进程的切换和一般执行过程
知识总结
操作系统原理中介绍了大量进程调度算法,这些算法从实现的角度看仅仅是从运行队列中选择一个新进程,选择的过程中运用了不同的策略而已。
对于理解操作系统的工作机制,反而是进程的调度时机与进程的切换机制更为关键。
1.不同类型的进程有不同需求的调度需求:
第一种分类:
—I/O-bound:频繁的进行I/O,通常会花费很多时间等待I/O操作的完成
—CPU-bound:计算密集型,需要大量的CPU时间进行运算
第二种分类:
—批处理进程:不必与用户交互,通常在后台运行;不必响应很快;
—实时进程:有实时需求,不被低优先级的进程阻塞;响应时间短,稳定;
—交互式进程:需要经常与用户交互;响应时间要快
2.进程调度的时机
中断处理过程(包括时钟中断、I/O中断、系统调用和异常)中,直接调用schedule(),或者返回用户态时根据need_resched标记调用schedule();
用户态进程只能被动调度。
内核线程可以直接调用schedule()进行进程切换,也可以在中断处理过程中进行调度,也就是说内核线程作为一类的特殊的进程可以主动调度,也可以被动调度;
内核线程是只有内核态没有用户态的特殊进程。内核线程可以主动调度,也可以被动调度。
用户态进程无法实现主动调度,仅能通过陷入内核态后的某个时机点进行调度,即在中断处理过程中进行调度。
schedule()函数选择一个新的进程来运行,并调用context_switch进行上下文的切换,这个宏调用switch_to来进行关键上下文切换
next = pick_next_task(rq, prev);//进程调度算法都封装这个函数内部
context_switch(rq, prev, next);//进程上下文切换
switch_to利用了prev和next两个参数:prev指向当前进程,next指向被调度的进程
3.linux进程调度与进程切换
实验流程
如之前一样,克隆menu,然后重新编译内核,并启动gdb调试
内核启动
gdb调试
在schedule(),context_switch(),pick_next_task()打入断点
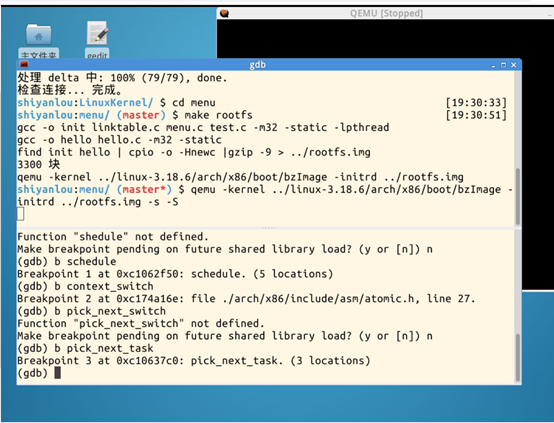
按c执行,停在schedule函数处

按c继续执行到pick_next_task断点处

按c继续执行到context_switch断点处,用来实现进程的切换。

代码分析
linux调度的核心函数为schedule,schedule函数封装了内核调度的框架。细节实现上调用具体的调度类中的函数实现。schedule函数主要流程为:将当前进程从相应的运行队列中删除,计算和更新调度实体和进程的相关调度信息;将当前进重新插入到调度运行队列中,根据具体的运行时间进行插入而对于实时调度插入到对应优先级队列的队尾,从运行队列中选择运行的下一个进程,进程调度信息和上下文切换。当进程上下文切换后,调度就基本上完成了,当前运行的进程就是切换过来的进程了。
static void __sched __schedule(void)
{
struct task_struct prev, next;
unsigned long switch_count;
struct rq rq;
int cpu;
need_resched:
preempt_disable();
cpu = smp_processor_id();
rq = cpu_rq(cpu);
rcu_note_context_switch(cpu);
prev = rq->curr;
schedule_debug(prev);
if (sched_feat(HRTICK))
hrtick_clear(rq);
smp_mb__before_spinlock();
raw_spin_lock_irq(&rq->lock);
switch_count = &prev->nivcsw;
if (prev->state && !(preempt_count() & PREEMPT_ACTIVE)) {
if (unlikely(signal_pending_state(prev->state, prev))) {
prev->state = TASK_RUNNING;
} else {
deactivate_task(rq, prev, DEQUEUE_SLEEP);
prev->on_rq = 0;
if (prev->flags & PF_WQ_WORKER) {
struct task_struct *to_wakeup;
to_wakeup = wq_worker_sleeping(prev, cpu);
if (to_wakeup)
try_to_wake_up_local(to_wakeup);
}
}
switch_count = &prev->nvcsw;
}
if (task_on_rq_queued(prev) || rq->skip_clock_update < 0)
update_rq_clock(rq);
next = pick_next_task(rq, prev);
clear_tsk_need_resched(prev);
clear_preempt_need_resched();
rq->skip_clock_update = 0;
if (likely(prev != next)) {
rq->nr_switches++;
rq->curr = next;
++*switch_count;
context_switch(rq, prev, next); /* unlocks the rq */
cpu = smp_processor_id();
rq = cpu_rq(cpu);
} else
raw_spin_unlock_irq(&rq->lock);
post_schedule(rq);
sched_preempt_enable_no_resched();
if (need_resched())
goto need_resched;
}当切换进程已经选好后,就开始用户虚拟空间的处理,然后就是进程的切换switch_to()。所谓进程的切换主要就是堆栈的切换,这是由宏操作switch_to()完成的。这里的输出部分有三个参数,表示这段程序执行后有三项数据会有改变。
asm volatile("pushfl\n\t"
"pushl %%ebp\n\t"
"movl %%esp,%[prev_sp]\n\t"
"movl %[next_sp],%%esp\n\t"
"movl $1f,%[prev_ip]\n\t"
"pushl %[next_ip]\n\t"
__switch_canary
"jmp __switch_to\n"
"1:\t"
"popl %%ebp\n\t"
"popfl\n"
/* output parameters */
: [prev_sp] "=m" (prev->thread.sp),
[prev_ip] "=m" (prev->thread.ip),
"=a" (last),
/* clobbered output registers: */
"=b" (ebx), "=c" (ecx), "=d" (edx),
"=S" (esi), "=D" (edi)
__switch_canary_oparam
/* input parameters: */
: [next_sp] "m" (next->thread.sp),
[next_ip] "m" (next->thread.ip),
/* regparm parameters for __switch_to(): */
[prev] "a" (prev),
[next] "d" (next)
__switch_canary_iparam
: /* reloaded segment registers */
"memory"); 总结
一次一般的进程切换过程,其中必须完成的关键操作是:切换地址空间、切换内核堆栈、切换内核控制流程,加上一些必要的寄存器保存和恢复。这里,除去地址空间的切换,其他操作要强调“内核”一词。这是因为,这些操作并非针对用户代码,切换完成后,也没有立即跑到next的用户空间中执行。用户上下文的保存和恢复是通过中断和异常机制,在内核态和用户态相互切换时才发生的。schedule()是内核和其他部分用于调用进程调度器的入口,选择哪个进程可以运行,何时将其投入运行。就如switch_to中的方法,通过压栈出栈交换prev_ip和next_ip。然后返回,从而完成进程调度。而用哪个作为下来的进程,则通过优先级的算法和进程调度算法来决定。