Logging,Metrics 和 Tracing
Logging,Metrics 和 Tracing 有各自专注的部分。
-
Logging - 用于记录离散的事件。例如,应用程序的调试信息或错误信息。它是我们诊断问题的依据。
-
Metrics - 用于记录可聚合的数据。例如,队列的当前深度可被定义为一个度量值,在元素入队或出队时被更新;HTTP 请求个数可被定义为一个计数器,新请求到来时进行累加。
-
Tracing - 用于记录请求范围内的信息。例如,一次远程方法调用的执行过程和耗时。它是我们排查系统性能问题的利器。
这三者也有相互重叠的部分,如下图所示。
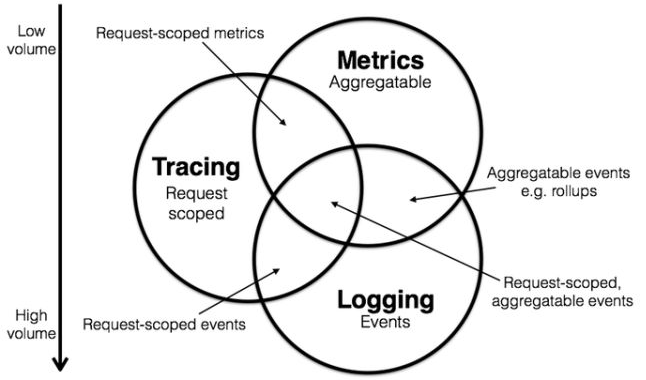
通过上述信息,我们可以对已有系统进行分类。例如,Zipkin 专注于 tracing 领域;Prometheus 开始专注于 metrics,随着时间推移可能会集成更多的 tracing 功能,但不太可能深入 logging 领域; ELK,阿里云日志服务这样的系统开始专注于 logging 领域,但同时也不断地集成其他领域的特性到系统中来,正向上图中的圆心靠近。
关于三者关系的更详细信息可参考 Metrics, tracing, and logging。下面我们重点介绍下 tracing。
Tracing 的诞生
Tracing 是在90年代就已出现的技术。但真正让该领域流行起来的还是源于 Google 的一篇论文"Dapper, a Large-Scale Distributed Systems Tracing Infrastructure",而另一篇论文"Uncertainty in Aggregate Estimates from Sampled Distributed Traces"中则包含关于采样的更详细分析。论文发表后一批优秀的 Tracing 软件孕育而生,比较流行的有:
-
Dapper(Google) : 各 tracer 的基础
-
StackDriver Trace (Google)
-
Zipkin(twitter)
-
Appdash(golang)
-
鹰眼(taobao)
-
谛听(盘古,阿里云云产品使用的Trace系统)
-
云图(蚂蚁Trace系统)
-
sTrace(神马)
-
X-ray(aws)
分布式追踪系统发展很快,种类繁多,但核心步骤一般有三个:代码埋点,数据存储、查询展示。