一、JAVA编译相关概念
1、动态编译(dynamic compilation)指的是“在运行时进行编译”;与之相对的是事前编译(ahead-of-time compilation,简称AOT),也叫静态编译(static compilation)。
2、JIT编译(just-in-time compilation)狭义来说是当某段代码即将第一次被执行时进行编译,因而叫“即时编译”。JIT编译是动态编译的一种特例。JIT编译一词后来被泛化,时常与动态编译等价;但要注意广义与狭义的JIT编译所指的区别。
3、自适应动态编译(adaptive dynamic compilation)也是一种动态编译,但它通常执行的时机比JIT编译迟,先让程序“以某种式”先运行起来,收集一些信息之后再做动态编译。这样的编译可以更加优化。
二、JVM中的编译器
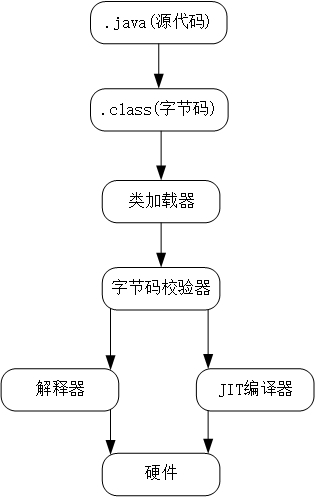
在部分商用虚拟机中(如HotSpot),Java程序最初是通过解释器(Interpreter)进行解释执行的,当虚拟机发现某个方法或代码块的运行特别频繁时,就会把这些代码认定为“热点代码”。为了提高热点代码的执行效率,在运行时,虚拟机将会把这些代码编译成与本地平台相关的机器码,并进行各种层次的优化,完成这个任务的编译器称为即时编译器(Just In Time Compiler,下文统称JIT编译器)。
即时编译器并不是虚拟机必须的部分,Java虚拟机规范并没有规定Java虚拟机内必须要有即时编译器存在,更没有限定或指导即时编译器应该如何去实现。但是,即时编译器编译性能的好坏、代码优化程度的高低却是衡量一款商用虚拟机优秀与否的最关键的指标之一,它也是虚拟机中最核心且最能体现虚拟机技术水平的部分。
由于Java虚拟机规范并没有具体的约束规则去限制即使编译器应该如何实现,所以这部分功能完全是与虚拟机具体实现相关的内容,如无特殊说明,我们提到的编译器、即时编译器都是指Hotspot虚拟机内的即时编译器,虚拟机也是特指HotSpot虚拟机。
三、为何HotSpot虚拟器要解释器和编译器并存?
尽管并不是所有的Java虚拟机都采用解释器与编译器并存的架构,但许多主流的商用虚拟机(如HotSpot),都同时包含解释器和编译器。解释器与编译器两者各有优势:当程序需要迅速启动和执行的时候,解释器可以首先发挥作用,省去编译的时间,立即执行。在程序运行后,随着时间的推移,编译器逐渐发挥作用,把越来越多的代码编译成本地代码之后,可以获取更高的执行效率。当程序运行环境中内存资源限制较大(如部分嵌入式系统中),可以使用解释器执行节约内存,反之可以使用编译执行来提升效率。此外,如果编译后出现“罕见陷阱”,可以通过逆优化退回到解释执行。
解释器的执行,抽象的看是这样的:输入的代码 -> [ 解释器 解释执行 ] -> 执行结果
而要JIT编译然后再执行的话,抽象的看则是:输入的代码 -> [ 编译器 编译 ] -> 编译后的代码 -> [ 执行 ] -> 执行结果
说JIT比解释快,其实说的是“执行编译后的代码”比“解释器解释执行”要快,并不是说“编译”这个动作比“解释”这个动作快。JIT编译再怎么快,至少也比解释执行一次略慢一些,而要得到最后的执行结果还得再经过一个“执行编译后的代码”的过程。所以,对“只执行一次”的代码而言,解释执行其实总是比JIT编译执行要快。怎么算是“只执行一次的代码”呢?粗略说,下面两个条件同时满足时就是严格的“只执行一次”
1、只被调用一次,例如类的构造器(class initializer,<clinit>())
2、没有循环
对只执行一次的代码做JIT编译再执行,可以说是得不偿失。对只执行少量次数的代码,JIT编译带来的执行速度的提升也未必能抵消掉最初编译带来的开销。只有对频繁执行的代码,JIT编译才能保证有正面的收益。
对一般的Java方法而言,编译后代码的大小相对于字节码的大小,膨胀比达到10x是很正常的。同上面说的时间开销一样,这里的空间开销也是,只有对执行频繁的代码才值得编译,如果把所有代码都编译则会显著增加代码所占空间,导致“代码爆炸”。这也就解释了为什么有些JVM会选择不总是做JIT编译,而是选择用解释器+JIT编译器的混合执行引擎。
四、HotSpot虚拟机如何选择热点代码并编译为本地代码?
程序中的代码只有是热点代码时,才会编译为本地代码,那么什么是热点代码呢?运行过程中会被即时编译器编译的“热点代码”有两类:
1、被多次调用的方法。
2、被多次执行的循环体。
两种情况,编译器都是以整个方法作为编译对象。 这种编译方法因为编译发生在方法执行过程之中,因此形象的称之为栈上替换(On Stack Replacement,OSR),即方法栈帧还在栈上,方法就被替换了。
要知道方法或一段代码是不是热点代码,是不是需要触发即时编译,需要进行Hot Spot Detection(热点探测)。目前主要的热点探测方式有以下两种:
1、基于采样的热点探测
采用这种方法的虚拟机会周期性地检查各个线程的栈顶,如果发现某些方法经常出现在栈顶,那这个方法就是“热点方法”。这种探测方法的好处是实现简单高效,还可以很容易地获取方法调用关系(将调用堆栈展开即可),缺点是很难精确地确认一个方法的热度,容易因为受到线程阻塞或别的外界因素的影响而扰乱热点探测。
2、基于计数器的热点探测
采用这种方法的虚拟机会为每个方法(甚至是代码块)建立计数器,统计方法的执行次数,如果执行次数超过一定的阀值,就认为它是“热点方法”。这种统计方法实现复杂一些,需要为每个方法建立并维护计数器,而且不能直接获取到方法的调用关系,但是它的统计结果相对更加精确严谨。
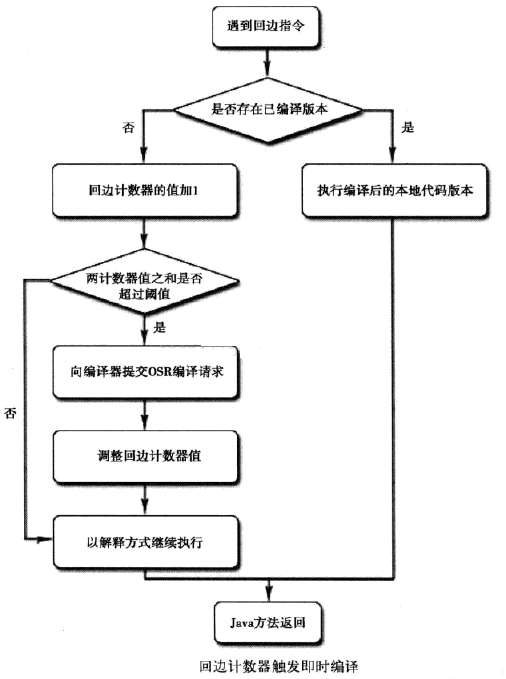
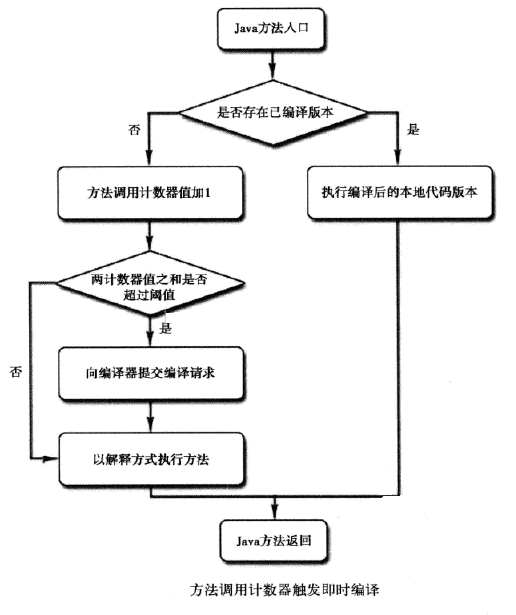
在HotSpot虚拟机中使用的是第二种——基于计数器的热点探测方法,因此它为每个方法准备了两个计数器:方法调用计数器和回边计数器。在确定虚拟机运行参数的前提下,这两个计数器都有一个确定的阈值,当计数器超过阈值溢出了,就会触发JIT编译。
方法计数器
顾名思义,这个计数器用于统计方法被调用的次数。当一个方法被调用时,会先检查该方法是否存在被JIT编译过的版本,如果存在,则优先使用编译后的本地代码来执行。如果不存在已被编译过的版本,则将此方法的调用计数器值加1,然后判断方法调用计数器与回边计数器值之和是否超过方法调用计数器的阈值。如果超过阈值,那么将会向即时编译器提交一个该方法的代码编译请求。
如果不做任何设置,执行引擎并不会同步等待编译请求完成,而是继续进行解释器按照解释方式执行字节码,直到提交的请求被编译器编译完成。当编译工作完成之后,这个方法的调用入口地址就会系统自动改写成新的,下一次调用该方法时就会使用已编译的版本。
回边计数器
它的作用就是统计一个方法中循环体代码执行的次数,在字节码中遇到控制流向后跳转的指令称为“回边”。