如果对java7和java8的hashmap源码分析,
1.可查看博客:
https://www.cnblogs.com/jajian/p/10385063.html#autoid-0-0-0,
2.如果对文字类无感,可以观看视频:
https://www.bilibili.com/video/av71408100?from=search&seid=805805466626935035
以下是自我学习总结笔记
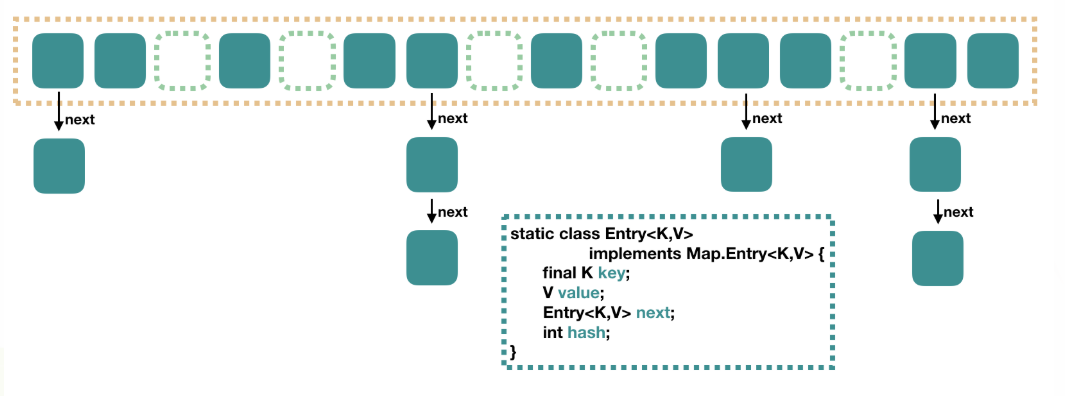
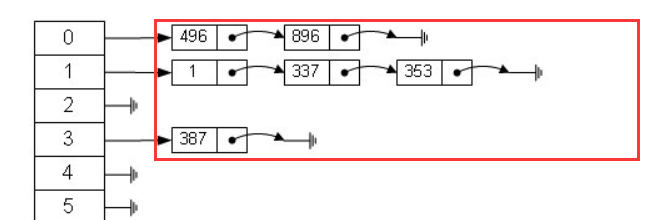
1.java7 , HashMap结构(数组+链表)
2.“模”运算的消耗比较大,采用哈希值进行位移的操作方式
static int indexFor(int h, int length) { return h & (length-1); }
3.哈希冲突(如果两个不同对象的 hashCode 相同,此情况即称为哈希冲突),会单独产生单链结构(如果hash值一般,在相同的数组会创建一个单链存放)
4.hashmap源码三个参数表示
capacity:当前数组容量,始终保持 2^n,可以扩容,扩容后数组大小为当前的 2 倍。
loadFactor:负载因子,默认为0.75(加载因子是表示Hash表中元素的填满的程度。)。
threshold:扩容的阈值,等于 capacity * loadFactor。
5.源码分析
public V put(K key, V value) { // 当插入第一个元素的时候,需要先初始化数组大小 if (table == EMPTY_TABLE) { inflateTable(threshold); } // 如果 key 为 null,感兴趣的可以往里看,最终会将这个 entry 放到 table[0] 中 if (key == null) return putForNullKey(value); // 1. 求 key 的 hash 值 int hash = hash(key); // 2. 找到对应的数组下标 int i = indexFor(hash, table.length); // 3. 遍历一下对应下标处的链表,看是否有重复的 key 已经存在, // 如果有,直接覆盖,put 方法返回旧值就结束了 for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; // 4. 不存在重复的 key,将此 entry 添加到链表中,细节后面说 addEntry(hash, key, value, i); return null; }
1.数组初始化(inflateTable)
private void inflateTable(int toSize) { // 保证数组大小一定是 2 的 n 次方。 // 比如这样初始化:new HashMap(20),那么处理成初始数组大小是 32 int capacity = roundUpToPowerOf2(toSize); // 计算扩容阈值:capacity * loadFactor threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1); // 算是初始化数组吧 table = new Entry[capacity]; initHashSeedAsNeeded(capacity); //ignore }
2.添加节点到链表中(addEntry)
void addEntry(int hash, K key, V value, int bucketIndex) { // 如果当前 HashMap 大小已经达到了阈值,并且新值要插入的数组位置已经有元素了,那么要扩容 if ((size >= threshold) && (null != table[bucketIndex])) { // 扩容,后面会介绍一下 resize(2 * table.length); // 扩容以后,重新计算 hash 值 hash = (null != key) ? hash(key) : 0; // 重新计算扩容后的新的下标 bucketIndex = indexFor(hash, table.length); } // 往下看 createEntry(hash, key, value, bucketIndex); } // 这个很简单,其实就是将新值放到链表的表头,然后 size++ void createEntry(int hash, K key, V value, int bucketIndex) { Entry<K,V> e = table[bucketIndex]; table[bucketIndex] = new Entry<>(hash, key, value, e); size++; }
3.数组扩容(resize)
void resize(int newCapacity) { Entry[] oldTable = table; int oldCapacity = oldTable.length; if (oldCapacity == MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return; } // 新的数组 Entry[] newTable = new Entry[newCapacity]; // 将原来数组中的值迁移到新的更大的数组中 transfer(newTable, initHashSeedAsNeeded(newCapacity)); table = newTable; threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1); }
4.get 过程分析
根据 key 计算 hash 值。
找到相应的数组下标:hash & (length - 1)。
遍历该数组位置处的链表,直到找到相等(==或equals)的 key。
public V get(Object key) { // 之前说过,key 为 null 的话,会被放到 table[0],所以只要遍历下 table[0] 处的链表就可以了 if (key == null) return getForNullKey(); // Entry<K,V> entry = getEntry(key); return null == entry ? null : entry.getValue(); }
getEntry(key):
final Entry<K,V> getEntry(Object key) { if (size == 0) { return null; } int hash = (key == null) ? 0 : hash(key); // 确定数组下标,然后从头开始遍历链表,直到找到为止 for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } return null; }
对于数组的下标有其他疑问(hashmap 中hash函数h & (length-1)详解),可参考: