ElasticSearch是一个基于Lucene的全文搜索引擎。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。
一、安装
1. 安装es(端口9200)
https://www.elastic.co/cn/downloads/elasticsearch
下载后解压,运行bin/elasticsearch.bat即可。
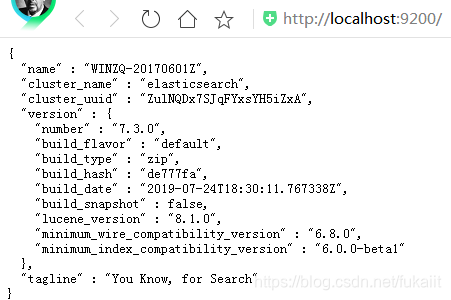
正常启动后访问 http://localhost:9200/ ,返回es基本信息(包含当前节点、集群、版本等信息),则表明已可正常使用。
如果需要远程访问,可以修改 Elastic 安装目录的config/elasticsearch.yml文件,去掉network.host的注释,将它的值改成0.0.0.0(允许任何人访问),然后重新启动 Elastic。

2. 安装es查询工具(kibana或elasticsearch-head)
(1)安装kibana(端口5601)
https://www.elastic.co/cn/downloads/kibana
注意kibana必须下载与es相匹配(相同)的版本
下载后解压,运行bin/kibana.bat即可。
访问 http://localhost:5601/
说明:
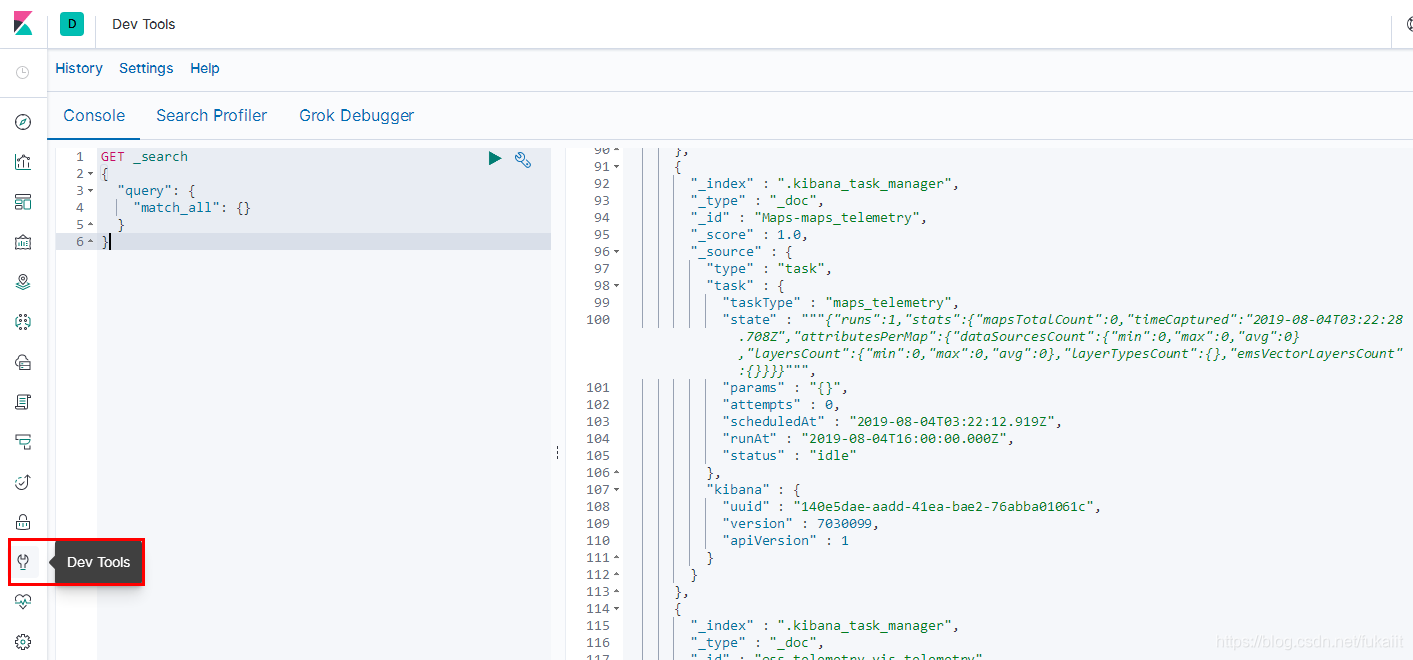
- 在Dev Tools中进行数据处理脚本编写
- 可直接粘贴curl脚本,该工具会自动转换
- 在config/kibana.yml文件中进行配置
配置server.host: "localhost"和server.host为要访问es库地址
(2)安装elasticsearch-head(端口9100)
https://github.com/mobz/elasticsearch-head
- 新建一个文件夹,在其下Git Bash Here
git clone git://github.com/mobz/elasticsearch-head.gitcd elasticsearch-headnpm installnpm run start- open http://localhost:9100/
访问的时候F12可以看到无法连接es库,有一个跨域的错误。
解决办法:在es配置中设置允许跨域:
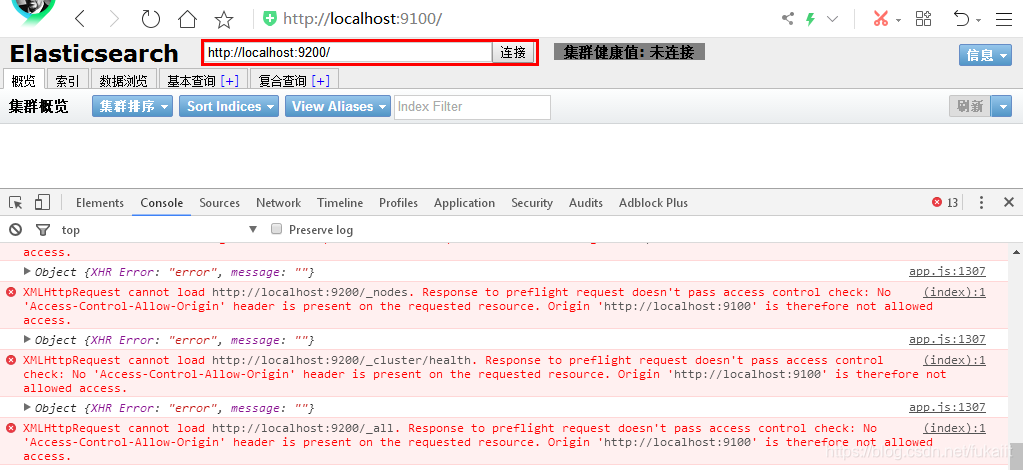
http.cors.enabled: true
http.cors.allow-origin: "*"
二、基本概念
- node:节点,单个es实例
- cluster:集群,由多个es实例构成
- index:索引,相当于数据库
- Document:文档,相当于数据库中单条的记录,多条文档构成index
为json格式,统一文档中的document不要求有相同的结构scheme,最好相同。 - Type:可用于分组
Elastic 6.x 版只允许每个 Index 包含一个 Type,7.x 版移除了 Type。
三、增删改查
1. 查看当前节点的所有index
GET /_cat/indices?v
2. 列出每个index包含的type
GET /_mapping
3. 列出index的字段信息(字段类型等)
GET /userinfo/_mapping
4. 新建index
新建一个叫weather的index
PUT /weather
返回的"acknowledged" : true,表示操作成功
5. 删除index
DELETE /weather
6. 新增记录(PUT)
PUT /accounts/_doc/2
{
"user": "张三",
"title": "工程师",
"desc": "数据库管理"
}
accounts是index,_doc位置在7版本之前是可以写任意Type,本例在7版本中, 写_doc,后面2是id,任意字符串都可
返回 “result” : “created”,可见创建成功
7. 新增记录(POST)
不指定id,自动生产一个id,用POST新增
POST /accounts/_doc
{
"user": "李四",
"title": "工程师",
"desc": "系统管理"
}
8. 查看记录
GET /accounts/_doc/2
如果id不正确,返回"found" : false
9. 删除记录
DELETE /accounts/_doc/1
“result” : “deleted”,
10. 更新记录
和新增记录命令相同,用put命令覆盖掉数据
PUT /accounts/_doc/2
{
"user" : "张三",
"title" : "工程师",
"desc" : "数据库管理,软件开发"
}
“result” : “updated”,
11. 查询所有记录
GET /accounts/_search
- took:耗时
- hits:命中的记录
- total:返回的记录数
- max_score:最高的匹配程度
- hits:返回的记录数组,默认按匹配程度(score)降序排列
12. match查询
查询desc字段有“软件”的记录
GET /accounts/_search
{
"query": {
"match": {
"desc": "软件"
}
},
"size":100,
"from": 0
}
size:设置返回记录长度
from:设置位移
结合可实现分页查询
13. 多条件match查询
or查询
GET /accounts/_search
{
"query": {
"match": {
"desc": "软件 系统"
}
}
}
and查询
GET /accounts/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"desc": "软件"
}
},
{
"match": {
"desc": "系统"
}
}
]
}
}
}
插入一些稍微内容丰富点的数据,进行后续学习:
| name | gender | birthday | address |
|---|---|---|---|
| jerry | male | 1562544488000 | 北京市三里屯100号 |
| tom | female | 1562371688000 | 北京市三里屯101号 |
| jack | male | 1562112488000 | 北京市三里屯102号 |
| tony | male | 1562371688000 | 北京市三里屯103号 |
| pony | female | 1564013288000 | 北京市三里屯104号 |
| cameral | female | 1563581288000 | 北京市三里屯105号 |
| tacker | male | 1564531688000 | 北京市三里屯106号 |
| luck | female | 1564013288000 | 北京市三里屯107号 |
| manny | male | 1563581288000 | 北京市三里屯108号 |
POST /userinfo/_doc
{
"name": "jerry",
"gender": "male",
"birthday": 1562544488000,
"address": "北京市三里屯100号"
}
14. update_by_query操作
修改tom和jerry的address信息
