久闻LevelDB大名,由于课程需要,借助此次机会对levelDB源码的几个主要模块进行解读,同时加强对c++的理解。
LevelDB简介
LevelDB是一个google开源的持久型K-V数据存储引擎,是一个很好的c++学习源码。LevelDB的主要特点在于其写性能十分优秀(在牺牲了部分读性能的前提下),这也是LSM-Tree的主要特性之一。
LevelDB的安装这里不再叙述,详见LevelDB安装.
安装完成之后,基本的打卡数据库,读写数据等操作官网上也很详细,详见LevelDB基本操作.
LevelDB主要组件
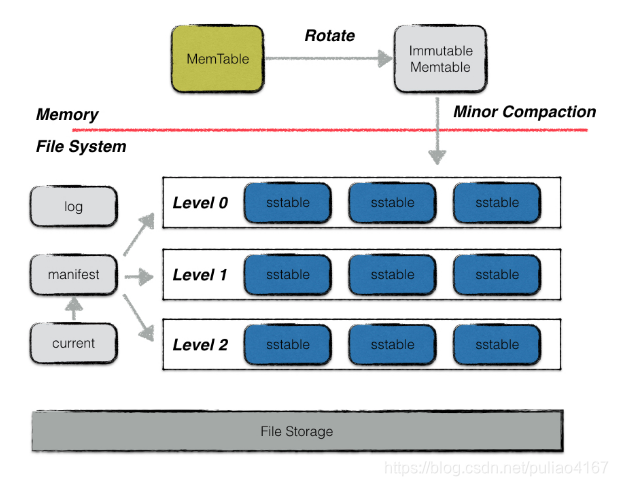
LevelDB的框架图如下所示。可以看出其主要分成六个部件:MemTable,Immutable Memtable,log,manifest,current,sstable。
- MemTable是内存中存储数据的第一个站点,在数据写入LevelDB中时,首先存储在内存MemTable数据结构中,其按照用户定义的顺序存储数据,同时将写入记录在log中,当MemTable大小超过一定量时,则将其变成Immutable Memtable,同时创建一个新的MemTable用于存储新的写入数据。
- Immutable Memtable 表示在内存中不可更改的数据,后台进程可以将其持久化到磁盘中的sstable
- log是日志文件,保证数据不易丢失,每当有写入操作的时候,就会先把操作写到log中,当数据还在内存中的时候断电,此时就可以根据日志文件恢复。
- manifest文件,每次有sstable增加或者减少(执行了Compaction操作)都会新增一个版本,这也也可以称为不同的level,manifest文件就是记录每次不同的版本变动。
- current文件用来记录当前的manifest文件名。
- sstable是磁盘中主要用来存储数据的,LevelDB会定期整合sstable,使得sstable在逻辑上分层,level 0表示内存中的数据直接映射到磁盘上,可能会存在数据交集,而level i层表示整合后的数据。
LevelDB中的数据结构
本节主要介绍两种LevelDB中的数据结构:跳表和LSM-Tree。
SkipList
跳表是一个基于有序链表的数据结构,其最大的优点在于可以实现插入和查找都是O(logn)时间复杂度,优于普通链表,同时其比平衡树实现简单,因此在Redis和LevelDB中都有应用。
结构以及查找过程
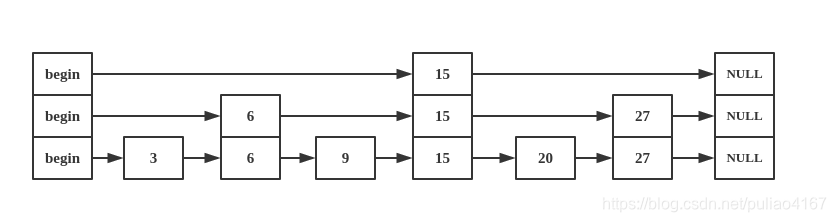
跳表的结构图如下所示,可以看到其本质上是一个有序链表,只不过其每个节点都有不同的高度,因此每个层次的节点也按序相连:
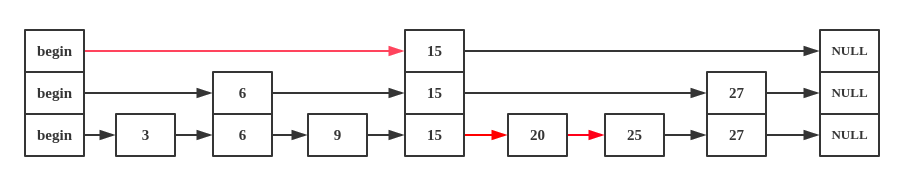
查找并插入节点25的过程图,图中红线代表查找路径,当其层数>1的时候,如果下一个节点的值比目标值大,则下降一层,当其层数=1时,则可以直接插入节点,由此可见,其查找过程中跳过了3,6,9的查找,因此具有O(logn)的时间复杂度。插入节点的高度是由一个随机值计算得出:
源码分析
LevelDB的源码位于db/skiplist.h。首先看看其节点的定义,Node包含了节点值key,取出和设置next指针的函数,next表示下一个节点的首地址,只有一个元素。
template <typename Key, class Comparator>
struct SkipList<Key, Comparator>::Node {
explicit Node(const Key& k) : key(k) {}
// 每个节点的值
Key const key;
Node* Next(int n) {
assert(n >= 0);
// 取出atomic的值
return next_[n].load(std::memory_order_acquire);
}
void SetNext(int n, Node* x) {
assert(n >= 0);
// 存储atomic的值
next_[n].store(x, std::memory_order_release);
}
// No-barrier variants that can be safely used in a few locations.
Node* NoBarrier_Next(int n) {
assert(n >= 0);
return next_[n].load(std::memory_order_relaxed);
}
void NoBarrier_SetNext(int n, Node* x) {
assert(n >= 0);
next_[n].store(x, std::memory_order_relaxed);
}
private:
// Array of length equal to the node height. next_[0] is lowest level link.
std::atomic<Node*> next_[1];
};
下面看SkipList的定义。首先看看成员变量,compare_用于表示节点之间的比较关系,arena_用于给跳表和节点申请内存,head_是头结点,max_height_整个跳表的最大高度,rnd_用于随机生成节点高度。除此之外,还有在SkipList类内有一个Iterator内置类。成员函数的作用可以由其名可知。
template <typename Key, class Comparator>
class SkipList {
private:
struct Node;
public:
// Create a new SkipList object that will use "cmp" for comparing keys,
// and will allocate memory using "*arena". Objects allocated in the arena
// must remain allocated for the lifetime of the skiplist object.
explicit SkipList(Comparator cmp, Arena* arena);
SkipList(const SkipList&) = delete;
SkipList& operator=(const SkipList&) = delete;
// Insert key into the list.
// REQUIRES: nothing that compares equal to key is currently in the list.
void Insert(const Key& key);
// Returns true iff an entry that compares equal to key is in the list.
bool Contains(const Key& key) const;
// Iteration over the contents of a skip list
class Iterator {
public:
// Initialize an iterator over the specified list.
// The returned iterator is not valid.
explicit Iterator(const SkipList* list);
// Returns true iff the iterator is positioned at a valid node.
bool Valid() const;
// Returns the key at the current position.
// REQUIRES: Valid()
const Key& key() const;
// Advances to the next position.
// REQUIRES: Valid()
void Next();
// Advances to the previous position.
// REQUIRES: Valid()
void Prev();
// Advance to the first entry with a key >= target
void Seek(const Key& target);
// Position at the first entry in list.
// Final state of iterator is Valid() iff list is not empty.
void SeekToFirst();
// Position at the last entry in list.
// Final state of iterator is Valid() iff list is not empty.
void SeekToLast();
private:
const SkipList* list_;
Node* node_;
// Intentionally copyable
};
private:
enum { kMaxHeight = 12 };
inline int GetMaxHeight() const {
return max_height_.load(std::memory_order_relaxed);
}
Node* NewNode(const Key& key, int height);
int RandomHeight();
bool Equal(const Key& a, const Key& b) const { return (compare_(a, b) == 0); }
// Return true if key is greater than the data stored in "n"
bool KeyIsAfterNode(const Key& key, Node* n) const;
// Return the earliest node that comes at or after key.
// Return nullptr if there is no such node.
//
// If prev is non-null, fills prev[level] with pointer to previous
// node at "level" for every level in [0..max_height_-1].
Node* FindGreaterOrEqual(const Key& key, Node** prev) const;
// Return the latest node with a key < key.
// Return head_ if there is no such node.
Node* FindLessThan(const Key& key) const;
// Return the last node in the list.
// Return head_ if list is empty.
Node* FindLast() const;
// Immutable after construction
Comparator const compare_;
Arena* const arena_; // Arena used for allocations of nodes
Node* const head_;
// Modified only by Insert(). Read racily by readers, but stale
// values are ok.
std::atomic<int> max_height_; // Height of the entire list
// Read/written only by Insert().
Random rnd_;
};
LSM-Tree
LSM-Tree(Log Structured-Merge Tree)是一个插入性能极佳的结构,传统的关系型数据库的数据库存储引擎(如mysql的Innodb)都是采用B+树的形式,而B+树的好处在于其是一个索引树,只有叶子节点存储数据,这样可以同时兼顾读写性能,同时查询性能更加稳定。而LSM-Tree的优势在于其能提高写操作的吞吐量,在一些写操作频率>读操作频率的场景十分有效。
LSM-Tree原理
首先要清楚一个道理:磁盘的随机读写慢,顺序读写快。这个其实很好理解,随机读写会将数据存放在不同的磁盘扇区中,这样数据的读写操作就会访问多个磁盘扇区,而顺序读写就会将数据尽量放在同一扇区下,这样使得数据量相同的情况下,顺序读写访问的磁盘扇区更少,因此速度更快。一个很好的方法就是将数据存储在文件中,文件中的数据都是有序的。
LSM-Tree的原理很容易理解,转子知乎:
将之前使用一个大的查找结构(造成随机读写,影响写性能),变换为将写操作顺序的保存到一些相似的有序文件(也就是sstable)中。所以每个文件包含短时间内的一些改动。因为文件是有序的,所以之后查找也会很快。文件是不可修改的,他们永远不会被更新,新的更新操作只会写到新的文件中。读操作检查最新的文件。通过周期性的合并这些文件来减少文件个数。
本质上LSM-Tree是利用了将对数据的操作保持在内存中,然后批量将这些操作flush到磁盘上,这样就牺牲了部分的读取性能,因此读取操作要先后去读内存中的最新数据MemTable,然后读取不可修改的内存数据Immutable MemTable,如果还是没有再去磁盘上读取sstable,这样读取性能就会降低很多,因此LevelDB中有设置页缓存机制(配合LRU)加快读取速度。
参考博客 :
- https://github.com/google/leveldb
- https://blog.csdn.net/ict2014/article/details/17394259
- https://leveldb-handbook.readthedocs.io/zh/latest/basic.html
- https://www.zhihu.com/question/19887265