计算机网络-网络层-路由算法
最优化原则
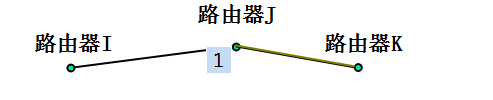
1.最佳路径的每一部分也是最佳路径
如果路由器J在从路由器I到K的最优路径上,那么从J到K的最优路径必定沿着同样的路由路径
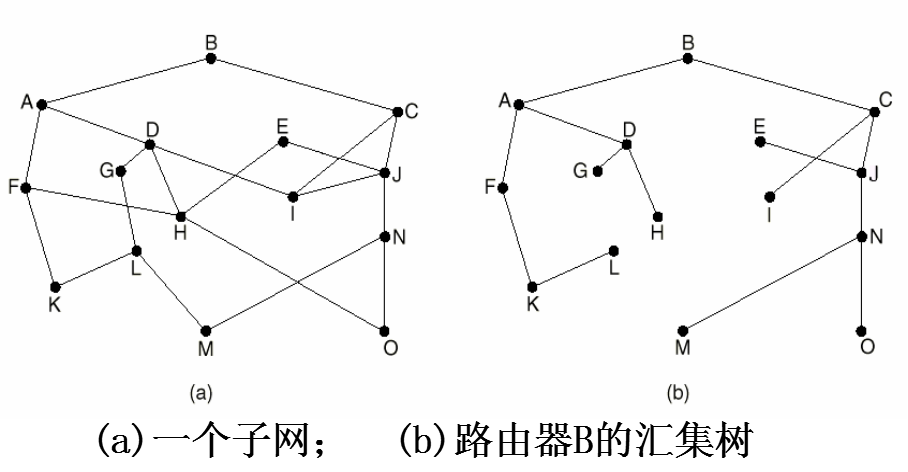
2.通往路由器的所有最佳路径的并集是一棵称为汇集树
3.路由算法的目的
为所有路由器找出并使用汇集树
最短路径路由
Dijkstra算法
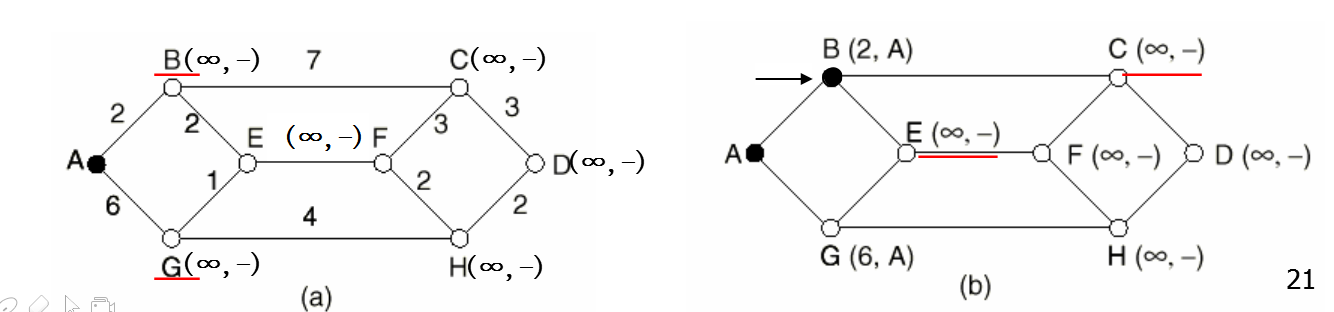
1.每个节点用从源节点沿已知最佳路径到该节点的距离来标注,标注分为临时性标注和永久性标注
2.初始时,所有节点都为临时性标注,标注为无穷大
3.将源节点标注为0,且为永久性标注,并令其为工作节点
4.检查与工作节点相邻的临时性节点,若该节点到工作节点的距离与工作节点的标注之和小于该节点的标注,则用新计算得到的和重新标注该节点
5.在整个图中查找具有最小值的临时性标注节点,将其变为永久性节点,并成为下一轮检查的工作节点
6.重复第四、五步,直到目的节点成为工作节点
泛洪算法
描述
一种将数据包发送到所有网络节点的简单方法,每个节点通过将其发送到所有其他链接之外来泛洪在传入链接上接收到的新数据包,它属于静态算法
问题
- 重复的数据包,由于循环可能会无限多
- 节点需要跟踪已泛洪的数据包以阻止洪泛
- 即使在跳数上使用限制也会成倍爆炸
两种解决措施
每个数据包的头中包含一个跳计数器,每经过一跳后该计数器减1,为0时则丢弃该数据包
记录哪些数据包已经被扩散了,从而避免再次发送这些数据包。方法:
1.每个数据包头一个序号,每次发送新数据包时加1
2.每个路由器记录下它所看到的所有(源路由器,序号)对
3.当一个数据包到达时,路由器检查这个数据包,若是重复的,就不再扩散了
选择性扩散
它是一种泛洪方法的一种改进,将进来的每个数据包仅发送到与正确方向接近的线路上
扩散法应用情况
- 扩散法的高度健壮性,可用于军事应用
- 分布式数据库应用中,可用于同时更新所有的数据库
- 可用于无线网络中
- 扩散法作为衡量标准,用来比较其它的路由算法
距离矢量算法
描述
距离向量是一种分布式路由算法,最短路径计算跨节点分配,属于动态算法,被用于RIP协议。
算法思想
1.每个节点都知道到其邻居的链接的距离
2.每个节点向所有邻居通告已知距离最小的向量
3.每个节点使用接收到的向量来更新自己的向量
4.定期重复
原理
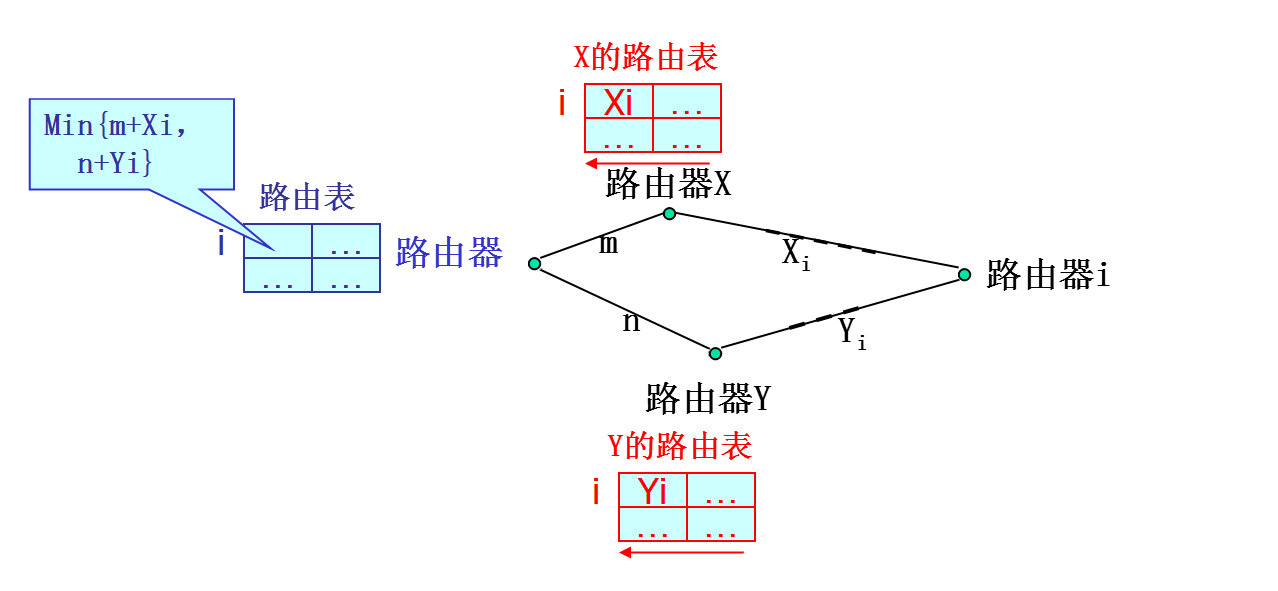
1.每个路由器维护一张路由表(见下图)

2.路由表以子网中每个路由器为索引(如右图的To),且每个路由器对应一个表项
3.表项包括两部分:到达该目的路由器的时间估计或距离估计(如上图的New estimated delay form J),和到达目的路由器的首选使用的输出线路(如右图的Line)
4.每隔一段时间,路由器向所有邻居路由器发送它到每个目的节点的路由表,同时它也接收每个邻居路由器发来的路由表
5.一个路由器接收到来自相邻路由器X发来的表,其中Xi为路由器X到路由器i的距离,若该路由器到X的距离为m,则该路由器经过X到i的距离为Xi+m。根据不同邻居发来的信息,计算Xi+m,并取最小值,更新本路由器的路由表
问题
无穷计算问题
算法的缺陷:对好消息反应迅速,对坏消息反应迟钝
问题的核心:当X告诉Y它有一条路径的时候,Y无从知道他自己是否在这条路径上

链路状态路由算法
为了解决距离矢量算法的什么问题?
1.距离向量路由算法的主要问题
2.选择路由时,没有考虑线路带宽(不同线路的带宽不同)
3.路由收敛速度慢(无穷计算问题)
描述
距离向量的替代,计算更多,但具有简单动态性
算法概述
每个节点都在LSP(链路状态数据包)中泛洪有关其邻居的信息。
所有节点都学习完整的网络图
每个节点都运行Dijkstra的算法来计算到达其他目的地的路径
过程描述
1.发现邻居节点,并知道其网络地址
- 路由器启动后,通过发送HELLO数据包发现邻居节点
2.测量到每个邻居节点的延迟或开销 - 一种直接的方法是:发送一个的ECHO数据包,另一端立即送回一个应答,往返时间除以2即为延迟
- 有时需要考虑负载
3.创建链路状态数据包 - 数据包构成发送方的标识符、序号、年龄、邻居列表。表项包括路由器的邻居,和到这个邻居的延迟
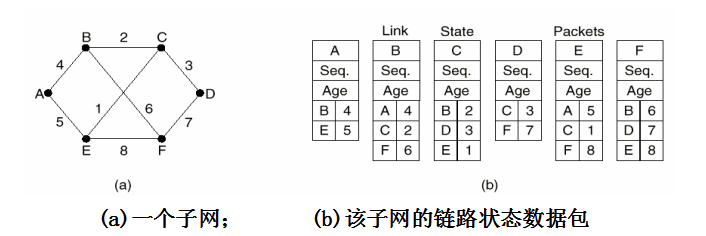
- 何时创建链路状态数据包?定期创建或发生重大事件时创建
4.将这个数据包发送给所有其它路由器
基本思想:
- 使用扩散法发布链路状态数据包
- 为控制扩散,每个数据包头一个序号,每次发送新数据包时加1
- 每个路由器记录下它所看到的所有(源路由器,序号)对
- 当一个链路状态数据包到达时,路由器检查这个数据包
- 若是新的,路由器在已看到的数据包列表中检查收到的数据包,若不存在,则新的,则除了它到来的那条线路外,在其他线路上全部转发该数据包
- 若是重复的,则丢弃
- 若是过时的,若序号比当前所看到的来自该路由器的最大序号小,则认为过时,则丢弃
改进:
- 序号回转可能产生混淆。解决办法:使用32位序号。即使每秒产生一个数据包,需137年才能回转
- 路由器崩溃后,如果它再从0开始,则下一个数据包被作为重复数据包而丢弃。解决办法:数据包中增加年龄(age)域,每秒钟年龄减1,为零时,来自该路由器的信息被丢弃
- 序号被破坏。解决办法:数据包中增加年龄域
- 链路状态数据包到达后,延迟一段时间,并与其它已到达的来自同一路由器的链路状态数据包比较序号,丢弃重复包,保留新数据包
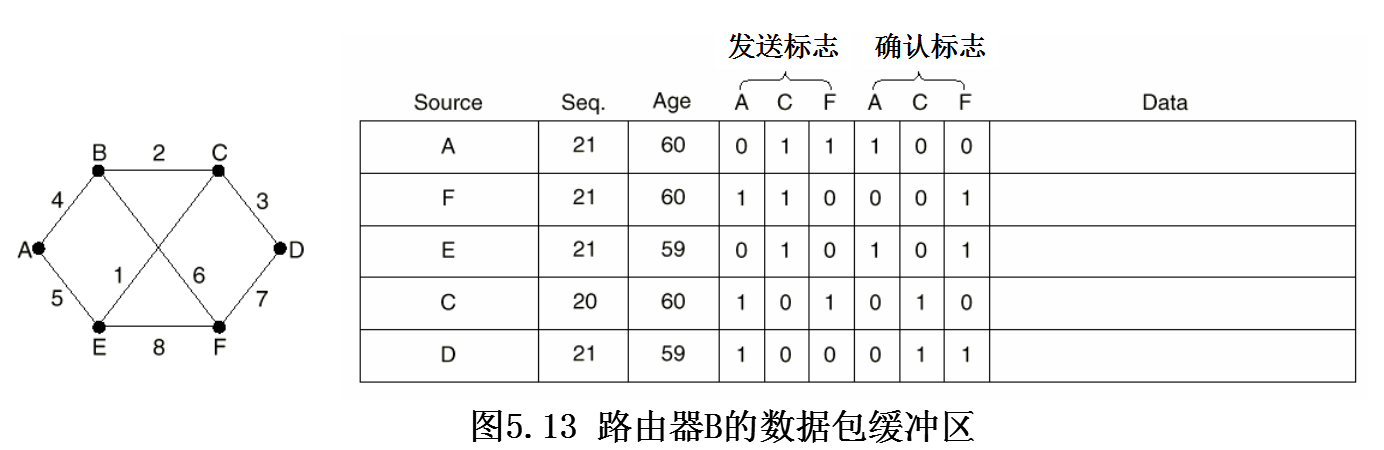
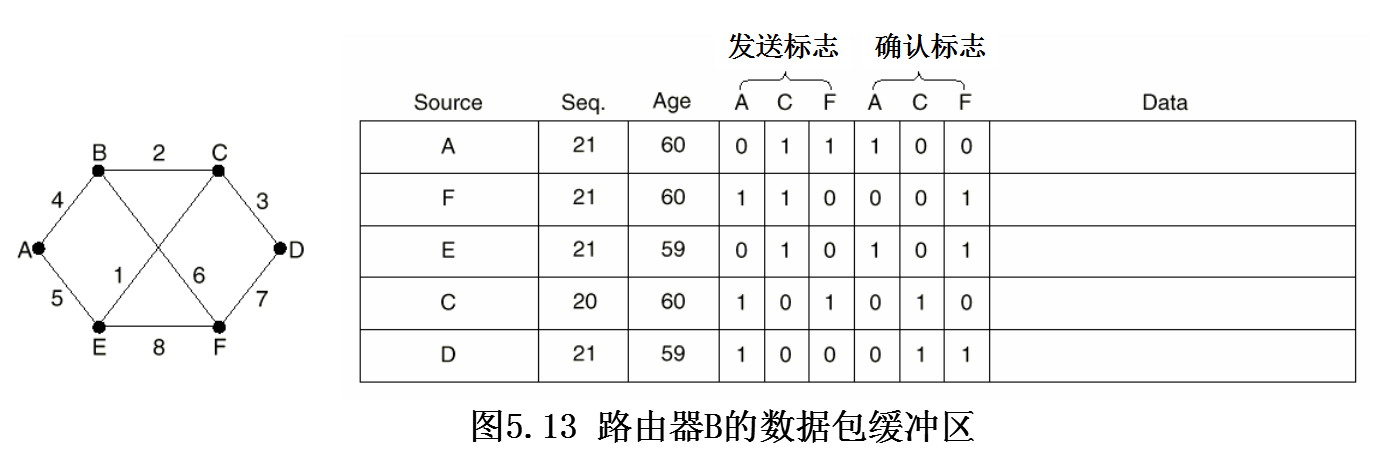
- 所有的链路状态数据包需要应答
发送标志为1:需要向此方向转发,
确认标志为1:必须在此方向上被确认
来自A的链路状态数据包可以直接到达,B必须将它发给C、F,向A送回确认
从E发来的链路状态包有两个,一个经过EAB,另一个经过EFB
从D发来的链路状态包有两个,一个经过DCB,另一个经过DFB
使用协议
广泛用于Internet(OSPF,ISIS)
层次路由
为什么要采用层次路由?
随着网络规模的增加,路由器的路由表增长过快,占用路由器内存,而且还要费时间去扫描表,非常的麻烦。
层次路由怎么做的?
路由器被划分成区域,每个路由器知道如何把数据包发送到自己所在的目标地址,但是对其他区域的内部结构显得不知情,当网络彼此连接到一起的时候,很自然就会将每一个网络不必知道其他网络的拓扑结构。
实例
它分成了5个区域,如果采用完整的路由1A路由器有17个表项目,如果采用分级的路由,那么表项在右边,减少了好多。
代价
代价是增加了路由长度
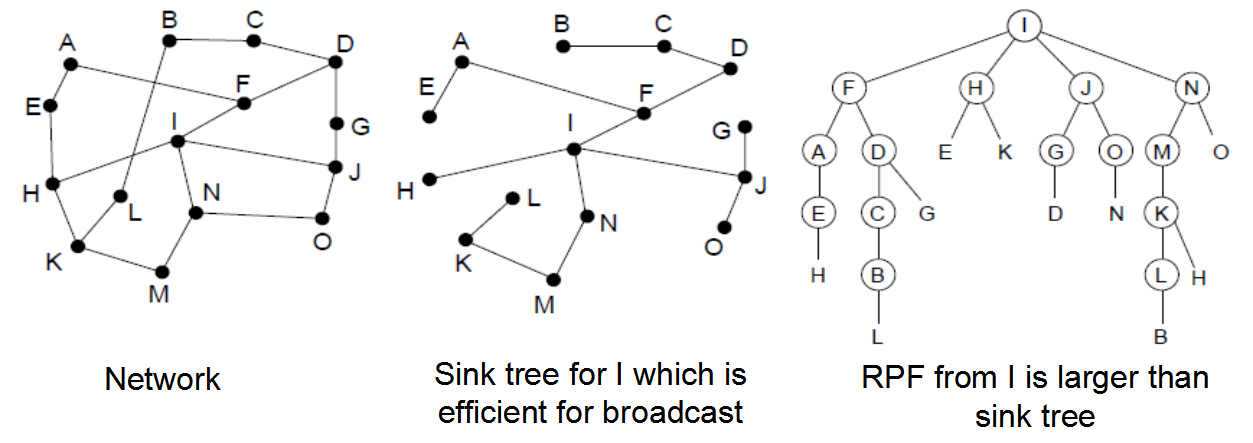
广播路由
- 广播将数据包发送到所有节点
- RPF(反向路径转发),将在链接上收到的广播发送到所有其余链接,或者,可以在所有节点上构建和使用接收器树
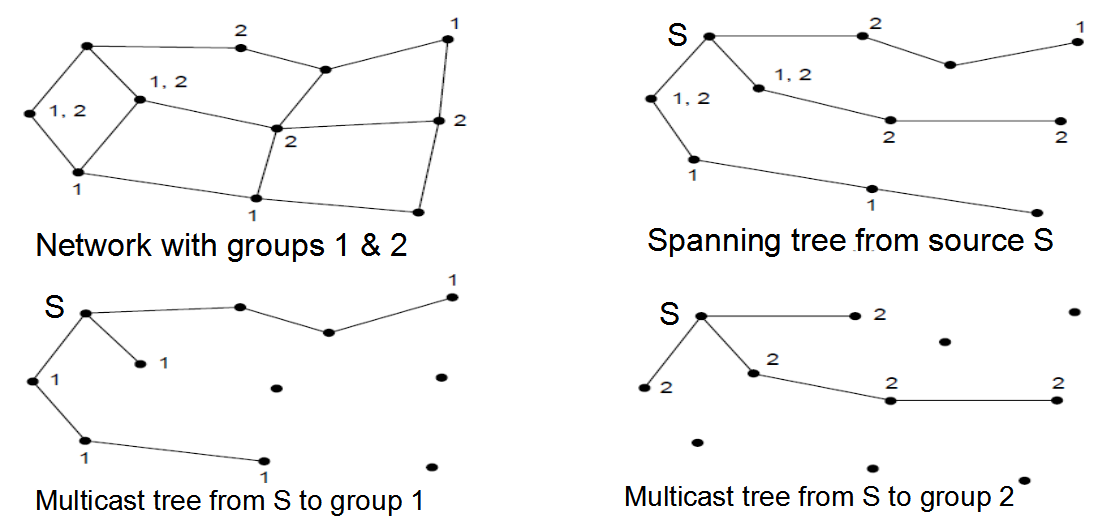
组播路由
- 组播发送到称为组的节点的子集
- 为每个组和源使用不同的树