本博客属作者原创,未经允许禁止转载,请尊重原创!如有问题请联系QQ509961766
(一)前言
上一篇主要讲了一些主从同步方面的一些配置,实现了数据同步,也分析了主从同步的优缺点。
redis主从模式解决了数据备份和单例可能存在的性能问题,但是其也引入了新的问题。由于主从模式配置了三个redis实例,并且每个实例都使用不同的ip(如果在不同的机器上)和端口号,根据前面所述,主从模式下可以将读写操作分配给不同的实例进行从而达到提高系统吞吐量的目的,但也正是因为这种方式造成了使用上的不便,因为每个客户端连接redis实例的时候都是指定了ip和端口号的,如果所连接的redis实例因为故障下线了,而主从模式也没有提供一定的手段通知客户端另外可连接的客户端地址,因而需要手动更改客户端配置重新连接。另外,主从模式下,如果主节点由于故障下线了,那么从节点因为没有主节点而同步中断,因而需要人工进行故障转移工作。
为了解决这两个问题,在2.8版本之后redis正式提供了sentinel(哨兵)架构。关于sentinel,这里需要说明几个概念:
| 名词 | 逻辑结构 | 物理结构 |
|---|---|---|
| 主节点 | redis主服务/数据库 | 一个独立的redis进程 |
| 从节点 | redis从服务/数据库 | 一个独立的redis进程 |
| sentine l 节点 | 监控redis数据节点 | 一个独立的sentinel进程 |
| sentine l 节点集合 | 若干sentinel节点的抽象集合 | 若干sentinel节点进程 |
| 应用方 | 泛指一个或多个客户端 | 一个或多个客户端线程或进程 |
(二)Redis-sentinel简介
-
Sentinel(哨兵)进程是用于监控redis集群中Master主服务器工作的状态,在Master主服务器发生故障的时候,可以实现Master和Slave服务器的切换,保证系统的高可用,其已经被集成在redis2.6+的版本中,Redis的哨兵模式到了2.8版本之后就稳定了下来。一般在生产环境也建议使用Redis的2.8版本的以后版本。哨兵(Sentinel) 是一个分布式系统,你可以在一个架构中运行多个哨兵(sentinel) 进程,这些进程使用流言协议(gossipprotocols)来接收关于Master主服务器是否下线的信息,并使用投票协议(Agreement Protocols)来决定是否执行自动故障迁移,以及选择哪个Slave作为新的Master。每个哨兵(Sentinel)进程会向其它哨兵(Sentinel)、Master、Slave定时发送消息,以确认对方是否”活”着,如果发现对方在指定配置时间(可配置的)内未得到回应,则暂时认为对方已掉线,也就是所谓的”主观认为宕机” ,英文名称:Subjective Down,简称SDOWN。有主观宕机,肯定就有客观宕机。当“哨兵群”中的多数Sentinel进程在对Master主服务器做出 SDOWN 的判断,并且通过 SENTINEL is-master-down-by-addr 命令互相交流之后,得出的Master Server下线判断,这种方式就是“客观宕机”,英文名称是:Objectively Down, 简称 ODOWN。通过一定的vote算法,从剩下的slave从服务器节点中,选一台提升为Master服务器节点,然后自动修改相关配置,并开启故障转移(failover)。
-
哨兵(sentinel) 虽然有一个单独的可执行文件 redis-sentinel ,但实际上它只是一个运行在特殊模式下的 Redis 服务器,你可以在启动一个普通 Redis 服务器时通过给定 --sentinel 选项来启动哨兵(sentinel),哨兵(sentinel) 的一些设计思路和zookeeper非常类似。
-
Sentinel集群之间会互相通信,沟通交流redis节点的状态,做出相应的判断并进行处理,这里的主观下线状态和客观下线状态是比较重要的状态,它们决定了是否进行故障转移,可以 通过订阅指定的频道信息,当服务器出现故障得时候通知管理员,客户端可以将 Sentinel 看作是一个只提供了订阅功能的 Redis 服务器,你不可以使用 PUBLISH 命令向这个服务器发送信息,但你可以用 SUBSCRIBE 命令或者 PSUBSCRIBE 命令, 通过订阅给定的频道来获取相应的事件提醒。一个频道能够接收和这个频道的名字相同的事件。 比如说, 名为 +sdown 的频道就可以接收所有实例进入主观下线(SDOWN)状态的事件。
(三)Sentinel(哨兵)进程的作用
-
