MySQl基本命令行语句
mysql 语句规范:
- 关键字与函数名称全部大写
- 数据库名称, 表名称, 字段名称 全部小写
- SQL 语句 必须以分号结尾
注: 因为mysql 默认大小写是不敏感的, 所以下面的语句用小写也是不会有错的。 只是在我们创建数据库的过程中, 使用这个规范能让我们更好的区分;
-
mysql 登陆:
mysql -uusername -ppassword 注: username 是用户名 password 是密码注:-p后可以直接加上密码,就可以直接连接上,但在安全前提下,不建议这写

建议如上面图片上写法直接写mysql -uusername -p就会弹出Enter password : 这里输入的密码会隐藏
假如忘记了密码,则可以参考 MySQl 忘记密码怎么办? -
mysql退出 (三种方式):
quit exit \q
-
显示当前服务器版本
SELECT VERSION(); -
显示当前时间
SELECT NOW(); -
显示当前用户
SELECT USER(); -
查看数据库
SHOW DATABASES;MySQL 5.7版本 下默认会有4个数据库 information_schema、mysql、performance_schema、sys;
-
创建数据库
CREATE DATABASE 库名 CHARACTER SET utf8;注:后面的 CHARACTER SET utf8 也可以不写,也可以写为 ”CHARSET utf8 “ 但建议写上去,因为 MySQL 默认 不是 utf8 编码,所以不写这个插入中文字符会因为字符集不兼容报错;
这里可以参考 MySQL 插入中文报错

-
删除数据库
DROP DATABASE 库名; -
选择数据库
USE 库名
当如上图一般则选中成功 -
查看当前选择的数据库
SELECT DATABASE();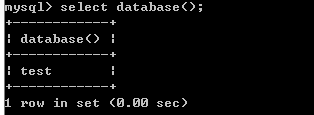
-
查看数据库中的表
SHOW TABLES;
一般新建的数据库初始为空表 -
创建表
CREATE TABLE 表名 ( 字段 数据类型 其他, ...... ) ENGINE=InnoDB DEFAULT CHARSET=utf8;CREATE TABLE user( id int(11) NOT NULL AUTO_INCREMENT, username varchar(16) DEFAULT NULL, password varchar(16) DEFAULT NULL, PRIMARY KEY (id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;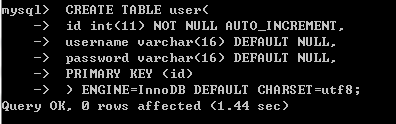
- auto_increment 表示自增长
- primary key 为主键约束
- default 为默认值约束
- engine 是指表存储引擎
- charset 表示默认字符集,与上述数据库创建相同,数据库内每张表都要建成charset utf8,才能保证每张表都不会插入中文报错,这里同样可以参考 MySQL 插入中文报错 当然这两个也都可以不写,不过需要去my.ini配置文件中更改默认字符集;
-
删除表
DROP TABLE 表名; -
查看表结构(2个方法)
DESC 表名;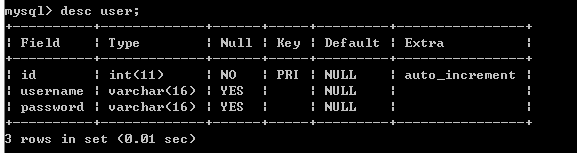
SHOW COLUMNS FROM 表名;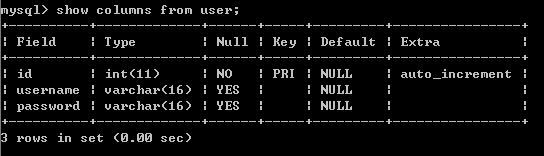
SELECT 查询:
-
基本语法:
SELECT 字段1,字段2, ... FROM 表1 [INNER | LEFT |RIGHT] JOIN 表2 ON 连接条件 WHERE 查询条件 GROUP BY 字段1 HAVING 分组条件 ORDER BY 字段1 [DESC|ASC] LIMIT [开始位置,] length; -
SELECT语句由以下列表中所述的几个子句组成:
- SELECT 之后是逗号分隔列 或 星号(*) 的列表,逗号分隔列表示要返回对应的列, ’ * ’ 则表示返回所有列。
- FROM 指定要查询数据的表或视图。
- JOIN 根据某些连接条件从其他表中获取数据。 连接分为:
- INNER JOIN(内连接)
- LEFT JOIN(左外连接)
- RIGHT JOIN (右外连接)
- CROSS JOIN(交叉连接)
- FULL JOIN (全连接,但是这个MySQl 没有直接实现, 可以用其他方法实现,具体可参考 MySQl 如何实现 FULL JOIN? )
- 自连接
- ON 后面跟上连接条件,这个只有表连接时才能用,当然这个可以用WHERE 来替换,
- WHERE 后跟上查询条件,过滤结果集中的行。
- GROUP BY 将一组行组合成小分组,并对每个小分组应用聚合函数。
聚合函数例如:COUNT(),SUM(),MAX(),MIN() … - HAVING 跟上分组条件,过滤基于 GROUP BY 子句定义的小分组。
- ORDER BY 指定用于排序的列的列表,DESC降序,ASC 升序(默认)。
- LIMIT 限制返回行的数量,[ ] 中的开始位置可以省略,省略的话就默认查询从最开始的前length行,否则查询从开始位置开始的length行。
注:这里开始位置的查询如数组下标一样,当开始位置为0时,则从数据第1行开始length行; - 注: 语句中的 SELECT 和 FROM 语句是必须的,其他部分是可选的。
例如:
-
不带条件的查询
SELECT * FROM 表名 ; -- 查询所有行,显示的结果为字段顺序SELECT 字段1,字段2 FROM 表名 ; -- 查询对应字段的行,顺序为所列顺序SELECT 聚合函数 FROM 表名 ;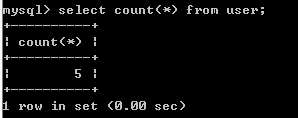
聚合函数:数名称 作用 COUNT() 返回某列的行数 SUM() 返回某列值的和 AVG() 返回某列的平均值 MAX() 返回某列的最大值 MIN() 返回某列的最小值 -
WHERE 基本用法
SELECT * FROM 表名 [WHERE 字段 = 'XXX'];-
’ * ’ 表示查询所有数据
-
[ ]内的where可以不写,不写就是查整张表的,写了就是查符合条件的那几行;
-
where 后跟一个条件, =‘ 也可以更换为其他的比较运算符,如: > ,< …
-
where 后可以跟上子查询,具体可以参考 MySQl 子查询
-
where 后 跟上 like 运算符
SELECT * FROM 表名 WHERE 字段名 LIKE '%XXX%' SELECT * FROM 表名 WHERE 字段名 LIKE '_XXX_',- % 作为通配符通配 多个
- _ 作为通配符通配 一个
- 如果不使用通配符,则 like 作用与 ’ = ’ 相同;
- 以及当我们字段中出现通配符,如何解决,可以参考MySQL like 如何查询包含’%'的字段 (ESCAPE用法)
-
where 带 IN 关键字的查询
IN关键字用于判断某个字段的值是否在指定集合中,若在,则该字段所在的记录将会被查询出来.SELECT * FROM 表名 WHERE 字段名 IN (元素1,元素2,…);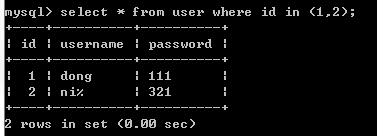
-
where 带 BETWEEN AND 关键字的查询
BETWEEN AND 用于判断某个字段的值是否在指定范围之内,若在,则该字段所在的记录会被查询出来,反之不会。SELECT * FROM 表名 WHERE 字段名 BETWEEN 值1 AND 值2;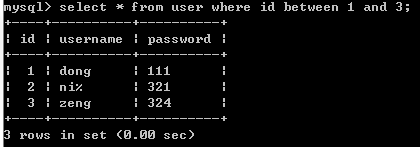
-
带 AND ,OR 关键字的多条件查询
SELECT * FROM 表名 WHERE 条件1 AND 条件 2;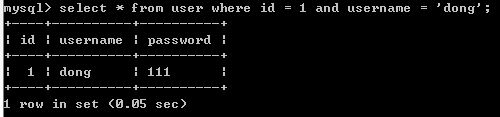
这里 AND, OR 可以交替使用,逻辑判断类似于C 语言的 && 与 ||;
-
-
JOIN 连接:
SELECT *FROM 表1 [INNER | LEFT | RIGHT] JOIN 表2 ON 连接条件以此来实现表之间的连接,具体可查询 MySQL 多表查询;
-
分组查询:
SELECT * FROM 表名 [WHERE 字段 = 'XXX'] [GROUP BY 字段名] [ HAVING 条件];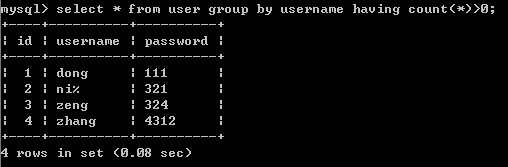
这里根据username 分组,分组条件为每组行数大于0由于数据没有username 重复的,所以每行数据为一组,从而全部都查询出来了; -
ORDER BY 排序:
SELECT * FROM 表名 [WHERE 字段 = 'XXX'] [GROUP BY 字段名] [ HAVING 条件] ORDER BY 字段名[DESC|ASC];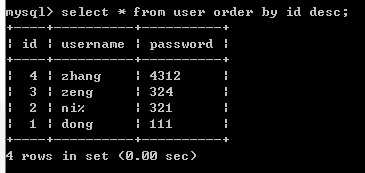
-
LIMIT 限制查询行
SELECT * FROM 表名 [WHERE 字段 = 'XXX'] [GROUP BY 字段名] [ HAVING 条件] ORDER BY 字段名[DESC|ASC] [LIMIT [开始位置,] length];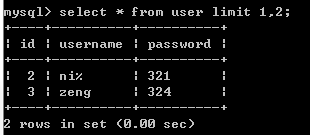
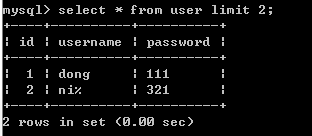
这里会发现默认从第一行开始查,给定开始位置,则从(开始位置+1)行开始查; -
插入数据
INSERT [INTO] 表名 (字段1, 字段2,...) VALUES ('XXX','XXX',...);- 这里 [ ] 的 INTO 可以省略;
- VALUES 可以写成 VALUE ,也就是不加S;
- 不写插入哪些字段的话,就默认values 后面要跟上表中全部字段的值;

这个时候在查询表中数据,就会有数据了
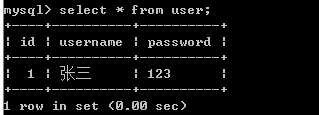
-
(删除)清空表中数据
DELETE FROM 表名;TRUNCATE TABLE 表名;

进行这两个操作中任意一个后,表会为空

上面两种都可以清空表, 但区别在于
delete 是像橡皮擦一样擦除表中数据,而truncate 则是 复制建表语句, 然后删除表,再以这个数据重新建一张新表,所以当删除表中全部数据时, truncate 效率会更高而 delete可以where 条件选择性的删除数据,会更灵活
DELETE FROM 表名 (WHERE 字段 = 'XXX') ;
-
更新表内容
UPDATE 表名 SET 字段1 = 'XXX' (WHERE 字段2 = 'XXX');
ALTER 修改数据表:
-
添加单列
ALTER TABLE tbl_name(表名) ADD [COLUMN] col_name(字段名) column_definition(字段定义) [FIRST|AFTER col_name];注:
- [ ]内可省略;
- 这里的[FIRST|AFTER col_name]是指增加列所处的位置,如果不写,则默认置于所有列之后;
- FIRST 指置于所有字段之前, AFTER col_name 则是指定位于哪个字段之后;
查询当前所有列:
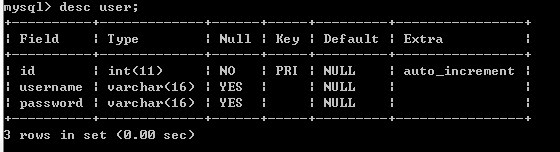
使用ALTER 增加一列ALTER TABLE user ADD name varchar(16) NOT NULL;
查询增加后所有列:
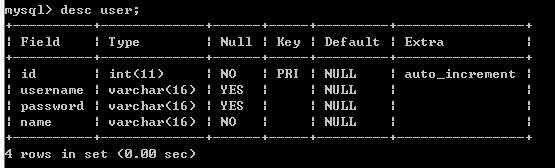
这里增加时不指定位置,就会默认放置在最后;
指定位置增加:ALTER TABLE user ADD name1 varchar(16) NOT NULL FIRST;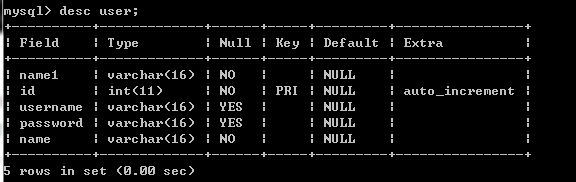
如图所示,指定 FIRST 则字段位于最前; -
添加多列
ALTER TABLE tbl_name(表名) ADD [COLUMN] (col_name1(字段1名) column1_definition(字段1定义) ,col_name2(字段2名) column2_definition(字段2定义) ,...);注:
- [ ]内可省略;
- 添加多个字段时,需用括号把每个字段扩起来;
- 添加多个字段时, 不能指定字段放置的位置,自动放置于最后;
-
删除列
ALTER TABLE tbl_name(表名) DROP [COLUMN] (col_name1(字段1名) ;l
-
添加主键约束 ( PRIMARY KEY ):
ALTER TABLE tbl_name ADD [CONSTRAINT 主键名] PRIMARY KEY [index_type](col_name); -
删除主键约束:
ALTER TABLE 表名 DROP PRIMARY KEY;注: 这里如果使用主键的字段使用了 auto_increment ,主键则不能直接删除;
-
添加唯一约束 ( UNIQUE KEY ):
ALTER TABLE tbl_name ADD [CONSTRAINT 索引名] UNIQUE [INDEXE|KEY] [index_type](col_name1,col_name2,...);注:唯一约束不止一个,所以这里可以同时增加几个;

-
删除唯一约束 :
方法与下面删除索引一样; -
添加外键约束 ( FOREIGN KEY ):
ALTER TABLE 子表名 ADD [CONSTRAINT 外键名] FOREIGN KEY(外键字段名) REFERENCES 父表名(参照字段名); -
删除外键键约束:
ALTER TABLE 表名 DROP FOREIGN KEY 外键名;
具体可参考 MySQl 外键约束
-
添加/删除默认约束
ALTER TABLE tbl_name ALTER col_name {SET DEFAULT 默认值|DROP DEFAULT}注:
- { }中表示为任选其一;
- SET DEFAULT 默认值 为设置默认值;
- DROP DEFAULT 为删除默认值;
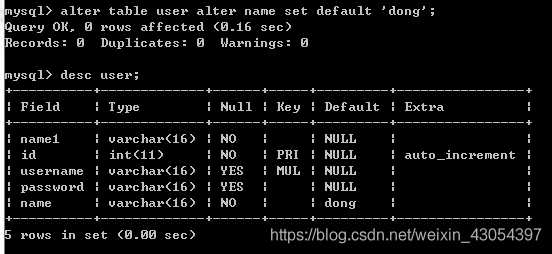
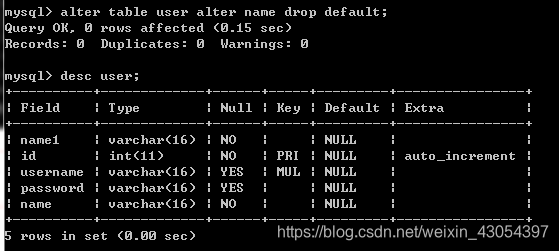
这里看name 行的 Default 的变化;
-
查看索引
SHOW INDEXES FROM 表名 [\G]; 注: 这里\G 表示以网格方式显示;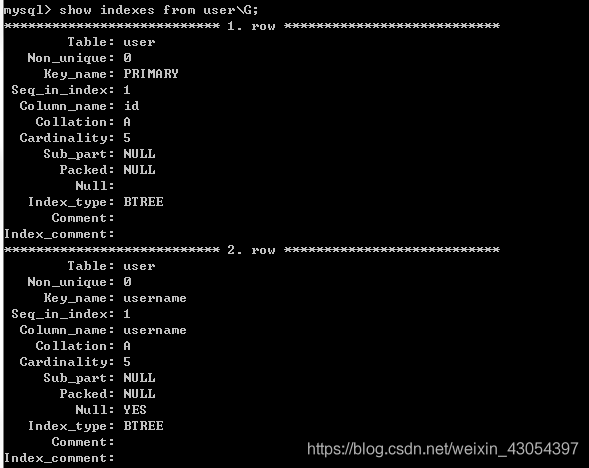
-
删除索引(或 unique key) (在这之前先通过上面的方法查看到index_name)
ALTER TABLE tbl_name DROP index index_name;
-
MODIFY修改
ALTER TABLE tbl_name MODIFY [COLUMN] col_name(字段名) column_definition(字段定义) [FIRST|AFTER col_name];这里的 [FIRST|AFTER col_name] 用法与作用和上述增加列一样;
注:使用MODIFY 不能改变字段的名字;也不能删除掉约束,但可以增加约束; -
CHANGE 修改
ALTER TABLE tbl_name CHANGE [COLUMN] old_col_name(旧字段名) new_col_name(新字段名) column_definition(字段定义) [FIRST|AFTER col_name];CHANGE 功能比较强大,它既可以改列名,也可以更改列定义;但也不能删除掉约束,但可以增加约束;
修改表名称:
方法一:
ALTER TABLE tbl_name RENAME [TO|AS] new_col_name;
方法二:
RENAME tbl_name [TO|AS] new_col_name [,tbl_name [TO|AS] new_col_name),...];
方法一 一次只能改一个表名称 方法二则可以同时改多个,只需用 ‘,’ 隔开;