在SQL语言中去重是一件相当简单的事情,面对一个表(也可以称之为DataFrame)我们对数据进行去重只需要GROUP BY 就好。
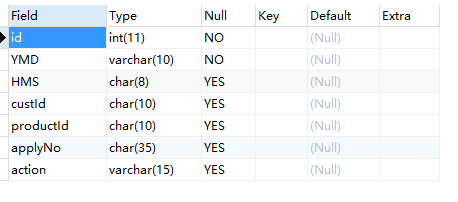
select custId,applyNo from tmp.online_service_startloan group by custId,applyNo
但是对于pandas的DataFrame格式就比较麻烦,我看了其他博客优化了如下三种方案。
我们先引入数据集:
import pandas as pd data=pd.read_csv(r'D:/home/nohup.out.20191028.startloan.csv',encoding='utf-8') print(data.info())

共有14936条数据,那我们还是按 custId和applyNo去重。
1.使用list后手写去重
定义去重函数:我这里使用了遍历行,添加列表的的方式去重。
# 定义去重函数 def dropRep(df): list2=[] for _,i in df.iterrows(): i=list(i) if i not in list2: list2.append(i) return list2
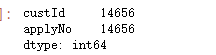
keydata=data[['custId','applyNo']] len1=keydata.count() print('去重之前custId +applyNo:',len1) list2=dropRep(keydata) print('去重之后custId +applyNo:',len(list2))
2.使用list后set去重
用set去重其实遇到了很多问题,set里面的数据必须是不可变数据类型,可hash等等。。所以只能把key1+key2拼成字符串作为一个元素。
# 定义去重函数 def dropRepBySet(df): set1=set() for _,i in df.iterrows(): set1.add("_".join(list(map(lambda x:str(x),list(i))))) return list(set1)
而且明显感觉这个方法比上面手写list遍历去重快一些
扫描二维码关注公众号,回复:
7707476 查看本文章

keydata=data[['custId','applyNo']] len1=keydata.count() print('去重之前custId +applyNo:',len1) list2=dropRepBySet(keydata) print('去重之后custId +applyNo:',len(list2))

3.使用pd.DataFrame自带drop_duplicates()函数去重
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
- subset : column label or sequence of labels, optional
用来指定特定的列,默认所有列
- keep : {‘first’, ‘last’, False}, default ‘first’
first删除重复项并保留第一次出现的项,last删除重复保留最后一条,False就是删除重复、只要不重复的数据
- inplace : boolean, default False
是直接在原来数据上修改还是保留一个副本
keydata.drop_duplicates().count()
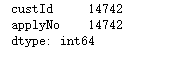
keydata.drop_duplicates(keep=False).count()