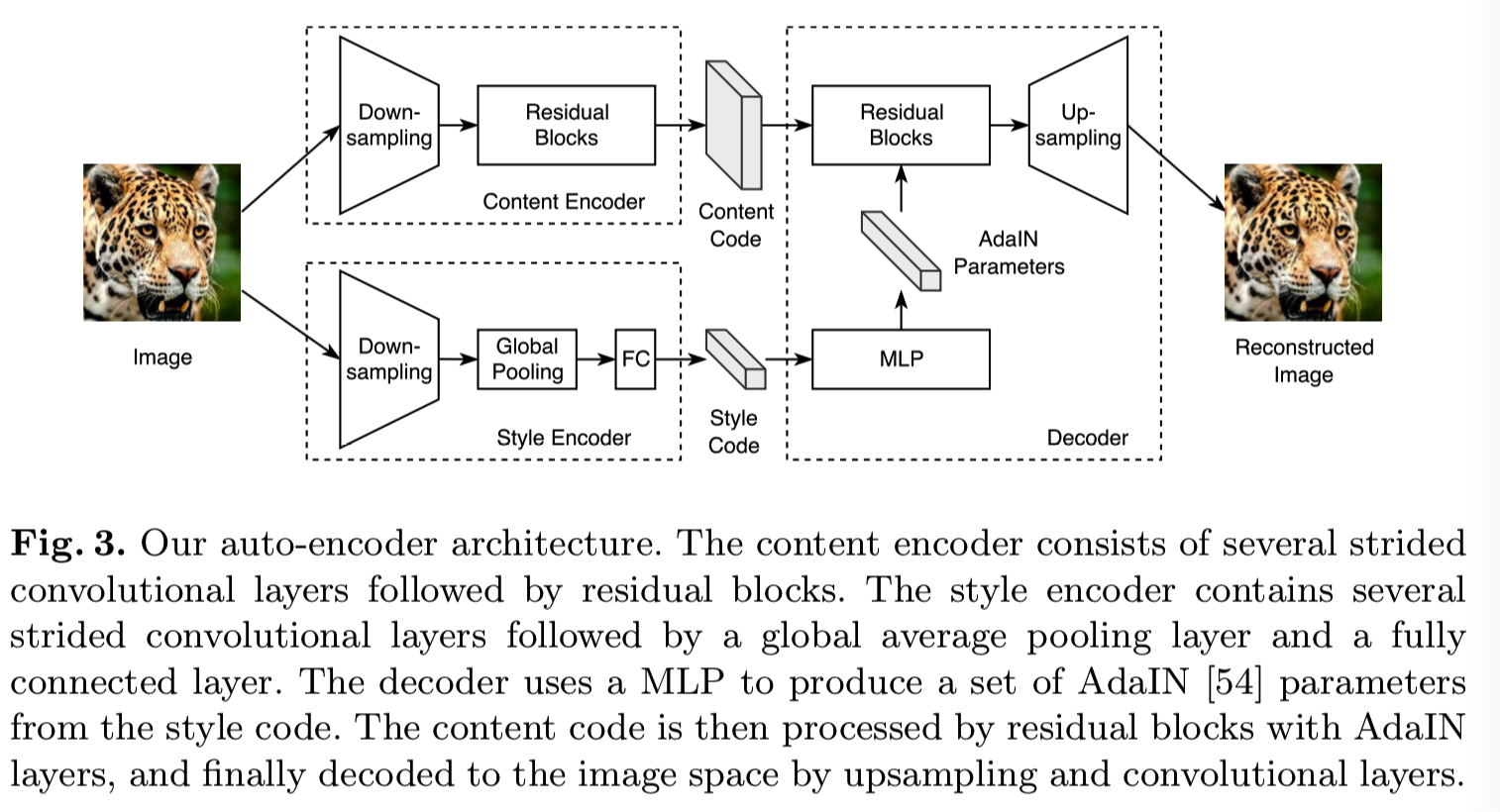
内容编码器Content encoder. 我们的内容编码器由几个步长卷积层来对输入进行下采样,以及几个残差块[70]来进一步处理它。所有的卷积层之后都跟着instance normalization(IN)[71]。
风格编码器Style encoder. 该风格编码器包括几个步长卷积层,接着是一个全局平均池化层和一个全连接(FC)层。我们风格编码器中不使用IN层,因为IN移除了代表重要的风格信息的原始的特征均值和方差[54]。
解码器Decoder. 我们的解码器从输入图像的内容和样式编码中重建图像。它通过一组残差块对内容编码进行处理,最后通过几个上采样层和卷积层生成重构图像。受最近在归一化层中使用仿射变换参数来表示风格的研究[54,72 - 74]启发,我们使用自适应实例归一化(AdaIN)[54]层来装备残差块,其参数由多层感知器(MLP)从风格代码中动态生成。

z是之前的卷积层的激活,μ、σ是基于channel求得的平均值和标准偏差,γ和β是有MLP产生的参数。请注意,仿射参数是由一个学习网络生成的,而不是像Huang等人的[54]那样从一个预先训练的网络的统计数据中计算出来的。
判别器Discriminator. 我们使用了Mao等人提出的LSGAN目标。我们使用Wang等人提出的多尺度判别器来引导生成器生成真实的细节和正确的全局结构。
域不变的感知损失Domain-invariant perceptual loss. 感知损失通常计算为输出和参考图像之间的VGG[75]特征空间的距离,已经证明当成对监督可用时,其对图像到图像的转换是有益的[13,20]。然而,在无监督的情况下,我们在目标域中没有参考图像。我们提出了一种改进的感知损失模型,它具有更强的域不变性,因此我们可以使用输入图像作为参考。具体来说,在计算距离之前,我们对VGG特征进行instance normalization[71](不进行仿射变换),以去除包含大量具体域相关信息的原始特征均值和方差[54,76]。在附录C中,我们定量地展示了instance normalization确实可以使VGG特性更具有域不变性。我们在高分辨率(≥512×512)数据集上发现了域不变感知损失加速训练,并将其应用于这些数据集。
5.2 Evaluation Metrics
人类偏好Human Preference. 为了比较不同方法生成的转换输出的真实性和忠实性,我们在Amazon Mechanical Turk (AMT)进行了人类感知研究。与Wang等人的[20]类似,工作人员得到一个输入图像和两个来自不同方法的转换输出。然后给他们无限的时间来选择哪个转换输出看起来更准确。对于每个比较,我们随机产生500个问题,每个问题由5个不同的工作人员回答。
LPIPS距离。为了测量转换多样性,我们计算了与Zhu等人[11]相同输入的随机抽样转换输出对之间的平均LPIPS距离[77]。LPIPS由图像深度特征间的L2加权距离给出。已有研究表明,这与人类的感知相似性密切相关[77]。在Zhu等人的[11]之后,我们使用了100个输入图像,并从每个输入从采样19个输出对,总共有1900对。我们使用imagenet预训练模型AlexNet[78]作为深度特征提取器。