监控(Monitoring): 哨兵(sentinel) 会不断地检查你的Master和Slave是否运作正常。
-
提醒(Notification):当被监控的某个Redis节点出现问题时, 哨兵(sentinel) 可以通过 API
向管理员或者其他应用程序发送通知。 -
自动故障迁移(Automatic failover):当一个Master不能正常工作时,哨兵(sentinel)
会开始一次自动故障迁移操作,它会将失效Master的其中一个Slave升级为新的Master,
并让失效Master的其他Slave改为复制新的Master;当客户端试图连接失效的Master时,集群也会向客户端返回新Master的地址,使得集群可以使用现在的Master替换失效Master。Master和Slave服务器切换后,Master的redis.conf、Slave的redis.conf和sentinel.conf的配置文件的内容都会发生相应的改变,即,Master主服务器的redis.conf配置文件中会多一行slaveof的配置,sentinel.conf的监控目标会随之调换。
(四)Sentinel(哨兵)进程的工作方式
-
每个Sentinel(哨兵)进程以每秒钟一次的频率向整个集群中的Master主服务器,Slave从服务器以及其他Sentinel(哨兵)进程发送一个 PING 命令。
-
如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被 Sentinel(哨兵)进程标记为主观下线(SDOWN)。
-
如果一个Master主服务器被标记为主观下线(SDOWN),则正在监视这个Master主服务器的所有 Sentinel(哨兵)进程要以每秒一次的频率确认Master主服务器的确进入了主观下线状态。
-
当有足够数量的 Sentinel(哨兵)进程(大于等于配置文件指定的值)在指定的时间范围内确认Master主服务器进入了主观下线状态(SDOWN), 则Master主服务器会被标记为客观下线(ODOWN)。
-
在一般情况下, 每个 Sentinel(哨兵)进程会以每 10 秒一次的频率向集群中的所有Master主服务器、Slave从服务器发送 INFO 命令。
-
当Master主服务器被 Sentinel(哨兵)进程标记为客观下线(ODOWN)时,Sentinel(哨兵)进程向下线的 Master主服务器的所有 Slave从服务器发送 INFO 命令的频率会从 10 秒一次改为每秒一次。
-
若没有足够数量的 Sentinel(哨兵)进程同意 Master主服务器下线, Master主服务器的客观下线状态就会被移除。若 Master主服务器重新向 Sentinel(哨兵)进程发送 PING 命令返回有效回复,Master主服务器的主观下线状态就会被移除。
(五)Sentinel(哨兵)搭建准备环境
Master主服务器配置信息: IP:192.168.1.246 Port:6379,OS:Windows
Slave从服务器的配置信息:IP:192.168.1.90 Port:6379,OS:Windows
Master,Slave2个服务器上安装哨兵进程(Sentinel)
注意:由于两个Redis服务器都是安装在Windows操作系统上,而且这两个Redis服务器会在Master主服务器发生故障的时候会进行切换,必须保证两个Redis服务器的端口号已经增加进了防火墙,或者把两个Windows操作系统的防火墙关闭,否则会提示Master-link-Status:down,没有连接上Master主服务器。解决办法有两个:第一个办法是关闭两个Windows操作系统的防火墙;第二个办法是把各个Redis服务的端口号增加到防火墙里面,允许通过该端口号进行通信。
(六)Redis-sentinel配置
主服务器(Master)配置:在redis安装目录下新建sentinel.conf文件,内容如下:
sentinel.conf详细配置说明请参考【】
# 当前Sentinel服务运行的端口
port 26379
# 哨兵监听的主服务器
sentinel monitor mymaster 192.168.1.246 6379 2
# 3s内mymaster无响应,则认为mymaster宕机了
sentinel down-after-milliseconds mymaster 3000
# 如果10秒后,mysater仍没启动过来,则启动failover
sentinel failover-timeout mymaster 10000
# 执行故障转移时, 最多有1个从服务器同时对新的主服务器进行同步
sentinel parallel-syncs mymaster 1
# 哨兵监听需要密码认证
sentinel auth-pass mymaster test@2017
# 线程守护
daemonize no
# 日志路径
logfile "D:/gateway/log/sentinel.log"
备服务器(Slave)配置和主服务器配置一样,参考上面的配置
然后在redis安装目录新建如下文件:
新建redis启动脚本:startRedisServer.bat
@echo off
redis-server.exe redis.windows.conf
@pause
新增Redis-Sentinel启动脚本:startRedisSentinel.bat
@echo off
redis-server.exe sentinel.conf --sentinel
@pause
新建Redis-Sentinel启动命令:startrRedisSentinel.cmd
@echo off
cd D:\gateway\Redis-3.2.100
startRedisServer.bat
(七)Redis-sentinel启动
依次启动主备服务器上以下文件,先主后备
- 点击startRedisServer.bat ,启动Redis服务
- 点击startRedisSentinel.cmd ,启动哨兵服务
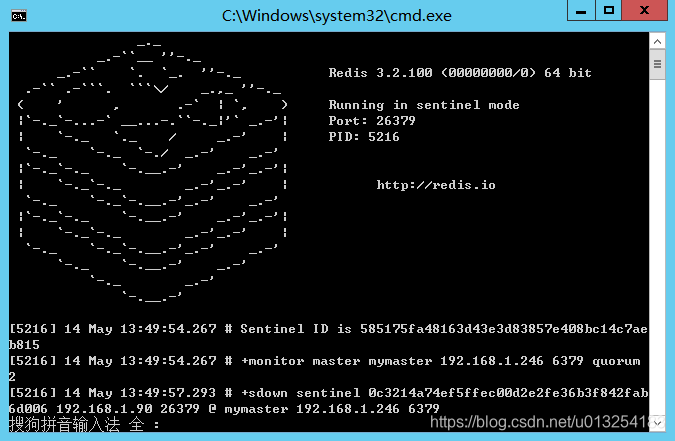
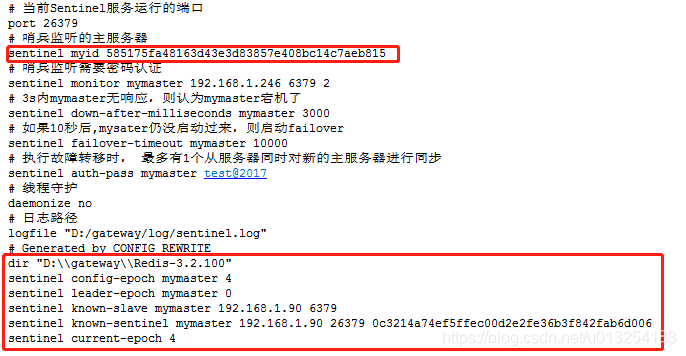
看看控制台和sentinel.conf中生成Sentinel ID,以及哨兵监听信息说明启动成功,主备生成的内容类似,这里只看主服务器的信息。
然后打开主服务器客户端(redis-cli.exe)输入命令:info replication
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=192.168.1.90,port=6379,state=online,offset=127,lag=0
master_repl_offset:127
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:126
从信息可以看到角色role是master,有1个从服务在线等等信息
然后打开备服务器客户端(redis-cli.exe)输入命令:info replication
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:192.168.1.246
master_port:6379
master_link_status:up
master_last_io_seconds_ago:0
master_sync_in_progress:0
slave_repl_offset:113
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6379>
从上面的信息可以看到角色role是slave,主服务器信息等数据,到此哨兵机制的配置全部完成,下面我们来模拟一下高可用场景,例如主服务器宕机,重启等等,看看哨兵机制是如何工作的
(八)高可用场景演示-主服务器master宕机
当主服务器master宕机,那么Sentinel会通过选举(算法)机制,从Salve中选出一个作为新Master。
大概原理是当选出一个Slave要作为Master的时候,会发送命令slaveofno one来取消选中的这个slave,使其成为Master。哨兵会发送给其他从服务器Slave配置选中的这个为新主服务器Master,并删除监听列表中出现故障的Master服务器。
进入主服务器客户端(redis-cli.exe)关闭redis服务
127.0.0.1:6379> shutdown
not connected>
在备用服务器查看sentinel控制台打印如下信息:
[3724] 23 Oct 16:01:35.347 # Sentinel ID is 0c3214a74ef5ffec00d2e2fe36b3f842fab6d006
[3724] 23 Oct 16:01:35.347 # +monitor master mymaster 192.168.1.246 6379 quorum 2
[3724] 23 Oct 16:01:38.381 # +sdown sentinel 585175fa48163d43e3d83857e408bc14c7aeb815 192.168.1.246 26379 @ mymaster 192.168.1.246 6379
[3724] 23 Oct 16:31:05.961 # +sdown master mymaster 192.168.1.246 6379
[3724] 23 Oct 16:31:06.033 # +odown master mymaster 192.168.1.246 6379 #quorum 2/2
[3724] 23 Oct 16:31:06.033 # +new-epoch 1
[3724] 23 Oct 16:31:06.034 # +try-failover master mymaster 192.168.1.246 6379
[3724] 23 Oct 16:31:06.036 # +vote-for-leader 0c3214a74ef5ffec00d2e2fe36b3f842fab6d006 1
[3724] 23 Oct 16:31:06.037 # 0c3214a74ef5ffec00d2e2fe36b3f842fab6d006 voted for 0c3214a74ef5ffec00d2e2fe36b3f842fab6d006 1
[3724] 23 Oct 16:31:06.095 # +elected-leader master mymaster 192.168.1.246 6379
[3724] 23 Oct 16:31:06.095 # +failover-state-select-slave master mymaster 192.168.1.246 6379
[3724] 23 Oct 16:31:06.167 # +selected-slave slave 192.168.1.90:6379 192.168.1.90 6379 @ mymaster 192.168.1.246 6379
[3724] 23 Oct 16:31:06.167 * +failover-state-send-slaveof-noone slave 192.168.1.90:6379 192.168.1.90 6379 @ mymaster 192.168.1.246 6379
[3724] 23 Oct 16:31:06.269 * +failover-state-wait-promotion slave 192.168.1.90:6379 192.168.1.90 6379 @ mymaster 192.168.1.246 6379
[3724] 23 Oct 16:31:07.046 # +promoted-slave slave 192.168.1.90:6379 192.168.1.90 6379 @ mymaster 192.168.1.246 6379
[3724] 23 Oct 16:31:07.047 # +failover-state-reconf-slaves master mymaster 192.168.1.246 6379
[3724] 23 Oct 16:31:07.121 # +failover-end master mymaster 192.168.1.246 6379
[3724] 23 Oct 16:31:07.121 # +switch-master mymaster 192.168.1.246 6379 192.168.1.90 6379
[3724] 23 Oct 16:31:07.123 * +slave slave 192.168.1.246:6379 192.168.1.246 6379 @ mymaster 192.168.1.90 6379
[3724] 23 Oct 16:31:10.154 # +sdown slave 192.168.1.246:6379 192.168.1.246 6379 @ mymaster 192.168.1.90 6379
当哨兵监听到主服务器宕机,就开始投票 =>选举=>切换主备,故障转移:
vote:投票
failover:故障转移
quorum:参与投票的法定人数
selected:选举
switch:切换
从这些信息就能简单的了解当主服务宕机之后,哨兵sentinel是如何实现主备切换的
我们再来看看备用Redis已经切换成master了,如下图,role已经切换为master了
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6379>
(九)高可用场景演示-宕机的master重新启动
刚刚我们演示的主服务器master宕机的场景,备用服务器已经切换为主服务器了,那么我们现在把之前宕机的主服务器master重新启动会有什么变化呢?
