链接:https://www.zhihu.com/question/352256403/answer/878523206
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
题主,恭喜你,你深入思考了一系列重要问题,作为一个开源技术人员+数据中间件的爱好者,试着回答一下题主的几个问题:
- 什么时候需要数据中间件,中间件能干什么
- 数据中间件的实现原理,有哪些开源数据中间件
- 为什么都是国内开源的,并且大都停止了更新
- 推荐使用什么数据中间件,有什么优势
一、什么时候需要数据中间件,中间件能干什么
就像题主说的那样,随着业务的发展,MySQL、Oracle数据库里的表越来越大,一两年以后,2千万、甚至上亿记录的表就会出现了(一般可以简单认为表比较复杂的时候,MySQL几百万上千万的时候,Oracle几千万的时候,就会出现复杂查询或变更有性能问题),这时候可能会导致复杂的查询慢,插入和修改数据慢,修改表的DDL执行太慢导致无法修改列类型或者加索引或者加字段等等。怎么办呢?这时候我们可以由几个处理办法:
- 历史表:按时间拆分历史表出去,降低数据量,这个以前比较常见,其实也是一种特殊的水平拆分,对业务有侵入性
- 垂直拆分:按列,将上百列的宽表拆分成多个列少(也就是每条记录数据量小)的表,不降低记录数,但是降低整个表的数据量和索引量大小
- 水平拆分:按某个或某些个列的值哈希后,均匀的将数据拆分到多个同样的库or表里,这样就直接降低了单库单表的数据量,比如说拆分成1024个子表,就可以将单表的数据量降低3个数量级,原来一亿的表,现在单表10万数据,在单表上做复杂操作都可以很快速了。这样的缺点就是,原来只需要操作一个表,现在操作之前需要先知道要操作那张表,比如一个用户表,按uid分表:原来的SQL1: select * from users where uid=1025,现在得先知道uid是1025,然后知道1025%1024==1,SQL就变成了SQL2: select * from users_0001 where uid=1025,看起来对业务也是于侵入型的。怎么能对业务变得透明,这就需要一个中间件,帮我们自动的把SQL1变成SQL2,从而使得我们分不分库、分不分表,分多少个,代码都差不多,不用太多修改。
- 读写分离:比如MySQL的TPS/QPS都已经很高了,几千上万,而且已经做了1主3从的时候,我们希望这4个实例都能分担一些压力,特别是读多写少的情况,如果把读的压力大家平分,就可以降低主库的读压力,让主库关注与写。这时候也需要一个中间件来把数据请求路由到不同的库上。