(有条件的) Inception分数。Inception分数(IS)[34]是图像生成任务的流行度量。我们提出了一个改进的版本,称为Conditional Inception Score(CIS),它更适合于评估多模态图像的转换。当我们知道X2中的模式数以及每个样本所属的真实模式时,我们可以训练一个分类器p(y2| X2)将图像X2分类为其模式y2。条件即对于一个输入图像x1,其转换样本x1→2应该被模式覆盖(因此p (y2 | x1) =∫p (y | x1→2) p (x1→2 | x1) dx1→2应该有高的熵值)和每个样本应该属于一个特定的模式(因此p (y2 | x1→2)应该有低的熵值)。结合这两个要求,我们得到:
![]()
为了计算无条件IS,p (y2 | x1)将会被无条件类概率p(y2) =∫∫ p(y|x1→2)p(x1→2|x1)p(x1) dx1 dx1→2替换:
![]()
为了获得高的CIS/IS分数,模型需要生成高质量和多样化的样本。IS是对所有输出图像多样性的度量,CIS是对单个输入图像的输出多样性的度量。在给定输入图像的情况下,确定地生成单个输出的模型将获得零CIS分数,尽管它在IS下仍然可能获得高分。我们使用特定数据集上微调的inception-v3 [79]作为分类器,并使用100个输入图像和每个输入的100个样本来估计Eq.(8)和Eq.(9)。
5.3 Baselines
UNIT[15]。该UNIT模型由两个具有完全共享潜在空间的VAE-GANs组成。转换的随机性来自于高斯编码器,也来自于VAEs中的dropout层。
CycleGAN [8]。CycleGAN由两个经过对抗损失和循环重构损失训练的残差转换网络组成。我们如Isola等人[6]所建议的一样,在训练和测试期间使用dropout来鼓励多样性。
带有噪音的CycleGAN*[8]。为了测试我们能否在CycleGAN框架内生成多模态输出,我们在两个转换网络中加入了噪声向量。由于我们发现在CycleGAN[8]中残差的结构忽略了噪声向量,所以我们使用了在输入中加入噪声的U-net结构[11]。在训练和测试中也会用到dropout。
BicycleGAN [11]。我们所知道的唯一能够生成连续和多模态输出分布的图像-图像转换模型。但是,它需要成对的训练数据。当数据集包含成对信息时,我们将我们的模型与BicycleGAN比较。
5.4 Datasets
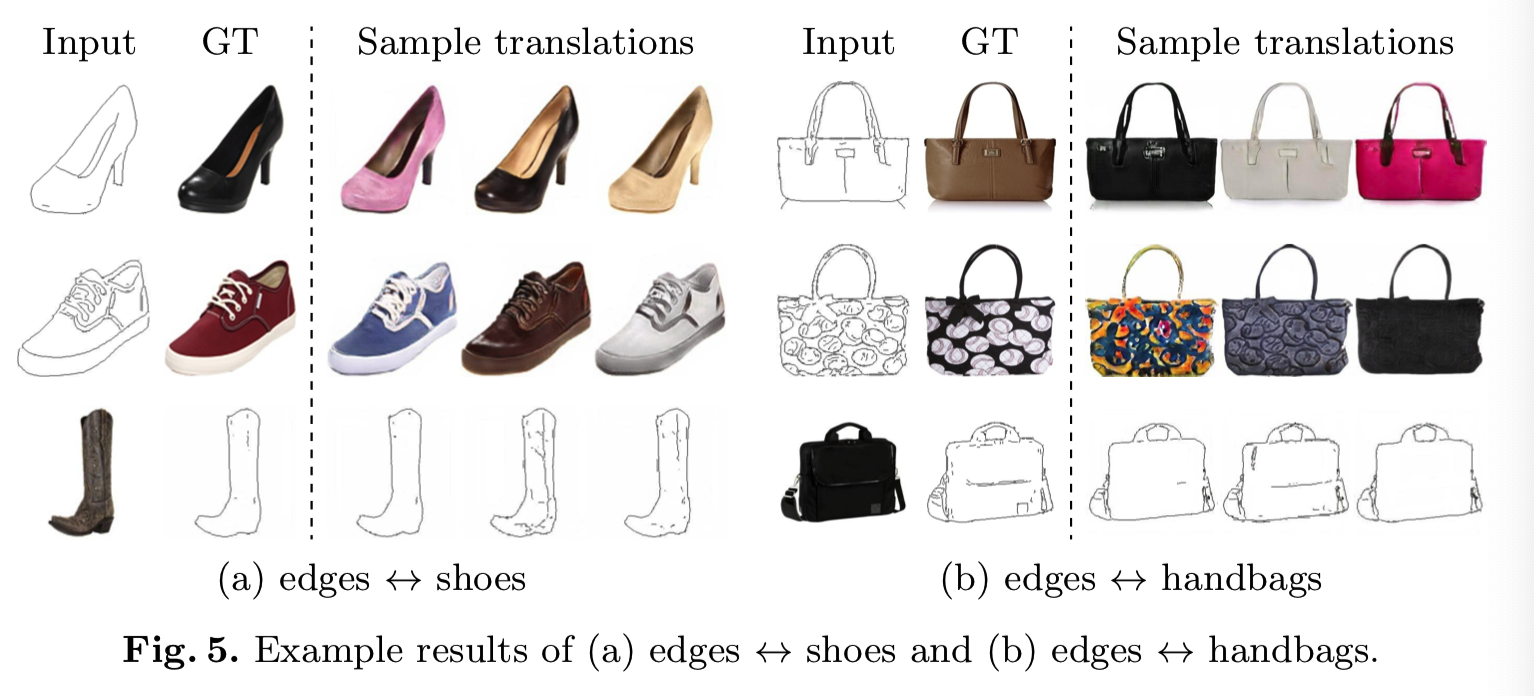
- 边缘↔鞋/手袋(Edges ↔ shoes/handbags)。我们使用的是Isola等人[6]、Yu等人[80]、Zhu等人[81]提供的数据集,这些数据集包含了HED生成的带有边缘图的鞋子和手袋图像[82]。我们不使用成对的信息训练一个边缘↔鞋模型,和另一个边缘↔手袋模型。
- 动物图像的转换。我们从3个类别/域收集图像,包括家猫、大猫和狗。每个域包含4个模式,它们是属于同一父类别的细粒度类别。注意,在学习转换模型时,图像的模式是未知的。我们为每一对域学习一个单独的模型。
- 街景图片。我们实验了两个街景转换任务:
- 合成↔真实(Synthetic ↔ real)。我们在SYNTHIA数据集中的合成图像和Cityscape数据集中的真实图像之间进行转换[83]。对于SYNTHIA数据集,我们使用了SYNTHIA-seqs子集,其中包含了不同季节、天气和光照条件下的图像。
- 夏季↔冬季( Summer ↔ winter)。我们使用Liu等人的[15]数据集,其中包含从真实驾驶视频中提取的夏季和冬季街道图像。
- 约塞米蒂夏季↔冬季(HD)(Yosemite summer ↔ winter (HD))。我们收集了一个新的高分辨率数据集,包含约塞米蒂的3253张夏季照片和2385张冬季照片。这些图像被向下采样,使得每张图像的最短边长为1024像素。
5.5 Results
首先,我们定性地比较了MUNIT与上述四个基线,以及三个分别去掉Lxrecon, Lcrecon, Lsrecon的MUNIT变体。图4为边缘→鞋的示例结果:

尽管注入了随机性,UNIT和CycleGAN(有或没有噪声)都不能产生不同的输出。如果没有Lxrecon或Lcrecon, MUNIT的图像质量就不能令人满意。如果没有Lsrecon,模型将遭受部分模式崩溃,许多输出几乎相同(例如,前两行)。我们完整的模型产生的图像既多样又真实,类似于BicycleGAN,但不需要监督。
上述定性观察通过定量评价得到了证实。我们用人类偏好来衡量质量,用LPIPS距离来评估
多样性,如第5.2节所述。我们在边缘→鞋子/手袋的任务上进行了这个实验。如表1所示:
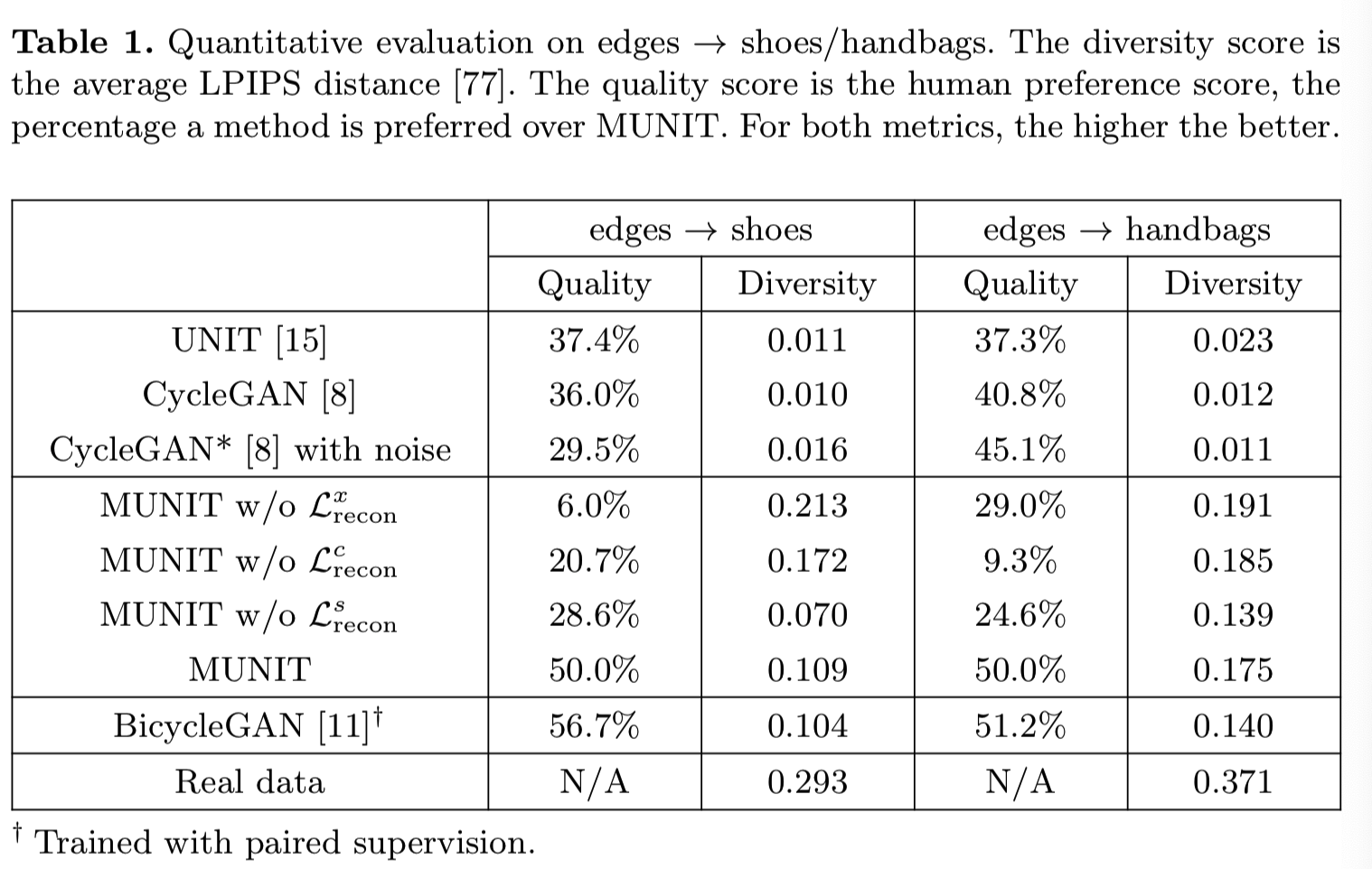
根据LPIPS距离可知,UNIT和CycleGAN产生的多样性很少。从MUNIT中移除Lxrecon或Lcrecon会导致质量显著下降。没有Lsrecon,质量和多样性都会恶化。完整的模型获得的质量和多样性可与完全监督的BicycleGAN相比,并明显优于所有非监督的基线。在图5中,我们将展示更多边缘↔鞋子/手袋的例子结果:
我们在动物图像转换数据集上进行了实验。如图6所示:

我们的模型成功地将一种动物转化为另一种动物。给定一个输入图像,其转换输出包括多种模式,即,目标域中的多个细粒度动物类别。动物的形状发生了巨大的变化,但姿势却完整地保留了下来。如表2所示:
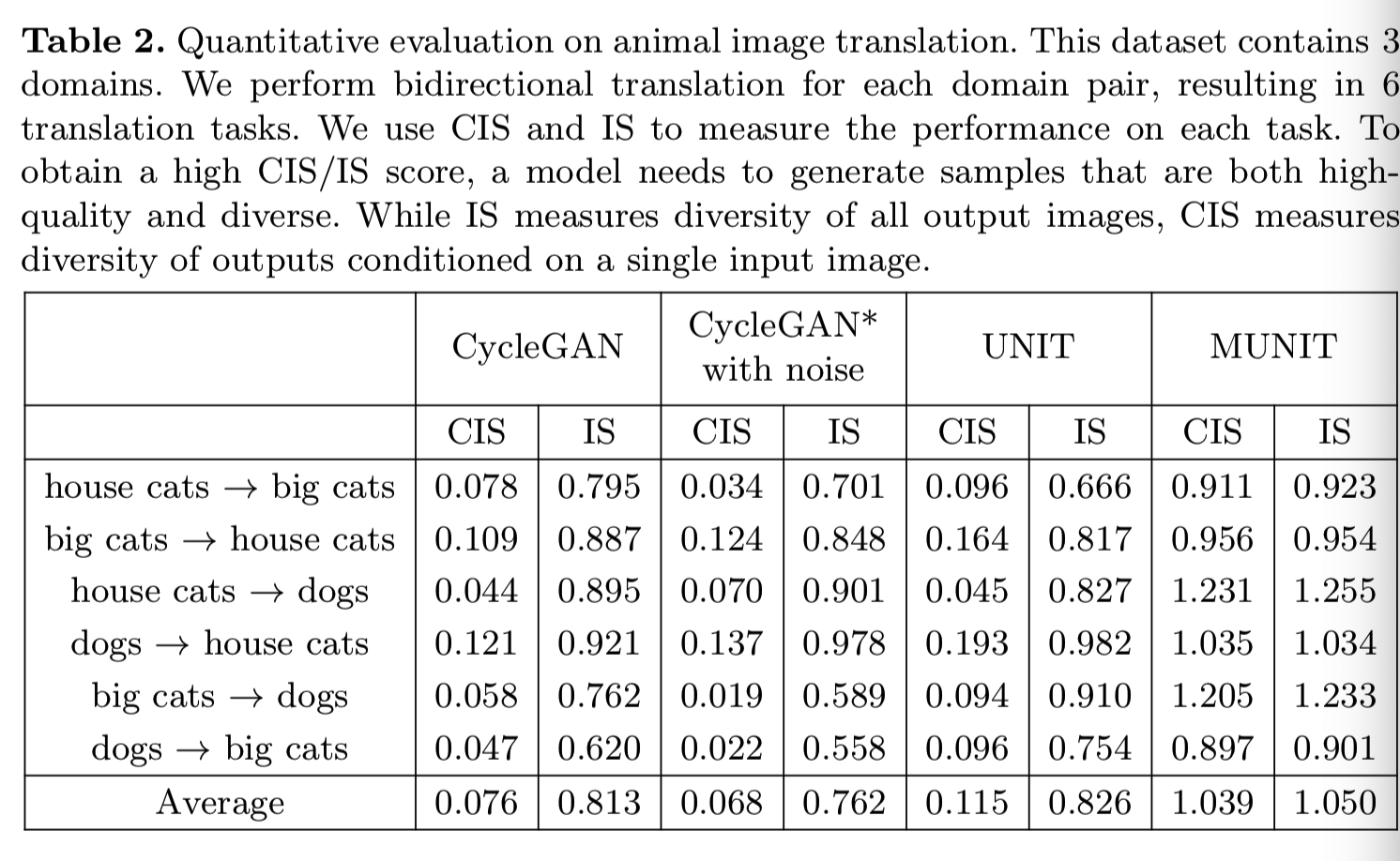
根据CIS和IS可见我们的模型得到了最高的分数。特别是,基线的CIS值都很低,这表明它们无法从给定的输入生成多模态输出。由于IS与图像质量[34]的相关性很高,我们的方法的IS值越高,说明它生成的图像质量也比基线方法高。
图7显示了街景数据集的结果。

我们的模型能够从一个给定的城市景观图像生成具有不同效果图(例如,雨、雪、日落)的SYNTHIA图像,并从一个给定的SYNTHIA图像生成具有不同灯光、阴影和道路纹理的城市景观图像。同样地,它从给定的夏季图像中得到不同数量的雪的冬季图像,以及从给定的冬季图像中得到不同数量的树叶的夏季图像。图8显示了示例结果夏季↔冬季转换的高分辨率约塞米蒂数据集:

我们的算法生成不同光照下的输出图像。
示例导向的图像转换。与从之前的图像中提取风格编码不同,也可以从参考图像中提取风格编码。
具体来说,给定一个内容图像x1∈X1,一个样式图像x2∈X2,我们的模型生成一个图像x1→2,通过x1→2 = G2(Ec1(x1),Es2(x2))对前者的内容和后者的风格进行重新组合。示例如图9所示:

注意,这类似于经典的风格转移算法[5,51 - 56],它将一个图像的样式转移到另一个图像。在图10中,我们将方法与Gatys等人的[5]、Chen等人的[85]、AdaIN[54]、WCT[55]等经典的转移算法进行了比较:

由于我们的方法使用了GANs来学习目标域图像的分布,因此我们的方法得到的结果更加真实可靠。
6 Conclusions
提出了一个多模态无监督图像到图像转换的框架。我们的模型在质量和多样性上都优于现有的无监督方法,并可与最先进的监督方法相媲美。未来的工作包括将这个框架扩展到其他领域,比如视频和文本。