目录
20182330《程序设计与设计结构》 第九周学习总结
教材学习内容总结
周一:查找
一、线性查找
- ASL平均查找长度:用平均比较次数估计算法优劣
ASL=累加:查到某个的概率查到所用的次数(次数之和1/n)查到1:n
查到n:1 查到i:n-i+1 - 查找失败:n+1
- 总数等于(i+n)n/2
- ASL=(1+n)/2 时间复杂度为O(n)
- 优化算法:放一个哨兵,不用比较,从后往前找
data[0]=target;
for(index = data.length-1;data[index].equals(target);
--index))
{ return index == 0 ? false:true;}| 哨兵 | 21 | 32 | 32 | 34 | 56 | 78 | 98 |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
- 也就是说,一定会找到。若返回的index=0,则找到的是哨兵,故未查找到。
二、二分查找(折半,必须有序)
从1开始
15/2=7
时间复杂度:O(log2 n)特点:
1.效率高
2.有序
3.只适用顺序存储
三、分块查找 :索引+顺序表(可以先折半再线性,ASL在折半线性之间)
- 分块有序
1-5 6-10分块
分别找最大值
20 (最大值)1(1-5)|40 6 |78 11
四、哈希表
- 不依赖于比较,用关键字查找
- %
- 冲突解决
1.开放定址法 除留余数法冲突就加: 线性探测再散列+1+2+3 。 H(k)=k%11.。。
二次探测再散列1^2 -1^2,2^2……(左右找)
伪随机探测再散列:生成伪随机数
2.链地址法
周五:排序
内部排序:插入 选择 交换 归并 基数
- 基本操作:比较、移动
衡量好坏:时间效率、空间效率、稳定性(两个相同数AB顺序保持不变)
插入排序
- 直接插入:大于等于前面的,所以是稳定的
- 最好情况:每个关键字比较一次,n-1次
最坏情况:完全是逆排序,(n+2)(n-1)/2---------就相当于n+1的前n项和-1
注意!多了一个哨兵,而且第一次不用比
折半,减少比较次数- 折半插入排序
2-路插入
选两个数一个放头一个放尾,大于49的从左开始,小于38的从右开始
希尔排序:分组交换排序,最后一组可能三个数排序
d增量每次都/2
交换排序
- 冒泡排序
- 快速排序
枢轴 - 选择排序
选择排序
- 简单选择
最好,正序排列 0次
最坏,(n-1)次
归并排序
多关键字排序
3.2堆排序
教材学习中的问题和解决过程
- 问题1:设置哨兵的算法应该如何实现?
- 问题1解决方案:在线性查找时我们用到了哨兵,,将a[0]设置成监视哨则可以避免每次比较元素后都需要判断下标。
/*带哨兵的直接顺序查找*/
int sequential_search(int a[],int n,int key) //n为数组元素个数,key为待查找元素
{
int i=n;
a[0]=key; //a[0]是监视哨
while(a[i]!=key) //若数组中无key,则一定会得到a[0]=key
i--;
return i; //查找失败返回0
}- 问题2:插入排序的最坏情况为什么是(n+2)(n-1)/2?
- 问题2解决方案:按常规思路应该是n(1+n)/2,为什么到了这里变成(n+2)(n-1)/2。反复推敲发现这种计算方法把哨兵也算为一个元素,按照这样即为算的时候只需要元素个数假装加一即可。

- 问题3:根节点到子节点的路径以及根节点到叶子节点的所有路径梳理
- 问题3解决方案:
- 当用前序遍历的方式访问到某一个节点的时候,我们把该节点添加到路径中。
- 如果该节点的值和我们要找的值相等,则打印路径,如果不相等,则继续访问它的子节点。
- 当前节点访问结束之后,递归函数将自动回到它的父节点。因此我们在函数退出之前要在路径上删除当前节点,以确保返回父节点时路径刚好是从根节点到父节点的路径。
- 如果我们需要保存每条路径,那就需要一个额外的vector< vector < int > >用于保存每一条路径
代码调试中的问题和解决过程
- 问题1:在网上看到代码@SuppressWarnings("unchecked")是什么意思
- 问题1解决方案:
作用:告诉编译器忽略指定的警告,不用在编译完成后出现警告信息。
使用:
@SuppressWarnings(“”)
@SuppressWarnings({})
@SuppressWarnings(value={})
示例:
@SuppressWarnings("unchecked")
告诉编译器忽略 unchecked 警告信息,如使用List,ArrayList等未进行参数化产生的警告信息。
@SuppressWarnings("serial")
如果编译器出现这样的警告信息:The serializable class WmailCalendar does notdeclare a static final serialVersionUID field of type long 使用这个注释将警告信息去掉。
代码托管
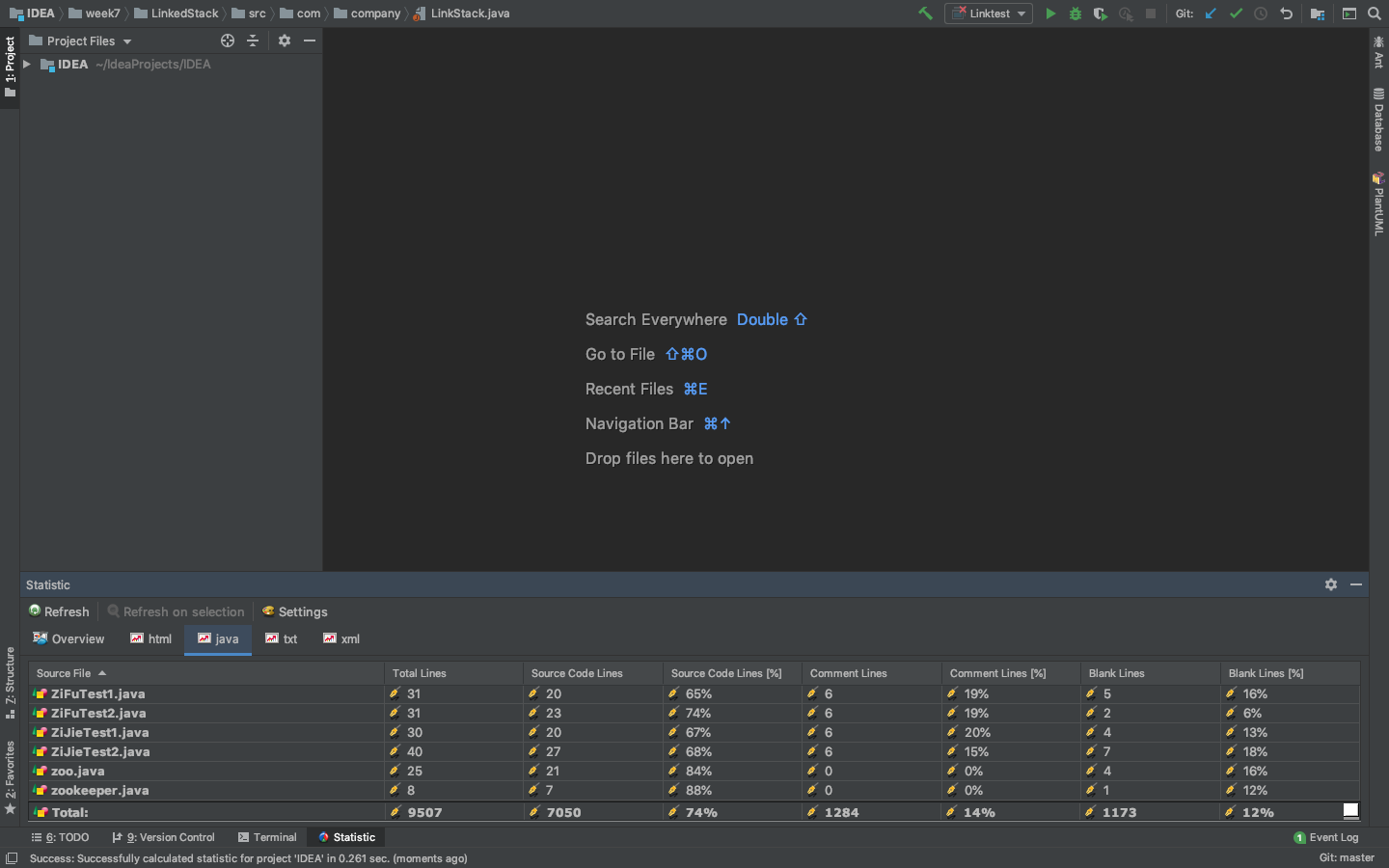
前几周忘了截图,这是截止第十周之前的代码,以后会记得按时截图,以下统计代码量按照总增量/3计算。
上周考试错题总结
- 错题1
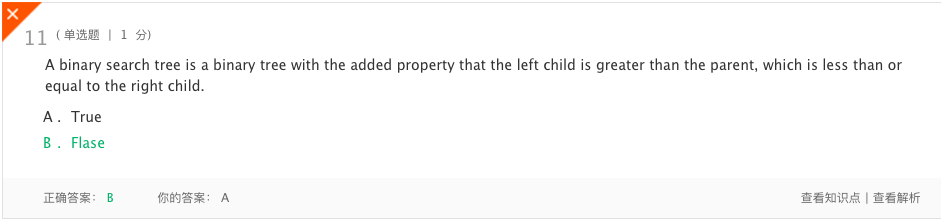
- 分析:二叉搜索树是一种具有附加属性的二叉树,即左边的子树小于右边的子树。看错了。
错题2
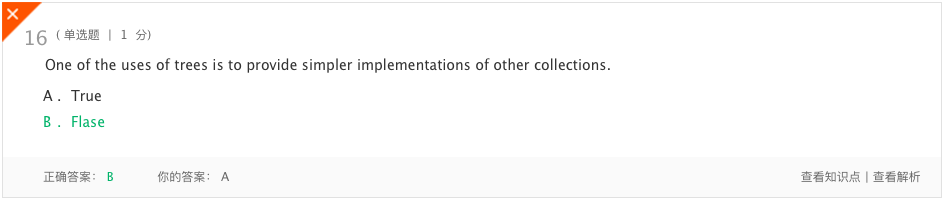
- 分析:树的一个用途是提供其他集合的更简单的实现。个人的理解是并不是更简单,而是精简算法
错题3
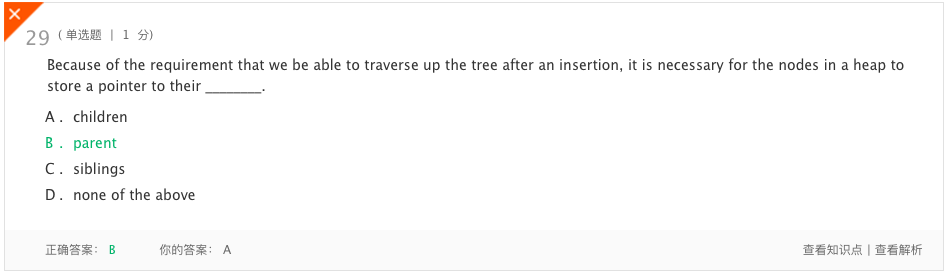
- 分析:因为我们需要在插入之后遍历树,所以堆中的节点必须存储指向它们的子树。
错题4

- 分析:同上题,一错错两道。
错题5
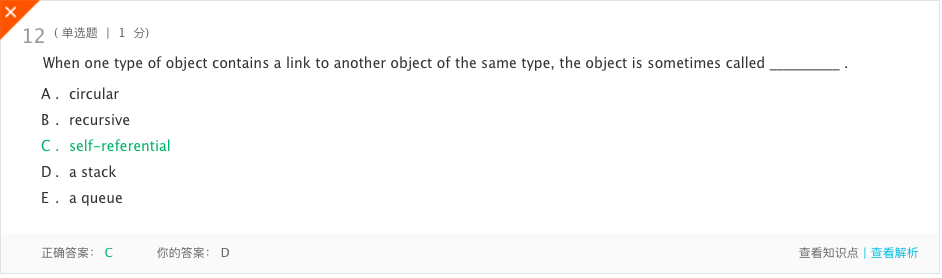
- 分析:当一种类型的对象包含到另一种类型的对象的链接时,有时会调用该对象。即自引用。
错题6
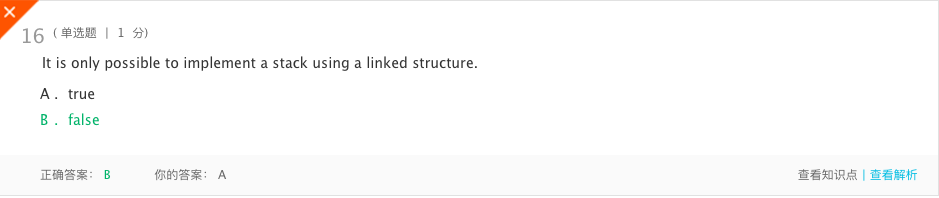
- 分析:堆栈可以使用链接结构或基于数组的结构来实现
错题7
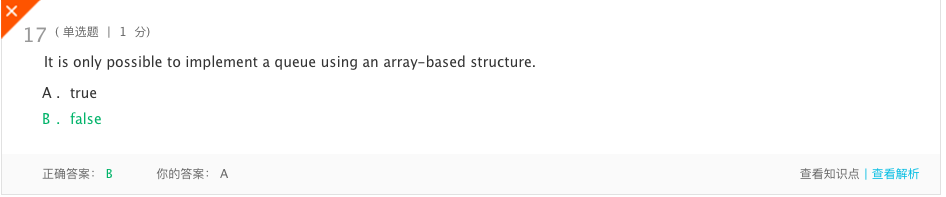
分析:可以使用链接结构或基于数组的结构来实现队列。
结对及互评
点评过的同学博客和代码
- 本周结对学习情况
- 20182314
- 点评:知识点总结的较为详细,错题总结深入。但是代码的问题理解不深。
基于评分标准,我给本博客打分:14分。得分情况如下:
感想,体会不假大空的加1分
排版精美的加一分
结对学习情况真实可信的加1分
正确使用Markdown语法
模板中的要素齐全(加1分)
错题学习深入的加1分
点评认真,能指出博客和代码中的问题的加1分
教材学习中的问题和解决过程, 加5分
代码调试中的问题和解决过程,加2分
- 上周博客互评情况
其他(感悟、思考等,可选)
第九周主要学习了查找和排序的相关知识,信息量很大,值得认真思考。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 42/42 | 2/2 | 20/20 | |
| 第三周 | 394/471 | 2/4 | 25/45 | |
| 第四周 | 394/471 | 2/4 | 25/45 | |
| 第五周 | 1668/2139 | 2/6 | 35/80 | |
| 第六周 | 2388/4527 | 1/7 | 30/110 | |
| 第七周 | 1660 /6187 | 2/9 | 25/135 | |
| 第八周 | 1660/7847 | 2/11 | 20/130 | |
| 第九周 | 1660/9507 | 2/13 | 25/155 |
计划学习时间:25小时
实际学习时间:25小时
改进情况:希望提高效率