如果我们的业务发展到了需要降低单库单表的压力、或者读写分离,而研发团队又不大,自己对这一块的技术积累不足以自己开发一些中间层代码去搞定问题,就像题主一样,需要考虑引入数据中间件了。为什么都是国内大场开源的数据中间件,小公司数据量不够,或技术不够,不需要自己开发中间件,量上来以后,如果使用场景简单,采用开源技术是最经济的解决办法。大公司有能力自己搞定数据中间件,我们现在知道的都是这部分里面开源出来的,特别是近几年,就像有个答主说的一样,大家都在搞分布式数据库了,分布式数据库的容量上限,远大于传统的关系数据库MySQL/Oracle,可以考虑是把中间件的部分功能固化到数据库里了,这些公司不太关注这些问题了。另一方面,有些数据中间件,融入云的体系,变成闭源的RDS里的一部分了。
二、数据中间件的实现原理,有哪些开源数据中间件
简单的说,有两种原理:
- 客户端JDBC模式:中间件作为一个jar包之类的库,例如下图中的示意,只需要直接在项目里引用,配置好分库分表规则,用中间件包装一层JDBC数据源,即可每次在调用的时候,JDBC包装类里自动替换好SQL,再调用实际的JDBC和SQL,即可完成操作。但是由于需要直接操作单个库和表,所以对于SQL会有一些限制,必须带上确定的分库分表条件,不能有太复杂的聚合操作等。
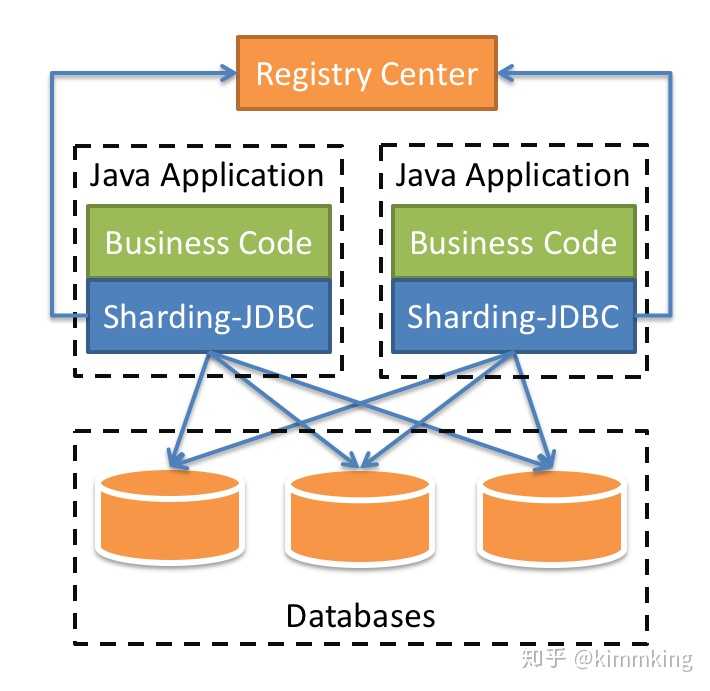
- 代理Proxy模式:
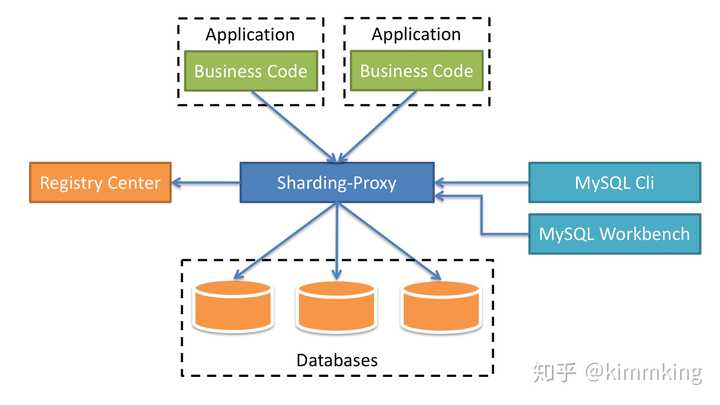
早期主流的开源中间件如下图:
引自:https://blog.csdn.net/w892824196/article/details/82660415
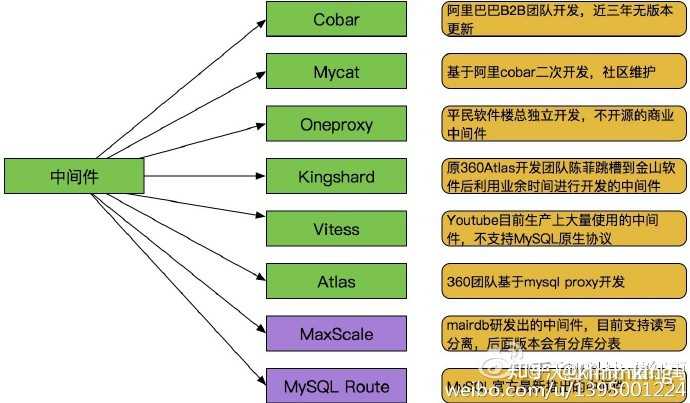
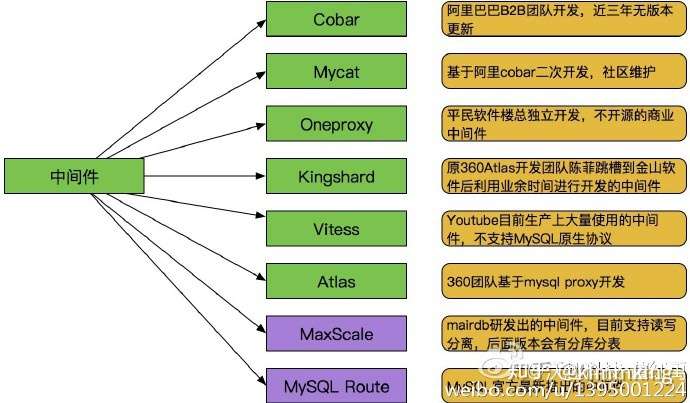
- Cobar:阿里巴巴B2B开发的关系型分布式系统,管理将近3000个MySQL实例。 在阿里经受住了考验,后面由于作者的走开的原因cobar没有人维护 了,阿里也开发了tddl替代cobar。
- MyCAT:社区爱好者在阿里cobar基础上进行二次开发,解决了cobar当时存 在的一些问题,并且加入了许多新的功能在其中。目前MyCAT社区活 跃度很高,目前已经有一些公司在使用MyCAT。总体来说支持度比 较高,也会一直维护下去,
- OneProxy:数据库界大牛,前支付宝数据库团队领导楼总开发,基于mysql官方 的proxy思想利用c进行开发的,OneProxy是一款商业收费的中间件, 楼总舍去了一些功能点,专注在性能和稳定性上。有朋友测试过说在 高并发下很稳定。
- Vitess:这个中间件是Youtube生产在使用的,但是架构很复杂。 与以往中间件不同,使用Vitess应用改动比较大要 使用他提供语言的API接口,我们可以借鉴他其中的一些设计思想。
- Kingshard:Kingshard是前360Atlas中间件开发团队的陈菲利用业务时间 用go语言开发的,目前参与开发的人员有3个左右, 目前来看还不是成熟可以使用的产品,需要在不断完善。
- Atlas:360团队基于mysql proxy 把lua用C改写。原有版本是支持分表, 目前已经放出了分库分表版本。在网上看到一些朋友经常说在高并 发下会经常挂掉,如果大家要使用需要提前做好测试。
- MaxScale与MySQL Route:这两个中间件都算是官方的吧,MaxScale是mariadb (MySQL原作者维护的一个版本)研发的,目前版本不支持分库分表。MySQL Route是现在MySQL 官方Oracle公司发布出来的一个中间件。
- ShardingSphere,后起之秀,源于当当网架构部的ShardingJDBC框架。
上面都是提到了分布分表和读写分离的中间件,其实还有一些专注于分布式事务的、数据复制传输的等等,比如fescar,canal、outter等等。
其实淘宝早期开源了TDDL,淘宝分布式数据中间层,但是只开源了客户端jdbc模式,没有开源proxy代理模式。
三、为什么都是国内开源的,并且大都停止了更新
国内的开源,部分是大公司主导的技术影响力输出,部分是个人的兴趣之作贡献给社区,总而言之是没有直接的显著回报的。也就是说,这一块一直没有一个稳定可行的商业模式来支持,所以一直以来,大公司实际上也看不上,因为赚不了钱,而没有回报的事情就无法长久,所以自然就停止了更新。对于个别有云服务的公司,这一块技术发展好了,其实可以并到云里提供数据服务,或者进一步的发展成为分布式数据库,这样可以变现了,那就闭源,所以,现在活跃的开源数据中间件,已经不多了,下面就推荐一个活跃的项目。
四、推荐使用什么数据中间件--ShardingSphere
推荐使用近期加入Apache基金会的第一款数据中间件,也是国人开发的,ShardingSphere项目。可以直接在这个项目的github commits记录看到,非常活跃,每天都有提交记录,issue也一直在持续维护。为什么还活得这么好呢?因为有张亮团队的专职在开发、维护和推广。
详细文档和代码参见:
ShardingSphereshardingsphere.apache.org apache/incubator-shardingspheregithub.com
apache/incubator-shardingspheregithub.com
ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、云原生等各种多样化的应用场景。
ShardingSphere定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。 它与NoSQL和NewSQL是并存而非互斥的关系。NoSQL和NewSQL作为新技术探索的前沿,放眼未来,拥抱变化,是非常值得推荐的。反之,也可以用另一种思路看待问题,放眼未来,关注不变的东西,进而抓住事物本质。 关系型数据库当今依然占有巨大市场,是各个公司核心业务的基石,未来也难于撼动,我们目前阶段更加关注在原有基础上的增量,而非颠覆。
稍后我推荐ShardingSphere项目的两个主要PMC,@张亮 和 @曹昊,来关注一下这个问题。