# 导入相关库 import numpy as np import pandas as pd
拼接
有两个 DataFrame,都存储了用户的一些信息,现在要拼接起来,组成一个 DataFrame。 如何实现?
创建数据
data1 = { www.neuedu.com "name": ["Tom", "Bob"], "age": [18, 30], "city": ["Bei Jing ", "Shang Hai "] } df1 = pd.DataFrame(data=data1) data2 = { "name": ["Mary", "James"], "age": [35, 18], "city": ["Guang Zhou", "Shen Zhen"] } df2 = pd.DataFrame(data=data2)
append 拼接
append 是最简单的拼接两个DataFrame的方法
df1.append(df2)
拼接后的索引默认还是原有的索引,如果想要重新生成索引的话,设置参数ignore_index=True 即可
df1.append(df2, ignore_index=True)
concat 拼接
objs=[df1, df2]
pd.concat(objs, ignore_index=True)
如果想要区分出不同的 DataFrame 的数据,可以通过设置参数 keys,还需要设置参数 ignore_index=False
pd.concat(objs, ignore_index=False, keys=["df1", "df2"])
关联
有两个DataFrame,分别存储了用户的部分信息,现在需要将用户的这些信息关联起来,如何实现呢?
创建数据
data1 = { "name": ["Tom", "Bob", "Mary", "James"], "age": [18, 30, 35, 18], "city": ["Bei Jing ", "Shang Hai ", "Guang Zhou", "Shen Zhen"] } df1 = pd.DataFrame(data=data1) data2 = { "name": ["Bob", "Mary", "James", "Andy"], "sex": ["male", "female", "male", np.nan], "income": [8000, 8000, 4000, 6000] } df2 = pd.DataFrame(data=data2)
merge 关联
通过 pd.merge 可以关联两个 DataFrame,这里我们设置参数 on="name",表示依据
name 来作为关联键
pd.merge(df1, df2, on="name")
关联后发现数据变少了,这是因为默认关联的方式是 inner,如果不想丢失任何数据,可以设置参数 how="outer"
pd.merge(df1, df2, on="name", how="outer")
如果我们想保留左边所有的数据,可以设置参数 how="left"
反之,如果想保留右边的所有数据,可以设置参数 how="right"
pd.merge(df1, df2, on="name", how="left")
两个 DataFrame 中需要关联的键的名称不一样,可以通过 left_on 和 right_on 来分别设置。
df1.rename(columns={"name": "name1"}, inplace=True)
df2.rename(columns={"name": "name2"}, inplace=True)
pd.merge(df1, df2, left_on="name1", right_on="name2")
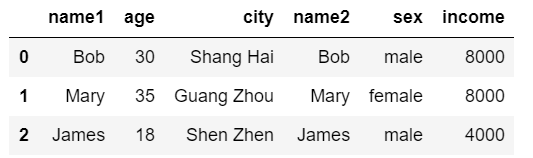
两个 DataFrame 中都包含相同名称的字段,我们可以设置参数 suffixes,默认suffixes=('_x', '_y') 表示将相同名称的左边的 DataFrame 的字段名加上后缀 _x,右边加上后缀 _y
df1["sex"] = "male" pd.merge(df1, df2, left_on="name1", right_on="name2") pd.merge(df1, df2, left_on="name1", right_on="name2", suffixes=("_left", "_right"))

join
除了 merge 这种方式外,还可以通过 join 这种方式实现关联。相比 merge , join 这种方式有以下几个不同:
- 默认参数 on=None ,表示关联时使用左边和右边的索引作为键,设置参数 on 可以指定的是关联时左边的所用到的键名
- 左边和右边字段名称重复时,通过设置参数 lsuffix 和 rsuffix 来解决
df1.join(df2.set_index("name2"), on="name1", lsuffix="_left")
