数据库实现分布式锁
基于数据库实现分布式锁
上面已经分析了基于数据库实现分布式锁的基本原理:通过唯一索引保持排他性,加锁时插入一条记录,解锁是删除这条记录。下面我们就简要实现一下基于数据库的分布式锁。
表设计
CREATE TABLE `distributed_lock` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`unique_mutex` varchar(255) NOT NULL COMMENT '业务防重id',
`holder_id` varchar(255) NOT NULL COMMENT '锁持有者id',
`create_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
UNIQUE KEY `mutex_index` (`unique_mutex`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
id字段是数据库的自增id,unique_mutex字段就是我们的防重id,也就是加锁的对象,此对象唯一。在这张表上我们加了一个唯一索引,保证unique_mutex唯一性。holder_id代表竞争到锁的持有者id。
加锁
insert into distributed_lock(unique_mutex, holder_id) values ('unique_mutex', 'holder_id');
如果当前sql执行成功代表加锁成功,如果抛出唯一索引异常(DuplicatedKeyException)则代表加锁失败,当前锁已经被其他竞争者获取。
解锁
delete from methodLock where unique_mutex='unique_mutex' and holder_id='holder_id';
解锁很简单,直接删除此条记录即可。
分析
是否可重入:就以上的方案来说,我们实现的分布式锁是不可重入的,即是是同一个竞争者,在获取锁后未释放锁之前再来加锁,一样会加锁失败,因此是不可重入的。解决不可重入问题也很简单:加锁时判断记录中是否存在unique_mutex的记录,如果存在且holder_id和当前竞争者id相同,则加锁成功。这样就可以解决不可重入问题。
锁释放时机:设想如果一个竞争者获取锁时候,进程挂了,此时distributed_lock表中的这条记录就会一直存在,其他竞争者无法加锁。为了解决这个问题,每次加锁之前我们先判断已经存在的记录的创建时间和当前系统时间之间的差是否已经超过超时时间,如果已经超过则先删除这条记录,再插入新的记录。另外在解锁时,必须是锁的持有者来解锁,其他竞争者无法解锁。这点可以通过holder_id字段来判定。
数据库单点问题:单个数据库容易产生单点问题:如果数据库挂了,我们的锁服务就挂了。对于这个问题,可以考虑实现数据库的高可用方案,例如MySQL的MHA高可用解决方案。
基于数据库的排他锁
可以通过数据库的排他锁来实现分布式锁。 基于MySql的InnoDB引擎,可以使用以下方法来实现加锁操作:
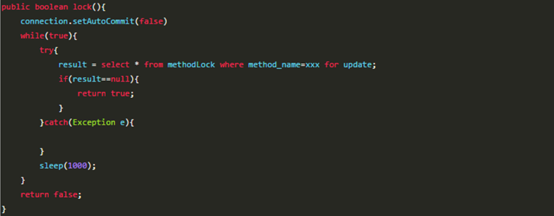
在查询语句后面增加for update,数据库会在查询过程中给数据库表增加排他锁(这里再多提一句,InnoDB引擎在加锁的时候,只有通过索引进行检索的时候才会使用行级锁,否则会使用表级锁。这里我们希望使用行级锁,就要给method_name添加索引,值得注意的是,这个索引一定要创建成唯一索引,否则会出现多个重载方法之间无法同时被访问的问题。重载方法的话建议把参数类型也加上。)。当某条记录被加上排他锁之后,其他线程无法再在该行记录上增加排他锁。
我们可以认为获得排它锁的线程即可获得分布式锁,当获取到锁之后,可以执行方法的业务逻辑,执行完方法之后,再通过以下方法解锁:

通过connection.commit()操作来释放锁。
这种方法可以有效的解决上面提到的无法释放锁和阻塞锁的问题。
- 阻塞锁? for update语句会在执行成功后立即返回,在执行失败时一直处于阻塞状态,直到成功。
- 锁定之后服务宕机,无法释放?使用这种方式,服务宕机之后数据库会自己把锁释放掉。
但是还是无法直接解决数据库单点和可重入问题。
参考: