硬件和软件信息
CPU: Intel(R) Xeon(R) CPU E5-2683 v3 @ 2.00GHz 2 sockets / 28 cores / 56 threads
内存: 256GB of RAM
存储: SAMSUNG SM863 1.9TB Enterprise SSD
操作系统: centos 7
文件系统: xfs
shared_buffers
定义了用于共享存储器缓冲区的存储器PostgreSQL使用量。这可以说是其最重要的设置,往往比(或好或坏)到MySQL的innodb_buffer_pool_size。最大的区别,如果我们敢于比较的shared_buffers缓冲池,是InnoDB的绕过操作系统的缓存直接访问(读取和写入)的底层存储子系统的数据,而PostgreSQL的没有。
这是否意味着PostgreSQL里面的“双缓冲”,首先装载数据从磁盘到操作系统的缓存来然后做这些网页的副本进入的shared_buffers区域?是。
这是否“双缓冲”让PostgreSQL的不如InnoDB和MySQL的内存管理方面?不,我们将讨论为什么这是一个跟进博客文章的情况。现在它足以说明实际性能取决于工作负载(读取和写入混合),“热数据”(即最常访问和修改数据集的部分),以及如何经常检查点的大小发生。
我们该如何选择了的shared_buffers以优化性能的PostgreSQL设置
由于这些因素,的shared_buffers设置的RAM或幻数“8GB”的25%的记录建议式是几乎不理想的。似乎是什么好理由,不过,是这样的:
如果你可以在内存中适应整个你的“热数据”,则专大部分的内存来的shared_buffers不负有心人很好,这使得PostgreSQL的表现为接近的内存数据库成为可能。
如果你的“热数据”的大小超过你的服务器有可用的内存量,那么你可能会更好用更小的shared_buffers区域合作,更多地依赖于操作系统的缓存。
对于这个基准,考虑到我们使用的选项,我们发现,专75%的所有可用内存来的shared_buffers是理想的。这足以适应整个“热数据”,仍然留下足够的内存用于OS操作,手柄连接和一切。
work_mem
该设置定义可以由每个查询(未会话),用于内部排序操作(如ORDER BY和DISTINCT)中使用的存储器量,以及哈希表(例如,执行基于散列的聚合时)。除此之外,PostgreSQL的数据移动到临时磁盘文件。我们面临的挑战通常在这里找到一个很好的平衡。我们要避免使用临时磁盘文件,它们会减慢查询完成,进而可能导致争。但我们不希望过度使用内存,甚至可能导致OOM;当是不是真的需要它与work_mem高价值的工作可能是破坏性的。
我们分析了sysbench的-TPCC产生的工作量,并与一些惊喜发现,work_mem不会在这里发挥作用,考虑已执行的查询。所以我们一直4MB的默认值。请注意,这是很少在生产工作负载的情况下,所以它总是盯紧该参数是非常重要的。
random_page_cost
此设置规定,非连续牵强磁盘页面将有成本,而且直接影响到查询规划决策。使用高等待时间的存储时,如旋转磁盘用保守的值会是特别重要的。这不是我们的情况,因此我们有能力平衡random_page_cost到seq_page_cost。所以,我们这个参数设置为1,那么从4默认值了。
wal_level, max_wal_senders and archive_mode
要设置流复制wal_level需要被设置为至少“replica”,archive_mode必须启用。这个装置的WAL数据产生量增加显著相比使用默认设置时这些参数,这反过来又影响到IO。然而,我们认为这些与生产环境的初衷。
wal_compression
对于此工作负载,我们观察到总的 WALs 大小为 3359 GB,禁用wal_compression,1962 GB wal_compression。我们启用wal_compression来减少 IO (以及最重要的是写入磁盘的 WAL 文件)的数量(以及最重要的速率),但牺牲了一些额外的 CPU 周期。这被证明是非常有效的,因为我们有多余的CPU可用。
checkpoint_timeout、checkpoint_completion_target和max_wal_size
我们将checkpoint_timeout设置为 1 小时,checkpoint_completion_target 设置为 0.9。这意味着每 1 小时强制一个检查点,并且在下一个检查点之前有 90% 的时间来传播写入。但是,当生成 wal max_wal_size时,也会强制使用检查点。通过"sysbench-tpcc"工作负载的这些参数,我们看到每 1 小时有 3 到 4 个检查点。这特别是因为生成的 LL 数量。
