本文来自夏立的分享,花名雷飙,阿里巴巴计算平台EMR高级产品专家。
2014年开始接触大数据,历经阿里内部的大数据发展,目前在阿里云上负责开源的大数据平台EMR产品,构建云上的开源生态。
产品介绍
阿里云EMR的整体架构如下:
管理运维能力
- 集群管理,作业管理和调度
- 操作Web化、SDK&API
完全兼容开源系统,并在之基础上强化
- Hadoop, Spark性能优化
- 监控能力能整合强化
伴随社区发展的生态
- 组件跟随开源社区保持版本升级
- 开源与阿里云平台的联结者,充分发挥云的生态能力
- 云产品对接(OSS,SLS,MaxCompute等)
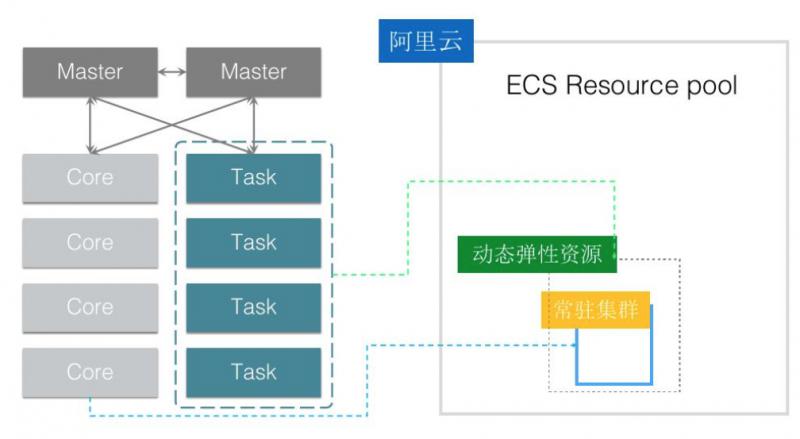
- 云能力对接,弹性等等(本地盘实例严格打散,弹性伸缩能力,支持竞价实例)
全球部署(全球15个region部署)
- 基于企业级开源大数据生态上多样化场景方案的快速复制
提供完整的企业级的一体化平台
- 打包计算平台能力
- 开箱即用的体验
常见的组合使用方式:

大数据平台应用到的组件包括:
通用Hadoop
- 开源大数据离线、实时、Ad-hoc查询场景
- 基于开源Hadoop生态,采用YARN管理集群资源,提供Hive、Spark离线大规模分布式数据存储和计算, SparkStreaming、Flink、Storm流式数据计算,Presto、Impala交互式查询,Oozie、Pig等Hadoop生态圈的组 件,支持OSS存储,支持Kerberos的数据认证与加密。
Kafka
- 开源高吞吐量,可扩展性的消息系统
- E-MapReduce Kafka提供一套完整的服务监控体系和元数据管理。广泛用于日志收集、监控数据聚合等场 景,支持离线或流式数据处理、实时数据分析等。
DataScience
- 大数据+AI场景
- Data Science针对大数据+AI场景,提供了Hive、Spark离线大数据ETL,TensorFlow模型训练,用户可以选 择CPU+GPU的异构计算框架,利用英伟达GPU对部分深度学习算法就行高性能计算。
Druid
- 实时交互式分析服务场景
- Druid提供了大数据查询毫秒级延迟,支持多种数据摄入方式。可与E-MapReduce Hadoop、E-MapReduce Spark、阿里云OSS、阿里云RDS等服务搭配组合使用,构建灵活稳健的实时查询解决方案。
Zookeeper
- 分布式锁
- 适用于大规模的Hadoop集群、HBase集群、Kafka集群独立的分布式一致性锁服务。
产品功能点
可视化集群管理控制台
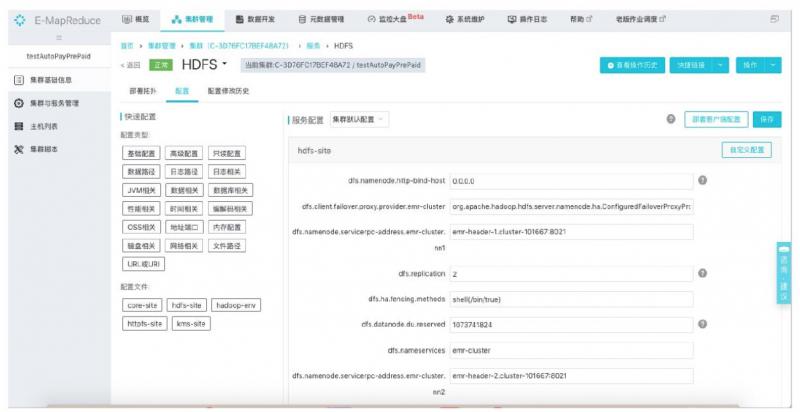
自带的调度系统
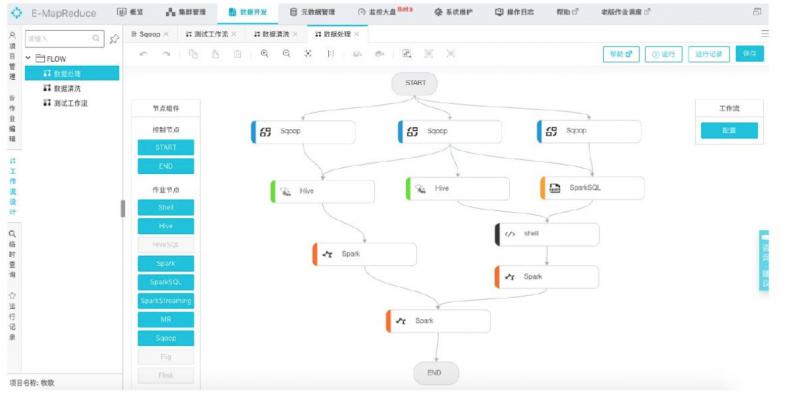
- 项目级别的权限管理
- 支持DAG
- 更好的弹性资源结合
- 方便的多种作业管理
- 完善的报警和监控
机器学习支持
深度学习、AI以成为目前炙手可热的词汇,EMR EMR Cluster Learning将深度学习和开源大数据技术深度结合,提供 一体化的大数据+深度学习服务。利用一个集群,构建 企业数据湖,同时进行机器学习和深度学习:
- 支持ECS GPU机型,通过Hadoop YARN调度集群GPU资源 Spark ML
- TensorFlow Horvod • 支持TensorFlow ,Horvod等计算框架
- 可采用PS、MPI等数据通信模式
- 支持Docker,Standalone运行模式

声明:本号所有文章除特殊注明,都为原创,公众号读者拥有优先阅读权,未经作者本人允许不得转载,否则追究侵权责任。
关注我的公众号,后台回复【JAVAPDF】获取200页面试题!
5万人关注的大数据成神之路,不来了解一下吗?
5万人关注的大数据成神之路,真的不来了解一下吗?
5万人关注的大数据成神之路,确定真的不来了解一下吗?