本例中使用的elasticsearch版本为7.1.1 ,应用它的前提是你的elasticsearch已经成功启动并且可以正常访问。
1、elasticsearch-analysis-hanlp 中文分词插件下载:
下载地址:
https://github.com/KennFalcon/elasticsearch-analysis-hanlp/releases
在releases列表页面找到对应的ES版本,点击下载zip包


2、elasticsearch-analysis-pinyin 拼音分词插件下载:
下载地址:
https://github.com/medcl/elasticsearch-analysis-pinyin/releases
在releases列表页面找到对应的ES版本,点击下载zip包
3、下载hanlp中文分词的完整词典包 (测试安装时elasticsearch-analysis-hanlp带的默认的词典包也可以用这一步可以忽略)
下载地址:
https://github.com/hankcs/HanLP/releases

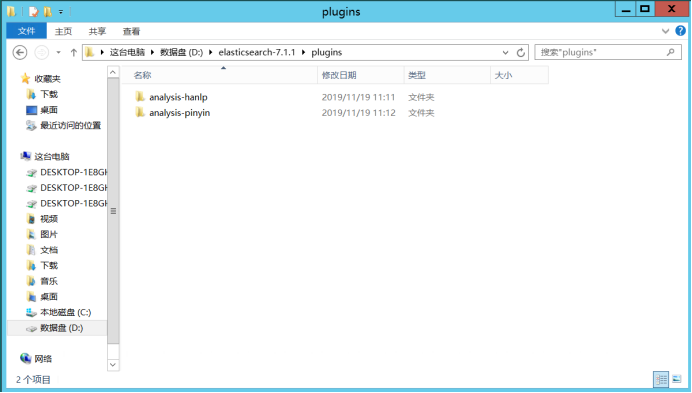
4、将elasticsearch-analysis-hanlp 与 elasticsearch-analysis-pinyin 解压并更名并放入ES安装目录下的plugins目录中,如:
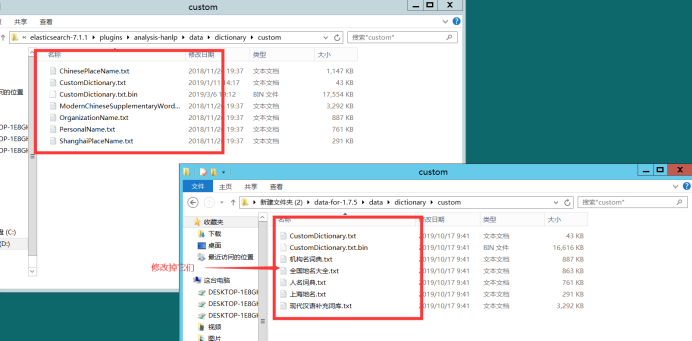
5、解压data-for-1.7.5词典文件,并且将data-for-1.7.5\data\dictionary\custom 目录下的中文名字修改成与 elasticsearch-7.1.1\plugins\analysis-hanlp\data\dictionary\custom 文件夹下的名字一至,且将如data-for-1.7.5\data目录覆盖掉elasticsearch-7.1.1\plugins\analysis-hanlp\data目录:(不用完整词典包的忽略这一步)
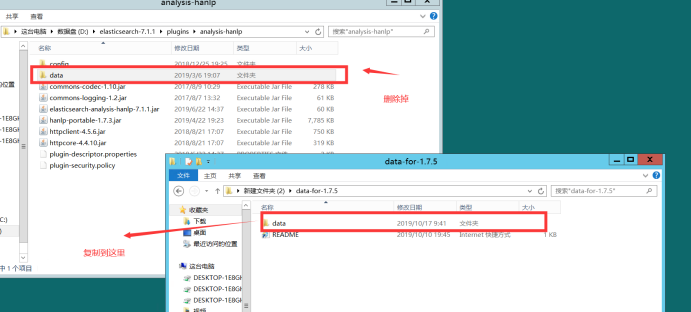
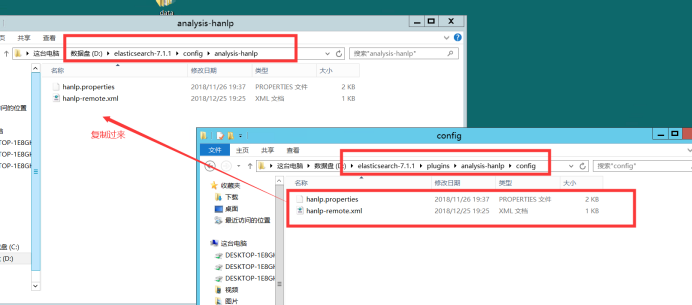
6、在D:\elasticsearch-7.1.1\config\目录下新建analysis-hanlp文件夹并将D:\elasticsearch-7.1.1\plugins\analysis-hanlp\config 目录下的文件复制到D:\elasticsearch-7.1.1\config\analysis-hanlp目录下,如:
7、启动ES服务正常来说不会出现问题(我这就不正常出现一些莫名其妙的问题,这都不重要),好了 我就当你的服务也成功启动了。
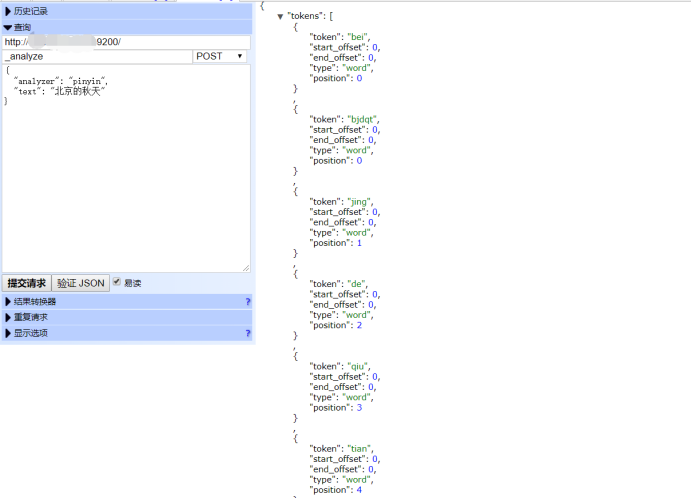
8、使用hand插件测试一下拼音插件,好的看起来是成功了。
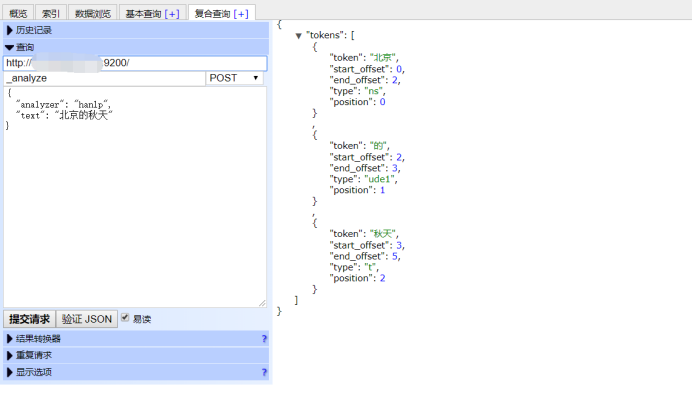
9、再测试一下中文分词插件,成功~✿✿ヽ(°▽°)ノ✿
10、新建一个索引document2给其字段设置中文分词和拼音分词。成功~
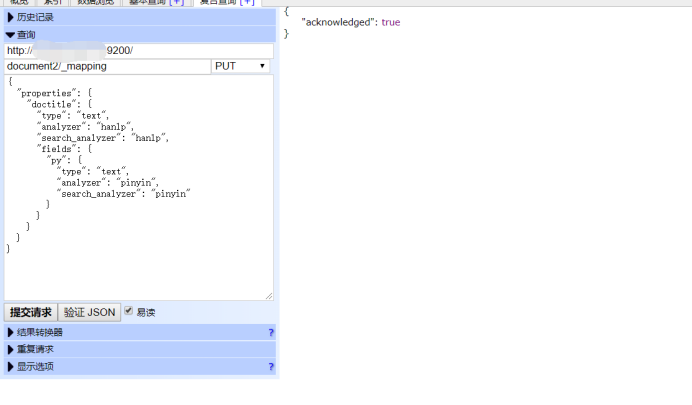
1 document2/_mapping/ 2 3 { 4 5 "properties":{ 6 7 "doctitle":{ 8 9 "type":"text", 10 11 "analyzer":"hanlp", 12 13 "search_analyzer":"hanlp", 14 15 "fields":{ 16 17 "py":{ 18 19 "type":"text", 20 21 "analyzer":"pinyin", 22 23 "search_analyzer":"pinyin" 24 25 } 26 27 } 28 29 } 30 31 } 32 33 }
11、加入测试数据(由于我已经有现成的数据了所以直接复制一个索引的数据到document2)
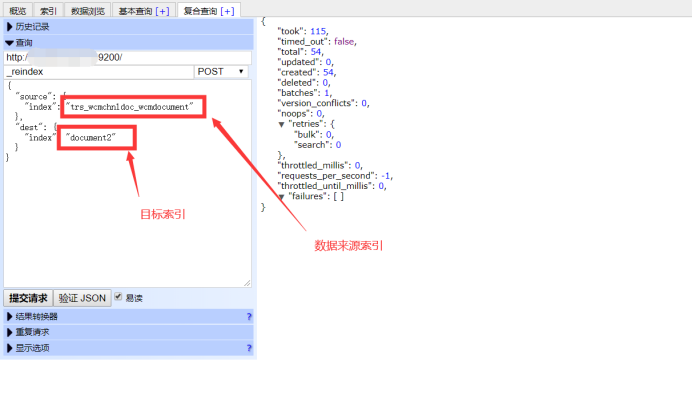
12、测试查询结果(这里请求一定要发post 千万不要用get别问我怎么知道)

至此中文分词拼音分词安装配置完成,JavaAPI的应用在下一篇