ES版本升级工作
当前版本:v5.4.1 目标版本:v7.3.2
注意事项:
备份数据
修改配置
优先升级主节点数最少的节点
必须等集群状态恢复green后再升级下一个节点
官方提供的三种升级方案:
方案一:Rolling Upgrade 滚动升级,每次升级一个节点,服务不会宕 Rolling upgrade to 5.6 Rolling upgrade to 6.8 Rolling upgrade to 7.3.2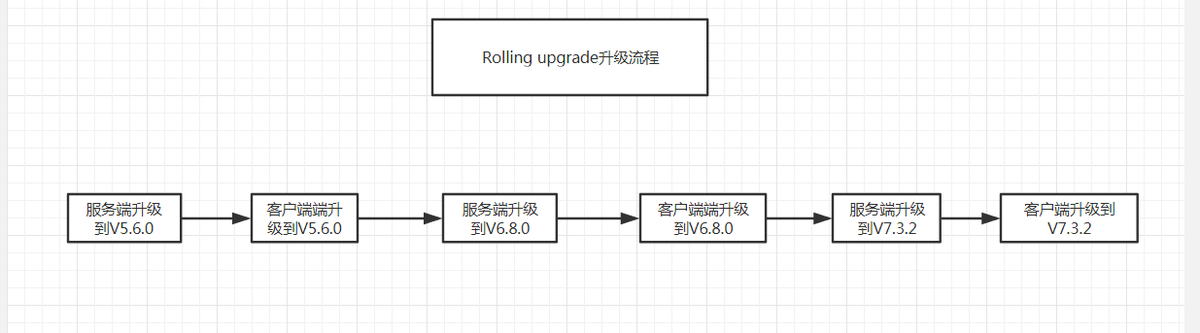
方案二:Full cluster restart upgrade If you are running a version prior to 6.0, upgrade to 6.8 and reindex your old indices or bring up a new 7.3.2 cluster and reindex from remote. 由于版本低于6.0:需要搭建好V7.3.2的集群(建好索引),再reindex from remote Reindex from remote You must set up the destination index before calling _reindex. Reindex does not copy the settings from the source index. Mappings, shard counts, replicas, and so on must be configured ahead of time.方案三:Reindex befor upgrading Create a new 7.3.2 cluster and Reindex from remote由于当前使用的版本相对新版本较低,方案二和方案三的动作是一样的,都是先搭建好一个V7.3.2的集群,重建好所有索引,再执行Reindex from remote(远程拉取数据)
方案一测试:
测试集群:10.0.6.121,10.0.6.101,10.0.6.140
测试数据:通过es-analysor项目写一份学习统计数据到测试集群(数据为持续写入状态)
采用方案一进行升级,自定义插件没有使用,中间版本不进行升级官方文档
使用测试集群,暂不备份数据(快照备份数据)官方文档
一个快照表示的是这个索引在快照被创建时间点的索引视图,所以在索引过程开始之后被添加到索引中的记录不会出现在快照中。
快照是增量的,可以包含在多个ES版本中创建的索引。如果在一个快照中的任何索引时在不兼容的ES版本中创建的,你将不能恢复该快照。
恢复操作可以在正常运行的集群上执行。已存在的索引只能在关闭状态下才能恢复,并且要跟快照中索引拥有相同数目的分片。还原操作自动打开关闭状态的索引,如果被还原索引在集群不存在,将创建新索引
备份数据神坑:
1.需要赋予用户权限;
2.各个节点es用户UID和GID需要一致,否则创建仓库的时候会连接失败
elasticsearch:x:501:501::/home/elasticsearch:/bin/bash
准备好V5.6、V6.8、V7.3.2安装包,下载地址
更改配置,与V5.4.1一致,已知需要配置elasticsearch.yml,jvm.options(测试集群出现OOM)
备份:
PUT _snapshot/my_backup
{
"type": "fs",
"settings": {
"location": "/mnt/mfs/es-bak"
}
}
POST _snapshot/my_backup/
{
"type": "fs",
"settings": {
"location": "/mnt/mfs/es-bak",
"max_snapshot_bytes_per_sec" : "50mb",
"max_restore_bytes_per_sec" : "50mb"
}
}1.升级到V5.6.0
分配elasticsearch用户权限:chown -R elasticsearch /opt/servers/elasticsearch-5.6.0 1.Disable shard allocation 因为节点重启很快就会返回集群,避免大量I/O
PUT _cluster/settings
{
"transient": {
"cluster.routing.allocation.enable": "none"
}
}
2.Stop non-essential indexing and perform a synced flush (Optional). A synced flush request is a “best effort” operation
POST _flush/synced检查是否用了supervisor
安装了superviso:
修改配置,用http://es-host:7777来启动节点
未安装supervisor:
kill -9 pid 杀掉低版本es进程
集群状态变为yellow
启动当前节点V5.6.0服务 Reenable shard allocation
PUT _cluster/settings
{
"transient": {
"cluster.routing.allocation.enable": "all"
}
}新加入的高版本节点开始分配shard,集群状态恢复为green
repeat 直到所有节点迭代完毕
集群状态恢复green
至此测试集群完成从V5.4.1到V5.6.0升级
优势:平滑迭代,服务不会宕机,应用无感,没有重建索引的过程
弊端:每个节点迭代后需要等集群恢复到green,正式集群数据量大,这个恢复过程会更长,由于版本关系Rollnig upgrade 到V7.3.2整个过程会很漫长。2.升级到V6.8.0
首先确认以下两个注意事项:
If the Elasticsearch security features are enabled on your 5.x cluster, before
you can do a rolling upgrade you must encrypt the internode-communication with
SSL/TLS, which requires a full cluster restart. For more information about this
requirement and the associated bootstrap check, see SSL/TLS check.
The format used for the internal indices used by Kibana and X-Pack
has changed in 6.x. When upgrading from 5.6 to 6.x, these internal indices have
to be upgraded
before the rolling upgrade procedure can start. Otherwise the upgraded node will
refuse to join the cluster.
- Disable shard allocation.
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.enable": "primaries"
}
}2.Stop non-essential indexing and perform a synced flush. (Optional)
POST _flush/synced3.Stop any machine learning jobs that are running.
4.Shut down a single node.
5.Upgrade the node you shut down.
If you are upgrading from a version prior to 6.3 and use X-Pack then you must remove the X-Pack plugin before upgrading with bin/elasticsearch-plugin remove x-pack. As of 6.3, X-Pack is included in the default distribution so make sure to upgrade to that one. If you upgrade without removing the X-Pack plugin first the node will fail to start. If you did not remove the X-Pack plugin and the node fails to start then you must downgrade to your previous version, remove X-Pack, and then upgrade again. In general downgrading is not supported but in this particular case it is.
6.Upgrade any plugins.
7.Start the upgraded node.
出现第一个异常:
Caused by: java.lang.IllegalArgumentException: the [action.auto_create_index] setting value [false] is too restrictive. disable [action.auto_create_index] or set it to [.watches,.triggered_watches,.watcher-history-*]解决办法:注释该配置
出现的第二个异常:
max number of threads [2048] for user [elasticsearch] is too low, increase to at least [4096]解决办法:
vi /etc/security/limits.d/90-nproc.conf
* soft nproc 4096
root soft nproc unlimited出现第三个异常:
客户端版本过低导致,需要升级客户端
[2019-11-11T18:38:30,591][WARN ][o.e.t.TcpTransport ] [estest-log-node-101] exception caught on transport layer [Netty4TcpChannel{localAddress=/10.0.6.101:9300, remoteAddress=/10.0.6.147:35746}], closing connection
java.lang.IllegalStateException: Received message from unsupported version: [5.4.1] minimal compatible version is: [5.6.0]8.Reenable shard allocation.
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.enable": null
}
}9.Wait for the node to recover.
10.Repeat
11.Restart machine learning jobs.
Elasticsearch 7.85集群 V5.4.1滚动升级到V5.6.0的流程
共八个节点:
10.0.7.82,10.0.7.83,10.0.7.86,10.0.7.87,10.0.7.88,10.0.7.54,10.0.7.85
10.0.7.81上无ES进程,不升级
优先升级primary sahrd较少的节点
- 准备好安装包,上传到服务器,更改配置,包含elasticsearch.yml(复制),jvm.options(复制),是否还需要配置其他地方?
- 快照备份数据
- 节点升级到V5.6.0
- 整个集群升级完成后删除快照
- 升级160集群到V5.6.0(再续)
- 升级客户端---还需要单独再做测试
风险评估:
1.单个节点升级失败
解决方案:删除节点对应的es-data下的数据,开启V5.4.1,重新加入集群
2.集群的数据被影响
解决方案:从快照恢复数据
恢复期间需要关停索引,对应索引不可用,数据为快照生成时的数据,意味着会丢失一部分数据