GET /userinfo/_update_by_query
{
"query": {
"bool": {
"filter": {
"terms": {
"name": [
"jerry",
"tom"
]
}
}
}
},
"script": {
"source": "ctx._source.address='上海市中山中路88号'"
}
}
15. 聚合
GET /userinfo/_search
{
"size": 0,
"aggs": {
"aggs_by_gender": {
"terms": {
"field": "gender.keyword"
}
}
}
}
在低版本中可以通过无条件聚合后下级再聚合,实现一个单纯的分组效果,类似如下:
(在高版本中测试会报空语句错误,无法查询)
GET /userinfo/_search
{
"size": 0,
"aggs": {
"aggs_group": {
"filter": {},
"aggs": {
"aggs_by_gender": {
"terms": {
"field": "gender.keyword",
"size": 10
}
}
}
}
}
}
16. 时间聚合
GET /userinfo/_search
{
"size": 0,
"aggs": {
"group_by_birthday": {
"date_histogram": {
"field": "birthday",
"calendar_interval": "day"
}
}
}
}
- year(1y)年
- quarter(1q)季度
- month(1M)月份
- week(1w)星期
- day(1d)天
- hour(1h)小时
- minute(1m)分钟
- second(1s)秒
还可以设置一些诸如时区、填充0的范围等属性,各版本默认效果有所不同(https://blog.csdn.net/qq_28988969/article/details/81565765)
// es提供的时间处理函数
"date_histogram": {
// 需要聚合分组的字段名称, 类型需要为date, 格式没有要求
"field": "@timestamp",
// 按什么时间段聚合, 这里是5分钟, 可用的interval在上面给出
"interval": "5m",
// 设置时区, 这样就相当于东八区的时间
"time_zone": "+08:00",
// 返回值格式化,HH大写,不然不能区分上午、下午
"format": "yyyy-MM-dd HH",
// 为空的话则填充0
"min_doc_count": 0,
// 需要填充0的范围
"extended_bounds": {
"min": 1533556800000,
"max": 1533806520000
}
}
也可以使用类似如下的script进行聚合,要求聚合字段为时间类型
"aggs": {
"hour": {
"terms": {
"script": {
"lang": "painless",
"source": "doc['orderTime'].date.hourOfDay"
}
}
}
}
17. 查询两个字段相同的记录
实现类似select * from table where a=b的效果
{
"query":
{
"bool":
{
"filter":
{
"script":
{
"script":
{
"inline": "doc['category_code'].value - doc['user_group_id'].value == 531",
"lang": "painless"
},
"boost": 1
}
}
}
}
}
references: