作者
Yang Cao,Wenfei Fan,Tengfei Yuan
University of Edinburgh,Beihang University SICS, Shenzhen University
{yang.cao@, wenfei@inf., tengfei.yuan@}ed.ac.uk
翻译:陈祥春
摘要
本文介绍了Zidian,它是键值(K,V)的中间件存储以通过NoSQL加速SQL查询评估。如反对采用元组id或primary的常规做法,Zidian提出以键为键,整个元组为值值即块模型BaaV。BaaV表示一个关系为键控块(k,B),其中k是B的块(集合)B的键部分元组。我们将关系代数扩展到BaaV。我们发现,BAAV下,Zidian大大降低数据访问和通讯成本。我们提供特征(充分和必要的条件)以(a)保持结果查询,即可用的BaaV商店覆盖的查询,(b)免扫描查询,即无需评估即可查询的查询扫描任何表,以及(c)有界查询,即查询可以通过访问有限数量的数据来回答。
我们证明,在并行处理中,Zidian保证(a)不扫描无扫描查询,(b)通讯受限有限查询的费用;(c)并行可伸缩性,即添加处理器时加快速度。而且,Zidian可以插入现有的SQL-No-SQL系统并保留水平可伸缩性。使用基准数据和真实数据,我们凭经验验证Zidian改进了现有的SQL-over-NoSQL系统平均减少2个数量级。
1.引言
键值(KV)商店已在行业中广泛使用。KV商店支持类似字典的数据ac-检索和将数据存储为键值对的必要性,从而提供了出色的可扩展性,容错能力和透明分片。为了支持大规模查询,已经使用了多个SQL引擎。在KV商店顶部开发。毕竟有75%的业务数据被生成并存储为关系[43],并且分析数据通常是通过SQL查询执行的。这些系统通常基于基于SQL的NoSQL体系结构。它将数据持久存储在KV存储集群中,并回答计算集群中的查询(作为单独的层)[29]。该架构已被Google的Spanner [20,12],Facebook的MyRocks [25],Hive [8]和SparkSQL [11],以及其他系统。虽然这些系统提供了潜在的KV优势,存储,它们的性能不如传统的DBMS在评估SQL查询时,由于以下原因。
(1)扫描成本高。通常,大多数SQL over NoSQL系统基于元组即值(TaaV)模型。它存储一个关系作为一组KV对(k,t),其中k是内部元组t的ID或主键。这些KV对组织在分布式哈希表(DHT)。DHT支持高效点通过给定键k的get进行访问,获取整个元组t。但是,对于大多数SQL查询,我们不知道提前相关元组。因此,我们必须“盲目”扫描通过获得与表大小一样多的获取数得到一个表。
(2)通讯负荷大。正如[37]所观察到的,很少SQL-No-NoSQL系统能够减少数据检索通过例如将选择谓词下推到存储层,并且没有人可以有效地执行扫描。结果是,通常需要大量数据(甚至是整个关系)从KV存储器中检索并由COM-处理放置层。这会导致数据通信成本高昂在并行执行中改组。情况更糟在非规范化数据库的常见做法中[32,36],即使用宽表或通用关系时。
我们可以减少过多的数据访问和通信吗成本,并使现有的SQL-No-NoSQL系统有效在回答SQL查询时是否像DBMS一样有效?Zidian 为了克服SQL-No-SQL的局限性,我们开发了Zidian(KV存储的中间件)。底层Zidian是一个按价值计价的模型(BaaV)。与之相反KV商店的传统TaaV模型,BaaV代表KV存储中的关系作为键控块(k,B),其中k是部分元组的块B的密钥。在BaaV下,任意属性可以作为键k,而k只能是TaaV下的id或主键属性。
根据BAAV模式,Zidian提供以下。[1]高效的SQL。Zidian加快No-SQL上的SQL系统。通过减少get调用,不相关数据的检索,以及因此,无论是计算成本还是通信成本。
(a)键控块提供DHT中关系的数据局部性。只需一次获取,就可以检索一组相关数据。
(b)BaaV为KV商店提供便捷的索引编制功能,正如[37]所观察到的那样,KV商店还没有很好地支持它。通过明确使用索引,我们可以使查询扫描-免费,无需扫描任何表格即可回答。免扫描查Q获取并仅对所需数据的一部分进行操作用于回答Q,因此也降低了计算成本。
(c)通过推理键块(k,B)和大小B。我们可以检查一个查询是否有界,只有无论有多大,都需要访问有限数量的数据底层数据集是,因此可以用有限的计算和通讯成本。
[2]可扩展性。在并行处理中,Zidian保证(a)并行可伸缩性,即添加时保证加速计算节点到计算层;(b)有界受限查询的通讯费用。此外,(c)Zidian保留了SQL-No-SQL系统的水平可伸缩性,即,在将新节点添加到存储层,其中吞吐量是指总数量每秒通过get [37]从所有存储节点检索的元组。
[3]易于使用。Zidian可以建立在任何SQL-over-任何KV商店都可以使用NoSQL系统,无需进行黑客攻击进入系统或更改其基础KV存储。那是的,Zidian可以“插入” No-SQL-No-SQL系统并帮助加快其SQL查询的答复速度。
贡献和组织。本文提出Zidian和证明BAAV,从基础到实践中。
(1) 数据模型(第4节)。我们介绍BaaV,将KV商店中的关系表示为关键块。我们扩展关系代数到BaaV商店,以利用BaaV模型回答SQL查询时。此外,我们定义了BaaV查询计划中的免扫描查询和有界查询,加快No- SQL上SQL系统的SQL评估。
(2) 一个框架(第5节)。基于BaaV,我们提出Zidian,一个加速现有 SQL 评估的框架SQL-No-NoSQL系统。它映射常规数据库D到BaaV存储D。它需要对D 进行SQL查询Q,然后尽可能在相应的BaaV商店D中向Q倾斜。我们研究框架的基本问题。特别是,我们提供了保存的特征,也就是说,有足够的必要条件来决定是否可以在可用D中回答对D提出的查询Q。
(3)我们描述了无扫描(限定边界)查询的特征,即,我们开发了充分必要的条件来确定SQL查询在BaaV存储上是否无扫描(限定边界)。 虽然问题是无法确定的,但特征描述提供了可以有效检查的此类查询的有效语法。 此外,我们提供了一种生成查询计划的算法,该算法可确保避免对无扫描(限制有界)的查询进行扫描(限制访问有限数量的数据)。
(4)并行化:有界和可扩展性(第7节)。我们建议在并行回答查询时交错数据访问和计算,而不是先获取所有数据然后计算答案。通过这种策略,我们表明zidian不需要扫描就可以进行无扫描查询,并且不需要为受限查询增加通信成本。而且,在BaaV下,zidian保证了并行可伸缩性,并保留了SQL-No-SQL系统的水平可伸缩性。
(5)实现(第8节)。作为概念证明,我们已经实现了Zidian并将其部署到SoH(SparkSQLover-HBase [7]),SoK(SparkSQL-over-Kudu [7])和SoC(SparkSQL-Cassandra [6])。除了第5节的框架外,Zidian还包括:(a)一个模块,用于在存储约束下帮助设计BaaV模式(第8.1节); (b)用于在现有KV系统上部署zidian的适配器。
(6)实验(第9节)。使用基准TPC-H [42]和实际数据,我们评估了Zidian的有效性。我们平均发现以下内容。 1)Zidian的无扫描查询效率分别比SoH,SoK和SoC高2.8×102、1.7×102和8.1×102,非无查询查询分别高2.0×102、1.5×102和3.6×102 。 2)使用Zidian,当数据集增长时,系统会为有界查询带来稳定的计算和通信成本。 3)Zidian具有平行可扩展性,并且可以很好地与数据集进行扩展,例如,在SoH之上的Zidian平均对8名员工的128GB数据集进行freefree和non-free-free查询分别需要27.7和65.4秒,而1.7×103和2.1× SoH没有紫电的103秒。 (4)zidian保留了基础KV系统的水平可扩展性,以应对KV工作量。
我们将在第2节中讨论相关工作,并复习SQL-over-第3节中的NoSQL。结果证明在[2]中。
2.相关工作
我们将相关工作分类如下。
SQL-No-SQL。NoSQL的SQL体系结构是广泛用于支持可扩展的并行SQL处理商用机器,例如[34,12,40,19,35,41,25],大写字母-利用KV系统作为存储,例如Apache的Cassandra[6],HBase [7]和Kudu [1]。扳手[20,12,40]开始这项工作,以支持大规模的分布式事务。它基于BigTable [18],它将关系存储为表TaaV下的KV对。这项工作之后是开源系统CockroachDB [19],Nuodb [35],MyRocks [25]和粒子[41](支持SPJ)。SparkSQL [11]和Hive[8]还为Spark和Hadoop提供类似SQL的查询界面,基于KV数据集的KV系统。所有这些系统都遵循BigTable [18]的列族设计,通过处理每个元组作为具有指定行键的值。
尽管这些SQL-NoSQL系统能够通过OLTP事务进行扩展,但其效率却受到KV商店扫描的影响,正如最近支持分析(OLAP)查询的尝试所观察到的[37、15、33]。为了克服这些限制,[37,15,33,1]通过设计提高扫描性能新的KV系统。他们专注于探索设计空间KV系统,以将扫描效率与其他系统参数(例如更新,版本控制和查询类型)进行权衡。其中,Tell [37](最近针对扫描进行了优化的现代KV系统)和Apache的Kudu [1]也在KV商店中探索基于列的存储关系。 这些努力对现有的KV存储和SQL-No-NoSQL组合没有帮助。
通过提出BaaV模型,这项工作采用了不同的方法。 它旨在提高现有SQL-No-SQL系统上的分析查询的性能,而又不影响其可伸缩性。 它探索了现有系统可以轻松支持的KV存储中关系的新逻辑表示模型,并研究了其对查询评估的影响,而无需更改KV存储。
二级索引。BaaV模型提供了KV商店二级索引的功能,但它不仅限于索引。很少有KV商店支持指数。在少数这样做的过程中,辅助索引被编码为通过填充键排序的关系[38],因此仍然受到TaaV模型的限制。更具体地说,KV存储中的关系R的非键属性A上的二级索引通常实现为KV对(k,v)的集合,其中键k是填充有内部id属性I(或 R)的主键,因此AI值在TaaV下是不同的,因此可以用作键;它们获取R的整个元组。这是低效的,因为(a)对A的点访问仍然会引起许多get调用,(b)不利于扫描,并且(c)引入了额外的索引维护成本。
相反,(a)BaaV通过使用DHT来支持索引KV系统,仅需获取一组值对于属性A上的同一点访问。此外,它减少了在元组中获取重复和不必要的属性,并且因此减少了数据访问和中间关系。的冗余随着连接迅速膨胀。(b)改善通过增加get的数据局部性和吞吐量进行扫描,同时保留水平和平行缩放的优势能力。(c)首先,作为数据模型,BaaV公开了索引为“方案”,并允许用户明确使用用于优化的索引。(d)更好的是,我们可以推断无扫描查询和有界查询,全部在查询级别。这些都大大改善了计算和通信尼克化。这些超出了传统中学的范围旨在仅加速数据检索的索引。
物化视图。物化视图在DBMS中用于定制数据库存储并加快查询评估速度[39]。从某种意义上说,世界客车联盟和Zidian提供的功能KV商店的“物化视图”。但是,有关键差异。(a)据我们所知,没有主要的SQL-over-NoSQL系统支持并在NoSQL存储。(b)一个人可能想扩展现有的KV系统像DBMS一样支持物化视图。但是,这样的扩展不能提供BaaV存储的优势,如果视图存储在TaaV模型下。确实,视图本质上是为给定查询量身定制的关系在DBMS中。因此,KV存储查看(如果支持)也受到基本关系在传统TaaV模式下的KV商店中遭受的相同限制。因此,BaaV是另一种更有效的支持KV商店中的物化视图(和基本关系)的方式。
有界评估。与这项工作有关的也是研究评估[26],以规范规模独立性在基数约束下[9,10,27,16]。那条线工作采用基数为基础的基于哈希的索引约束以确定是否只有有限数量的使用索引来回答关系查询需要数据仅在基数约束下通过查询重写来计划。
这项工作在以下方面与有限评估不同。
(a)有界评估的重点是在给定一组基数约束及其关联的基于哈希的索引的情况下,决定可以对哪些查询进行有界评估。相反,我们不需要基数约束。
(b)有限的评估仅在DBMS上有效,而BaaV和Zidian是为SQL-over-NoSQL中的KV存储开发的。
(c)有限评估未研究例如我们为Zidian开发的代数,并行化和数据映射。
3.前提
我们回顾了SQL-No-SQL系统的基本符号。
键值存储。KV存储是键-值(KV)对(k,v)的集合,分别称为键和值属性
它支持(a)get(k)来检索KV对(k,v)键为k,(b)put(k,v)添加KV对,以及(c)next()遍历所有键并获取下一个键。
KV商店中的关系。关系R的元组t为在TaaV(值即元组)下的KV商店中表示模型作为KV对(k,v),其中k是id或主要R在t中的键,且v为t。关系R存储为一组KV对共享相同的键和值属性,其中每对代表R的元组。通常封装并称为例如宽列家庭商店,因为它们提供了关系的概观。通过调用带有以下内容的get操作来执行对R的扫描通过next()提取的键,遍历R中的所有键。
SQL-over-NoSQL。在这样的系统中,如图1a所示,在TaaV模型下,关系模式R的数据库D作为KV存储存储在存储层中。 SQL-over-NoSQL系统向用户公开R,然后用户可以通过R发出Q查询。对Q的评估由计算群集在称为SQL层的单独层中进行。SQL层由SQL解析器,计划器和执行器组成,以生成Q的查询计划ξ。计划ξ仅通过get操作访问D的基础KV存储中的数据。。
SQL-over-NoSQL系统的工作方式如下。 在接收到SQL查询Q后,存储层将检索Q中涉及的所有关系,并将数据移至SQL层。 然后,SQL层为Q生成并行查询计划ξ,并在所有计算节点上并行执行该计划。
存储和计算的分离使SQL-over-NoSQL(a)由于繁重的计算任务而具有高可用性不会影响存储,并且(b)易于扩展,因为我们可以随需扩展。但是,它附带一个价格:数据访问通常会导致缓慢的完整关系扫描,并且因此,SQL层的通信负载很重。
4. BAAV模型
在本节中,我们首先介绍BaaV模型,KV存储中的重新关联关系作为键控块(第4.1节)。然后,我们提出关于BaaV商店的代数(第4.2节)。
4.1 BaaV: Block-as-a-Value
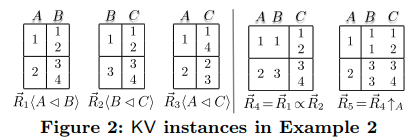
BaaV商店。KV模式的形式为R〈X,Y〉,其中X和Y是属性集。R〈X,Y〉上的键控块是KV对(k,B),其中k是属性X和B是属性Y上的一组元组。的KV实例DR〈X,Y〉是R上具有不同键的一组键控块。D的度数,以deg(D)表示为D中键控块(k,B)的最大大小,即deg(D)=max (k,B)∈D | B |,其中| B | 是B中的元组数。


请注意,在TaaV模型下,nationalkey,suppkey和name不能作为键属性,因为它们不是对应关系的主键。 相反,在BaaV下,由于BaaV值是元组块,因此将它们用作键。

属性。 BaaV具有以下优点。
(1)与TaaV相比,BaaV存储库允许将任意属性用作键。 实际上,当在键控块(k,B)中,B是单个元组时,TaaV是BaaV的特例。
(2)与在TaaV下相比,每个get调用在BaaV下可以检索更多的数据,因此在BaaV存储上效率更高。
(3)BaaV存储的程度表示KV存储的DHT的数据局部性程度。 通过调整BaaV商店的程度,我们可以获得有限的查询,并在BaaV下平衡KV商店的效率和更新成本。 关系数据库和KV商店之间的映射。两者之间有一个方便的对应。

表1汇总了符号。