在生产环境中,我们始终建议您在关闭 PostgreSQL 之前执行手动 CHECKPOINT,以便更快地重新启动(恢复)时间。在此背景下,发布手动 CHECKPOINT 花了我们 1 到 2 分钟的时间,之后我们只需大约 4 秒即可重新启动 PostgreSQL。请注意,在我们的测试环境中,需要时间重新启动 PostgreSQL 不是问题,因此使用此检查点速率对我们有利。但是,如果您负担不起几分钟的崩溃恢复时间,则始终建议强制更频繁地执行检查点,即使代价是性能下降。
full_page_writes、fsync 和synchronous_commit
我们将所有这些参数设置为 ON 以满足 ACID 属性。
autovacuum
我们启用了正在后台进行 autovacuum 和其他 vacuum 设置,以确保真空。
我们将讨论保持在生产环境中启用 autovacuum,以及以其他方式这样做的危险性,在一个单独的职位的重要性。
10小时sysbench-TPCC的后生成WAL的(事务日志)的量
在我们开始讨论数字需要强调的是,我们开始之前sysbench的启用wal_compression是很重要的。
如我们上面提到的,用“wal_compression”设定为OFF产生的WAL的量为多种具有压缩启用时比产生WAL量的两倍。
我们观察到,使wal_compression导致增加21%TPS。难怪,生产WAL的对IO的重要影响:以至于它是非常常见的发现的PostgreSQL服务器与仅WAL专用存储。
因此,为了强调这一事实,wal_compression可以通过额外的CPU使用率的费用节约IO受益写密集型工作负载是很重要的。
为了找出WAL的10小时后产生的总金额,我们注意到在WAL从我们开始测试前和测试结束后偏移:
WAL Offset before starting the sysbench-tpcc ⇒ 2C/860000D0
WAL Offset after 10 hours of sysbench-tpcc ⇒ 217/14A49C50
和减去一个来自另一个使用pg_wal_lsn_diff,如下所示:
postgres=# SELECT pg_size_pretty(pg_wal_lsn_diff('217/14A49C50','2C/860000D0'));
pg_size_pretty
----------------
1962 GB
(1 row)
1962年GB WAL的10小时以上生产事务日志的一个相当大的量,考虑到我们已经启用wal_compression。
我们设想利用一个单独的磁盘来存储WAL多少更多的事务日志专用存储将有利于整体性能,找出。
但是,我们希望用Vadim 曾用他以前的测试相同的硬件保持,所以决定在此。
Crash unsafe parameters
设置 full_page_writes , FSYNC 和 synchronous_commit 为OFF可以加速性能,但它总是死机不安全,
除非我们有到位足够的备份来考虑这些需求。例如,如果您使用的是有一个日志文件系统COW,
你可能会被罚款与设置为OFF full_page_writes。这可能不是的,虽然时间真正100%。
然而,我们还是想分享在段落中提到以上作为参考崩溃不安全的参数结果。
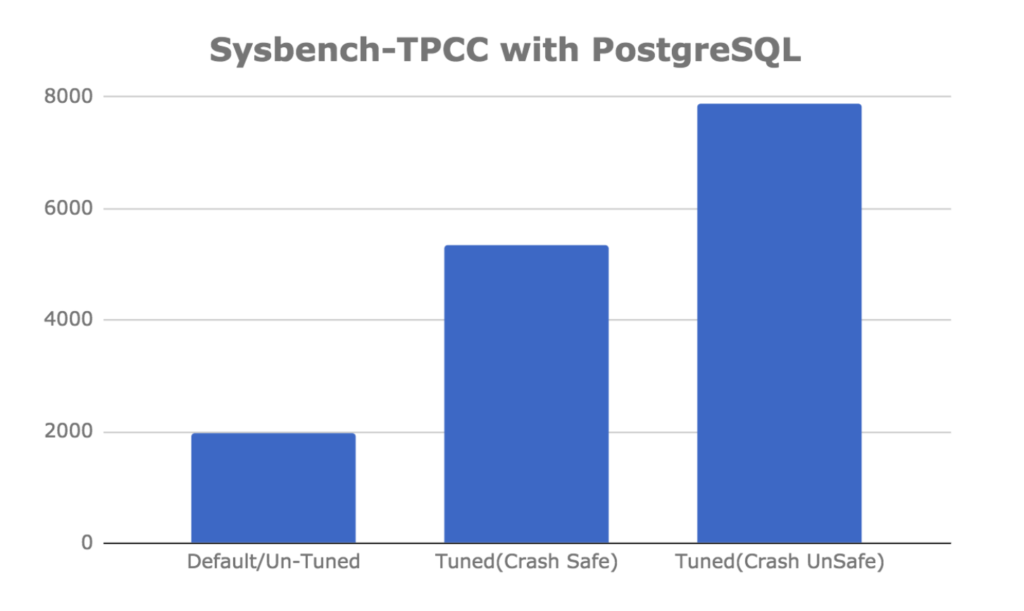
PostgreSQL的sysbench tpcc运行10小时后的结果,具有默认、崩溃安全和崩溃不安全参数
考虑到上述每种情况,我们在运行sysbench tpcc 10小时后获得的最终数字如下:
| 参数 | TPS |
| Default / Untuned | 1978.48 |
| Tuned (crash safe) | 5736.66 |
| Tuned (crash unsafe) | 7881.72 |
我们想得到这些数字吗?是和不是。
当然,我们希望一个经过适当调整的服务器能够比一个使用默认设置运行的服务器有更好的性能,但是我们不能说我们希望它比默认设置运行的服务器好三倍(2.899)。由于PostgreSQL使用了OS缓存,特别是对共享缓冲区的优化并不总是会产生如此显著的影响。相比之下,调整MySQL的InnoDB缓冲池几乎总是有区别的。对于PostgreSQL的高性能,它取决于工作负载。在这种情况下,对于sysbench tpcc基准测试,调整共享缓冲区肯定会有所不同。
另一方面,在使用崩溃不安全设置时,体验额外的速度级(4倍)并不令人惊讶。
以下是PostgreSQL插入性能调整基准测试结果的另一种视图: