一. SKB_BUFF的基本概念
1. 一个完整的skb buff组成
(1) struct sk_buff--用于维护socket buffer状态和描述信息
(2) header data--独立于sk_buff结构体的数据缓冲区,用来存放报文分组,使各层协议的header存储在连续的空间中,以方便协议栈对其操作
(3) struct skb_shared_info --作为header data的补充,用于存储ip分片,其中sk_buff *frag_list是一系列子skbuff链表,而frag[]是由一组单独的page组成的数据缓冲区
skb buff结构图如下:

struct skb_buff
表示接收或发送数据包的包头信息,其成员变量在从一层向另一层传递时会发生修改。例如L3向L2传递前,会添加一个L3的头部,所以在添加头部前调用skb_reserve在缓冲区的头部给协议头预留一定的空间;L2向L3传递时候,L2的头部只有在 网络驱动处理L2的协议时有用,L3是不会关心它的信息的。但是,内核不会把L2的头部从缓冲区中删除,
sk_buff->h
sk_buff->nh
sk_buff->mac
指向TCP/IP各层协议头的指针:h指向L4(传输层),nh指向L3(网络层),mac指向L2(数据链路层)。每个指针的类型都是一个联合, 包含多个数据结构,
sk_buff->head
sk_buff->data
sk_buff->tail
sk_buff->end
表示缓冲区和数据部分的边界。在每一层申请缓冲区时,它会分配比协议头或协议数据大的空间。head和end指向缓冲区的头部和尾部,而data和 tail指向实际数据的头部和尾部。每一层会在head和data之间填充协议头,或者在tail和end之间添加新的协议数据。数据部分会在尾部包含一 个附加的头部。
下图是TCP(L4)向下发送数据给链路层L2的过程。注意skb_buff->data在从L4向L2穿越过程中的变化

几个len的区别?
(1)sk_buff->len:表示当前协议数据包的长度。它包括主缓冲区中的数据长度(data指针指向它)和分片中的数据长度。比如,处在网络层,len指的是ip包的长度,如果包已经到了应用层,则len是应用层头部和数据载荷的长度。
(2)sk_buff->data_len: data_len只计算分片中数据的长度,即skb_shared_info中有效数据总长度(包括frag_list,frags[]中的扩展数据),一般为0
(3)sk_buff->truesize:这是缓冲区的总长度,包括sk_buff结构和数据部分。如果申请一个len字节的缓冲区,alloc_skb函数会把它初始化成len+sizeof(sk_buff)。当skb->len变化时,这个变量也会变化。
通常,Data Buffer 只是一个简单的线性 buffer,这时候 len 就是线性 buffer 中的数据长度;
但在有 ‘paged data’ 情况下, Data Buffer 不仅包括第一个线性 buffer ,还包括多个 page buffer;这种情况下, ‘data_len’ 指的是 page buffer 中数据的长度,’len’ 指的是线性 buffer 加上 page buffer 的长度;len – data_len 就是线性 buffer 的长度。
二. sk_buff结构操作函数
内核通过alloc_skb()和dev_alloc_skb()为套接字缓存申请内存空间。这两个函数的定义位于net/core/skbuff.c文件内。通过这alloc_skb()申请的内存空间有两个,一个是存放实际报文数据的内存空间,通过kmalloc()函数申请;一个是sk_buff数据结构的内存空间,通过 kmem_cache_alloc()函数申请。dev_alloc_skb()的功能与alloc_skb()类似,它只被驱动程序的中断所调用,与alloc_skb()比较只是申请的内存空间长度多了16个字节。
内核通过kfree_skb()和dev_kfree_skb()释放为套接字缓存申请的内存空间。dev_kfree_skb()被驱动程序使用,功能与kfree_skb()一样。当skb->users为1时kfree_skb()才会执行释放内存空间的动作,否则只会减少skb->users的值。skb->users为1表示已没有其他用户使用该缓存了。
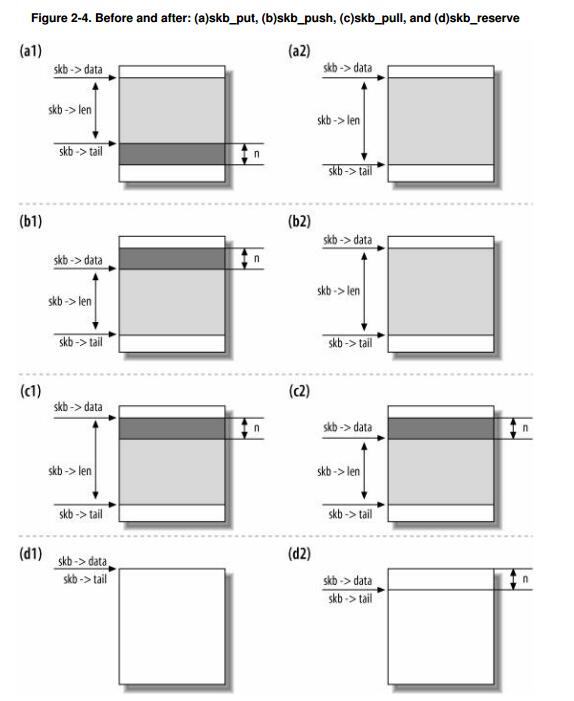
skb操作中的预留和对齐操作主要由skb_put、skb_push、skb_pull、skb_reserve完成;另外,需要注意的是;
skb_reserve()函数为skb_buff缓存结构预留足够的空间来存放各层网络协议的头信息。该函数在在skb缓存申请成功后,加载报文数据前执行,即在分配了空间,尚未填充数据时调用。在执行skb_reserve()函数前,skb->head,skb->data和skb->tail指针的位置的一样的,都位于skb内存空间的开始位置。这部份空间叫做headroom。有效数据后的空间叫tailroom。skb_reserve的操作只是把skb->data和skb->tail指针向后移,但缓存总长不变。
运行skb_reserve()前sk_buff的结构
sk_buff
---------------------- ----------> skb->head,skb->data,skb->tail
| |
| |
| |
| |
| |
| |
| |
| |
| |
--------------------- ----------> skb->end
运行skb_reserve()后sk_buff的结构
sk_buff
---------------------- ----------> skb->head
| |
| headroom |
| |
|--------------------- | ----------> skb->data,skb->tail
| |
| |
| |
| |
| |
--------------------- ----------> skb->end
skb_put()向后扩大数据区空间,tailroom空间减少,skb->data指针不变,skb->tail指针下移。
skb_push()向前扩大数据区空间,headroom空间减少,skb->tail指针不变,skb->data指针上移
skb_pull()缩小数据区空间,headroom空间增大,skb->data指针下移,skb->tail指针不变。
skb_shared_info结构位于skb->end后,用skb_shinfo函数申请内存空间。该结构主要用以描述data内存空间的信息。
--------------------- -----------> skb->head
| |
| |
| sk_buff |
| |
| |
| |
|---------------------| -----------> skb->end
| |
| skb_share_info |
| |
---------------------
skb_clone和skb_copy可拷贝一个sk_buff结构,skb_clone方式是clone,只生成新的sk_buff内存区,不会生成新的data内存区,新sk_buff的skb->data指向旧data内存区。skb_copy方式是完全拷贝,生成新的sk_buff内存区和data内存区。
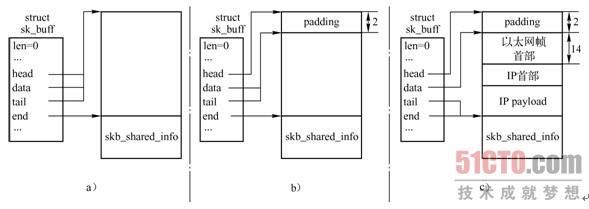
1.skb_reserve()
skb_reserve()在数据缓存区头部预留一定的空间,通常被用来在数据缓存区中插入协议首部或者在某个边界上对齐。它并没有把数据移出或移入数据缓存区,而只是简单地更新了数据缓存区的两个指针-分别指向负载起始和结尾的data和tail指针,图3-15 展示了调用skb_reserve()前后这两个指针的变化。
请注意:skb_reserve()只能用于空的SKB,通常会在分配SKB之后就调用该函数,此时data和tail指针还一同指向数据区的起始位置,如图3-15a所示。例如,某个以太网设备驱动的接收函数,在分配SKB之后,向数据缓存区填充数据之前,会有这样的一条语句skb_reserve(skb, 2),这是因为以太网头长度为14B,再加上2B就正好16字节边界对齐,所以大多数以太网设备都会在数据包之前保留2B。
当SKB在协议栈中向下传递时,每一层协议都把skb->data指针向上移动,然后复制本层首部,同时更新skb->len。这些操作都使用图3-15 中所示的函数完成。
2.skb_push()
skb_push()在数据缓存区的前头加入一块数据,与skb_reserve()类似,也并没有真正向数据缓存区中添加数据,而只是移动数据缓存区的头指针data和尾指针tail。数据由其他函数复制到数据缓存区中。
函数执行步骤如下:
1)当TCP发送数据时,会根据一些条件,如TCP最大分段长度MSS、是否支持聚合分散I/O等,分配一个SKB。
2)TCP需在数据缓存区的头部预留足够的空间,用来填充各层首部。MAX_TCP_HEADER是各层首部长度的总和,它考虑了最坏的情况:由于TCP层不知道将要用哪个接口发送包,它为每一层预留了最大的首部长度,甚至还考虑了出现多个IP首部的可能性,因为在内核编译支持IP over IP的情况下,会遇到多个IP首部。
3)把TCP负载复制到数据缓存区。需要注意的是,图3-16 只是一个例子,TCP负载可能会被组织成其他形式,例如分片,在后续章节中将会看到一个分片的数据缓存区是什么样的。
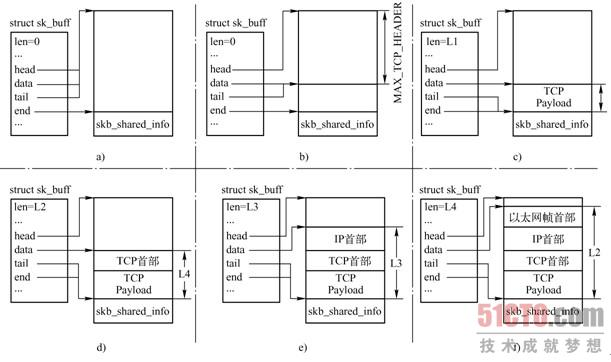
4)TCP层添加TCP首部。
5)SKB传递到IP层,IP层为数据包添加IP首部。
6)SKB传递到链路层,链路层为数据包添加链路层首部。
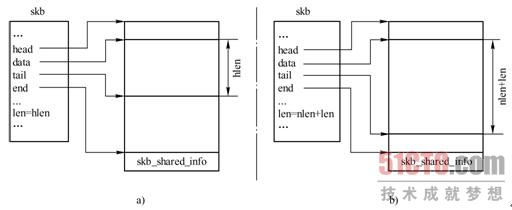
3.skb_put()
skb_put()修改指向数据区末尾的指针tail,使之往下移len字节,即使数据区向下扩大len字节,并更新数据区长度len。调用skb_put()前后,SKB结构变化如图3-17所示。
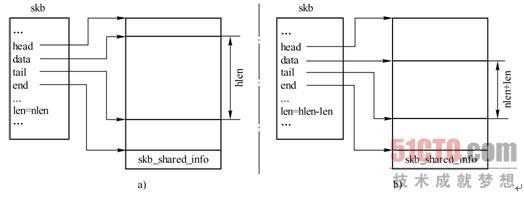
4.skb_pull()
skb_pull()通过将data指针往下移动,在数据区首部忽略len字节长度的数据,通常用于接收到数据包后在各层间由下往上传递时,上层忽略下层的首部。调用skb_pull()前后,SKB结构变化如图3-18所示。
三. skb 的分配细节
1. 关于 SKB 的分配细节.
LINUX 中 SKB 的分配最终是由函数 : struct sk_buff *__alloc_skb(unsigned int size, gfp_t gfp_mask,int fclone) 来完成.
SKB 可以分为 SKB 描述符与 SKB 数据区两个部分,其中描述符必须从 CACHE 中来分配 : 或者从skbuff_fclone_cache 中分配,或者从 skbuff_head_cache 中来分配.
如果从分配描述符失败,则直接反悔 NULL,表示 SKB 分配失败.
SKB 描述符分配成功后,即可分配数据区.
在具体分配数据区之前首先要对数据区的长度进行 ALIGN 操作, 通过宏 SKB_DATA_ALIGN 来重新确定 size 大小. 然后戏台调用 kmalloc 函数分配数据区 :
data = kmalloc(size + sizeof(struct skb_shared_info), gfp_mask);
需要注意的是数据区的大小是 SIZE 的大小加上 skb_shared_info 结构的大小.
数据区分配成功后,便对 SKB 描述符进行与此数据区相关的赋值操作 :
memset(skb, 0, offsetof(struct sk_buff, truesize));
skb->truesize = size + sizeof(struct sk_buff);
atomic_set(&skb->users, 1);
skb->head = data;
skb->data = data;
skb->tail = data;
skb->end = data + size;
需要主意的是, SKB 的 truesize 的大小并不包含 skb_shared_info 结构的大小. 另外,skb 的 end 成员指针也就是skb_shared_info 结构的起始指针,系统用
一个宏 : skb_shinfo 来完成寻找 skb_shared_info 结构指针的操作.
最后,系统初始化 skb_shared_info 结构的成员变量 :
atomic_set(&(skb_shinfo(skb)->dataref), 1);
skb_shinfo(skb)->nr_frags = 0;
skb_shinfo(skb)->tso_size = 0;
skb_shinfo(skb)->tso_segs = 0;
skb_shinfo(skb)->frag_list = NULL;
skb_shinfo(skb)->ufo_size = 0;
skb_shinfo(skb)->ip6_frag_id = 0;
最后,返回 SKB 的指针.
2. SKB 的分配时机
SKB 的分配时机主要有两种,最常见的一种是在网卡的中断中,有数据包到达的时,系统分配 SKB 包进行包处理; 第二种情况是主动分配 SKB 包用于各种调试或者其他处理环境.
3. SKB 的 reserve 操作
SKB 在分配的过程中使用了一个小技巧 : 即在数据区中预留了 128 个字节大小的空间作为协议头使用, 通过移动 SKB 的 data 与 tail 指针的位置来实现这个功能.
4. SKB 的 put 操作
put 操作是 SKB 中一个非常频繁也是非常重要的操作, 但是, skb_put()函数其实什么也没做!
它只是根据数据的长度移动了 tail 指针并改写了 skb->len 的值,其他的什么都没做,然后就返回了 skb->data 指针(就是 tail 指针在移动之前的位置). 看上去此函数仿佛要拷贝数据到 skb 的数据区中,其实这事儿是 insl 这个函数干的,跟 skb_put() 函数毫不相关,不过它仍然很重要.
5. 中断环境下 SKB 的分配流程
当数据到达网卡后,会触发网卡的中断,从而进入 ISR 中,系统会在 ISR 中计算出此次接收到的数据的字节数 : pkt_len, 然后调用 SKB 分配函数来分配 SKB :
skb = dev_alloc_skb(pkt_len+5);
我们可以看到, 实际上传入的数据区的长度还要比实际接收到的字节数多,这实际上是一种保护机制. 实际上,在 dev_alloc_skb 函数调用 __dev_alloc_skb 函数,而 __dev_alloc_skb 函数又调用 alloc_skb 函数时,其数据区的大小又增加了 128 字节, 这 128 字节就事前面我们所说的 reserve 机制预留的 header 空间.
四. 不同情况下构造skb数据包的实现
http://blog.csdn.net/efan_linux/archive/2009/09/23/4580024.aspx
在我这个网络接口的程序中(can0),其实难点就是怎样组包。怎样在原来数据包的基础加上自己的数据,怎样构造ip头,怎样构造udp头。
调试了两个星期,终于是调通了,在这个过程中,通过看内核源代码和自己组包的尝试,大概对组包的方法有了些了解,记录在此,留做备忘,也希望能给需要这方面信息的朋友一点帮助吧。
1,正常网卡收到数据包后的情况:
她的工作就是剥离mac头,然后给一些字段赋值,最后调用netif_rx将剥离mac头后的数据报(比如ip数据包)发送到上层协议。由协议栈处理。在此以ldd3中的snull为例,虽然snull跟硬件不相关,但这个过程都是类似的。
1 struct sk_buff *skb; 2 struct snull_priv *priv = netdev_priv(dev); 3 4 skb = dev_alloc_skb(pkt->datalen + 2); 5 if (!skb) { 6 if (printk_ratelimit()) 7 printk(KERN_NOTICE "snull rx: low on mem - packet dropped/n"); 8 priv->stats.rx_dropped++; 9 goto out; 10 } 11 skb_reserve(skb, 2); /* align IP on 16B boundary */ 12 memcpy(skb_put(skb, pkt->datalen), pkt->data, pkt->datalen); 13 14 /* Write metadata, and then pass to the receive level */ 15 skb->dev = dev; 16 skb->protocol = eth_type_trans(skb, dev); 17 skb->ip_summed = CHECKSUM_UNNECESSARY; /* don't check it */ 18 priv->stats.rx_packets++; 19 priv->stats.rx_bytes += pkt->datalen; 20 netif_rx(skb);
注意:上面代码中红色放大的地方是重要的。
因为此刻收到的数据包的格式如下:mac+ip+udp/udp+data
这时候的处理就是剥离mac头,然后需要更新的一些域值。这些都是在函数eth_type_trans函数里做的。需要注意的是,skb->dev = dev;这条语句是很重要的,如果没有此语句,将会导致系统错误而死机(至少在我的板子上是这样的)。
注意:eth_type_trans()函数主要赋值的是:
skb->mac.raw,skb->protocol和skb->pkt_type。见下面的代码有无mac头的情况。
2,完全从一个字符串开始构造一个新的skb数据包。
以前只是看过如何修改数据包,自己构造数据包,这还是头一次,刚开始确实给我难住了,来来经过看内核代码和自己摸索,我自己写的代码如下:
1 /*假设:data是一个指向字符串的指针,data_len是data的长度*/ 2 3 struct ipv6hdr *ipv6h; 4 struct udphdr *udph; 5 struct sk__buff * new_skb; 6 7 int length = data_len + sizeof(struct ipv6hdr) + sizeof(udphdr); 8 new_skb = dev_alloc_skb(length); 9 if(!new_skb) 10 { 11 printk("low memory.../n"): 12 return -1; 13 } 14 15 skb_reserve(new_skb,length); 16 17 memcpy(skb_push(new_skb,data_len),data,data_len); 18 19 new_skb->h.uh = udph = (struct udphdr *)skb_push(new_skb,sizeof(struct udphdr)); 20 memcpy(udph,&udph_tmp,sizeof(struct udphdr)); //注意,此刻我的udph_tmp是在另一个过程中截获的数据包的udp头,如果完全是自己构造数据包,则需要自己填充udp数据头中的字段。 21 22 23 udph->len = .............. ; //此处需要给udph->len赋值。注意udph->len是__u16的。存储时是高低位互换的,所以你应该先将你要更新的数字编成16进制的数,然后高低位互换,在赋值给udh->len。 24 25 udplen = new_skb->len; 26 27 new_skb->nh.ipv6h = ipv6h = (struct ipv6hdr *)skb_push(new_skb,sizeof(struct ipv6hdr)); 28 memcpy(ipv6h,&ipv6h_tmp,sizeof(struct ipv6hdr)); //同udp头注释。 29 30 ipb6h->payload_len = ..........; //此处同udph->len.需要注意的是,此处所指的长度并不包括ipv6头的长度,而是去掉ipv6头后的长度。 31 32 udph->check = 0; 33 udph->check = csum_ipv6_magic(&ipv6h->saddr, &ipv6h->daddr, udplen, IPPROTO_UDP, csum_partial((char *)udph, udplen, 0)); 34 35 ///////////////注意,如果是ipv4,则还需要计算ip校验和,但此处是ipv6,不用计算ip检验和,所以此处没有ipv6头的校验。////////////////////////// 36 37 new_skb->mac.raw = new_skb->data; //因为无mac头 38 new_skb->protocol = htons(ETH_P_IPV6); //表明包是ipv6数据包 39 new_skb->pkt_type = PACKET_HOST; //表明是发往本机的包 40 41 new_skb->dev = &can_control; //此处很重要,如果没有这条语句,则内核跑死。至少在我板子上是这样的。can_control是我的net_device结构体变量。 42 43 netif_rx(new_skb);
3,当需要改变原有skb的数据域的情况。
此时,有两种办法:
可以先判断skb的tailroom,如果空间够大,则我们可以把需要添加的数据放在skb的tailroom里。如果tailroom不够大,则需要调用skb_copy_expand函数来扩充tailroom或者headroom。
例如我们需要在skb的后面加上一个16个字节的字符串,则代码类似如下:
1 if(skb_tailroom(skb) < 16) 2 { 3 nskb = skb_copy_expand(skb, skb_headroom(skb), skb_tailroom(skb)+16,GFP_ATOMIC); 4 if(!nskb) 5 { 6 printk("low memory..../n"); 7 dev_kfree_skb(skb); 8 return -1; 9 } 10 11 else 12 { 13 kfree_skb(skb); // 注意,如果此时是钩子函数钩出来的,则skb不能在这里释放,否则会造成死机。 14 15 skb = nskb; 16 } 17 18 memcpy(skb_put(skb,16),ipbuf,16); //ipbuf为要加到skb后面的字符串 19 20 udplen = skb->len - sizeof(struct ipv6hdr); 21 22 udph->len += 0x1000; //换成十进制为 + 16 23 24 ipv6h->payload_len += 0x1000; 25 26 udph->check = 0; 27 udph->check = csum_ipv6_magic(&ipv6h->saddr, &ipv6h->daddr, udplen, IPPROTO_UDP, csum_partial((char *)udph,udplen,0)); 28 29 skb->mac.raw = new_skb->data; //因为无mac头 30 31 skb->protocol = htons(ETH_P_IPV6); //表明包是ipv6数据包 32 33 skb->pkt_type = PACKET_HOST; //表明是发往本机的包 34 35 36 skb->dev = &can_control; //此处很重要,如果没有这条语句,则内核跑死。至少在我板子上是这样的。can_control是我的net_device结构体变量。 37 38 39 netif_rx(skb); 40 }
注意:当调用skb_copy_expand或者修改了skb的数据域后,一定要更新udph->len和ipv6h->payload_len。否则上层应用(比如udp套接字)收到的数据包还是原来的数据包而不是修改后的数据包,因为udph->len的原因。