- 启动主服务器redis服务,运行startRedisServer.bat
- 进入客户端(redis-cli.exe)输入命令:info replication
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:192.168.1.90
master_port:6379
master_link_status:down
master_last_io_seconds_ago:-1
master_sync_in_progress:0
slave_repl_offset:1
master_link_down_since_seconds:jd
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6379>
从打印的信息可以看到之前宕机的主服务器重启之后的角色变成的了slave,也就是说之前的备用服务器现在成为了主服务器,我们去看看192.168.1.90这台服务器,现在已经变成master了,而192.168.1.246已经变成它的从服务器了。
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=192.168.1.246,port=6379,state=online,offset=10199,lag=0
master_repl_offset:10199
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:10198
127.0.0.1:6379>
(十)高可用场景演示-关闭192.168.1.90主服务器
我们再次关闭192.168.1.90主服务器的Redis,此时192.168.1.246又变回master了,然后重启192.168.1.90的Redis,这个时候192.168.1.90的Redis又变回slave了,打印信息这里就不列出来,跟上面的类似
(十一)主观下线和客观下线
主观下线(Subjectively Down, 简称 SDOWN)指的是单个 Sentinel 实例对服务器做出的下线判断。
客观下线(Objectively Down, 简称 ODOWN)指的是多个 Sentinel 实例在对同一个服务器做出 SDOWN 判断,并且通过 SENTINEL is-master-down-by-addr 命令互相交流之后,得出的服务器下线判断。(一个 Sentinel 可以通过向另一个 Sentinel 发送 SENTINEL is-master-down-by-addr 命令来询问对方是否认为给定的服务器已下线。)
如果一个服务器没有在 master-down-after-milliseconds 选项所指定的时间内,对向它发送 PING 命令的 Sentinel(哨兵)进程返回一个有效回复(valid reply),那么 Sentinel(哨兵)进程就会将这个服务器标记为主观下线。
服务器对 PING 命令的有效回复可以是以下三种回复的其中一种:
1、返回 +PONG 。
2、返回 -LOADING 错误。
3、返回 -MASTERDOWN 错误。
如果服务器返回除以上三种回复之外的其他回复,又或者在指定时间内没有回复 PING 命令,那么 Sentinel(哨兵)进程认为服务器返回的回复无效(non-valid)。
如果一个服务器在 master-down-after-milliseconds 毫秒内,一直返回无效回复才会被 Sentinel 标记为主观下线。
举个例子,如果 master-down-after-milliseconds 选项的值为 30000 毫秒(30 秒),那么只要服务器能在每 29 秒之内返回至少一次有效回复, 这个服务器就仍然会被认为是处于正常状态的。
从“主观下线”状态切换到“客观下线”状态并没有使用严格的法定人数算法(strong quorum algorithm),而是使用了流言协议,该协议解释为:如果 Sentinel(哨兵)进程在给定的时间范围内,从其他 Sentinel(哨兵)进程那里接收到了足够数量的主服务器下线报告, 那么 Sentinel(哨兵)进程就会将主服务器的状态从“主观下线”改变为“客观下线”。如果之后其他 Sentinel(哨兵)进程不再报告主服务器已下线,那么“客观下线”状态就会被移除。
“客观下线”条件只适用于主服务器:对于任何其他类型的 Redis 实例, Sentinel(哨兵)进程在将它们判断为下线前不需要进行协商,所以Slave从服务器或者其他 Sentinel(哨兵)进程永远不会达到“客观下线”条件。
只要有一个 Sentinel(哨兵)进程发现某个主服务器进入了“客观下线”状态,这个 Sentinel(哨兵)进程就可能会被其他 Sentinel(哨兵)进程推选出,并对失效的主服务器执行自动故障迁移操作。
(十二)哨兵模式的优缺点
优点:
1、哨兵集群模式是基于主从模式的,所有主从的优点,哨兵模式同样具有。
2、主从可以切换,故障可以转移,系统可用性更好。
3、哨兵模式是主从模式的升级,系统更健壮,可用性更高。
缺点:
1、Redis较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。为避免这一问题,运维人员在系统上线时必须确保有足够的空间,这对资源造成了很大的浪费。
(十三)总结
今天就写到这里了,Redis的哨兵模式是以主从模式为基础的,所以说,主从模式拥有的一些缺点,在哨兵模式下也具有。哨兵模式主要是监控Master主服务器的运行情况,当然也会监控Slave从服务器的运行情况,如果Master主服务器发生了故障,该模式可以保证Slave从服务器顺利升级为Master主服务器继续提供服务,以此提高系统的高可用性。虽然哨兵模式比主从模式提高了不少系统的高可用性,但是该模式不能水平扩容,不能动态的增、删节点,这也是限制哨兵模式广泛应用的主要原因。Redis也看到了这个情况,所在在Redis的3.x以后的版本提供了一个更加强大集群模式,那就是Cluster集群模式,后续后有时间作者会花时间去研究一下Cluster集群模式。
参考博文
Redis高可用集群-哨兵模式(Redis-Sentinel)
redis单例、主从模式、sentinel以及集群的配置方式及优缺点对比)
Redis进阶实践之十 Redis哨兵集群模式)