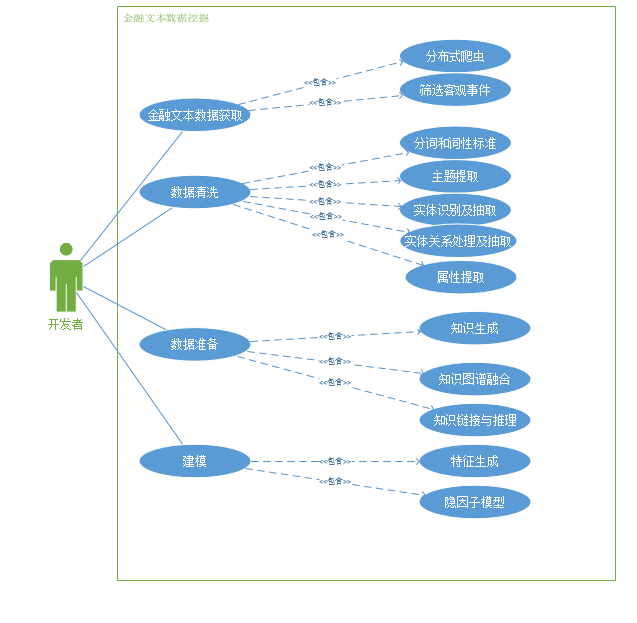
金融文本挖掘中的针对业务的用例建模
在对金融文本数据进行挖掘时,我们需要先获取金融的文本数据,经小组讨论决定,通过分布式爬虫来获取新浪新闻,
这是第一阶段。
第二价段是对数据进行清洗,将得到的文本数据进行处理,包括分词、主题提取、实体识别、实体抽取、关系抽取、属性提取、实体关系处理。
第三阶段是数据准备,主要内容是知识生成、知识图谱融合(基于词向量)、知识链接与推理。
最后是利用数据准备的特征来构建隐因子模型。
作为开发者来说,即该项目的业务项目主要是上述的几个阶段。
但对于使用该模型的用户来说该业务是给用户提供一个基于客观事件的知识推理的金融模型,
对用户的客观实体的输入给出一些可能与之有关的一些结果。
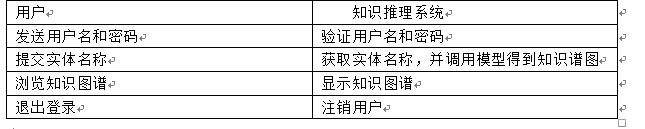
开发者用例建模
用户用例建模

High Level Use Case
所谓的高级用例用来描述用户用例的开始与结束等方面更为具体的细节。
在这里我们选取一个用例来做进一步的分析

Expanded Use Case
扩展用例则是用来描述参与者和系统如何交互以完成业务任务的这样一个过程。
我们依然使用用户用例来进行分析