回顾上篇文章:
RDD:
是什么
五大特性对应五大方法
创建方式:3
操作:2 action & transformation
Spark作业开发流程:
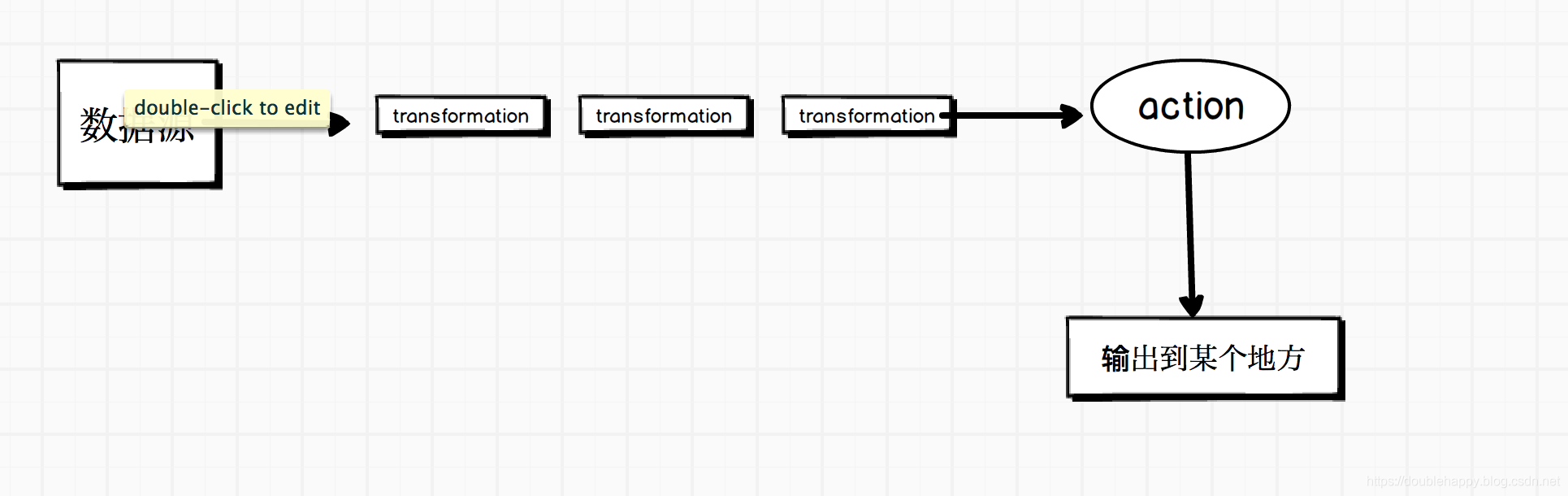
也就是:
数据源–>经过一堆transformtion–>action 触发spark作业 —>输出到某个地方
你的业务无论多么复杂 都是这样的。
Action
(1)collect
/**
* Return an array that contains all of the elements in this RDD.
*
* @note This method should only be used if the resulting array is expected to be small, as
* all the data is loaded into the driver's memory.
*/
def collect(): Array[T] = withScope {
val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)
Array.concat(results: _*)
}
注意:
1.Return an array that contains all of the elements in this RDD.
2.resulting array is expected to be small
3. the data is loaded into the driver's memory.
所以生产上你想看这个rdd里的数据 是不太现实的 会导致某种oom的,(oom有好多种的)
如果你还是想看rdd里的元素 该怎么办呢?
两种方法:
1) 取出部分数据
2) 把rdd输出到文件系统
真正生产上使用collect只有一个地方:???
scala> val rdd = sc.parallelize(List(1,2,3,4,5))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> rdd.collect()
res0: Array[Int] = Array(1, 2, 3, 4, 5)
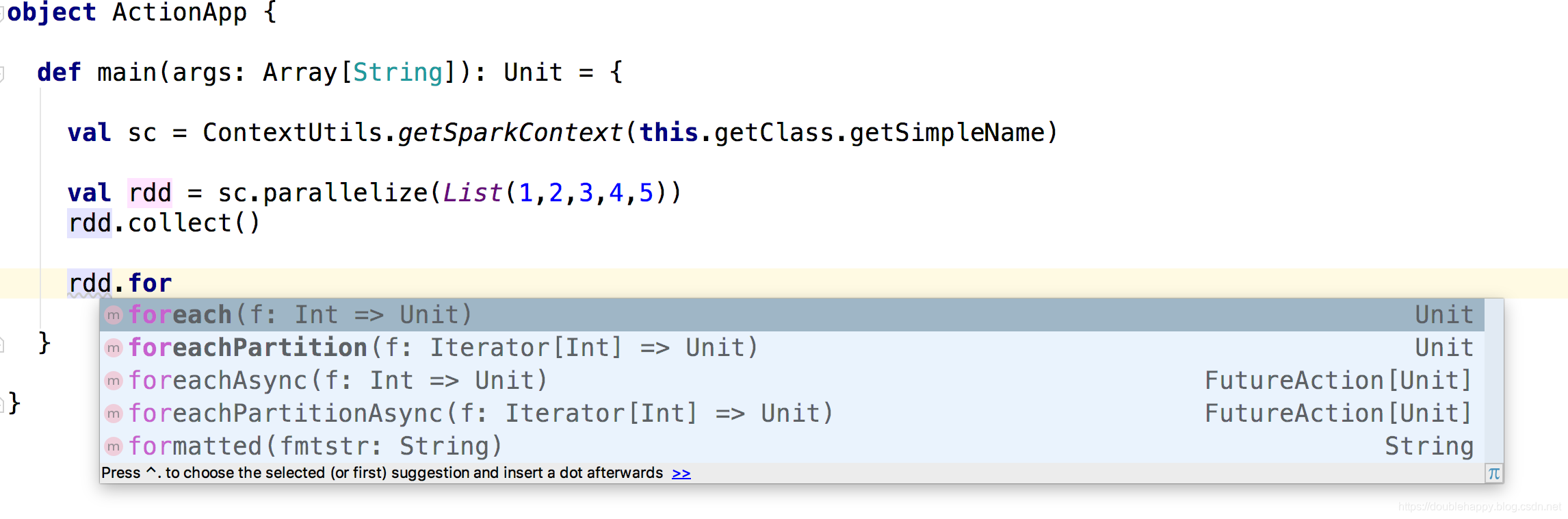
(2)foreach
/**
* Applies a function f to all elements of this RDD.
*/
def foreach(f: T => Unit): Unit = withScope {
val cleanF = sc.clean(f)
sc.runJob(this, (iter: Iterator[T]) => iter.foreach(cleanF))
}
scala> val rdd = sc.parallelize(List(1,2,3,4,5))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> rdd.foreach(println)
1
2
3
4
5
scala>
注意:
我在spark-shell --master local[2] 模式下 rdd.foreach(println) 会显示出结果,如果在
spark-shell --master yarn 模式下 rdd.foreach(println) 会显示出结果么?为什么呢?
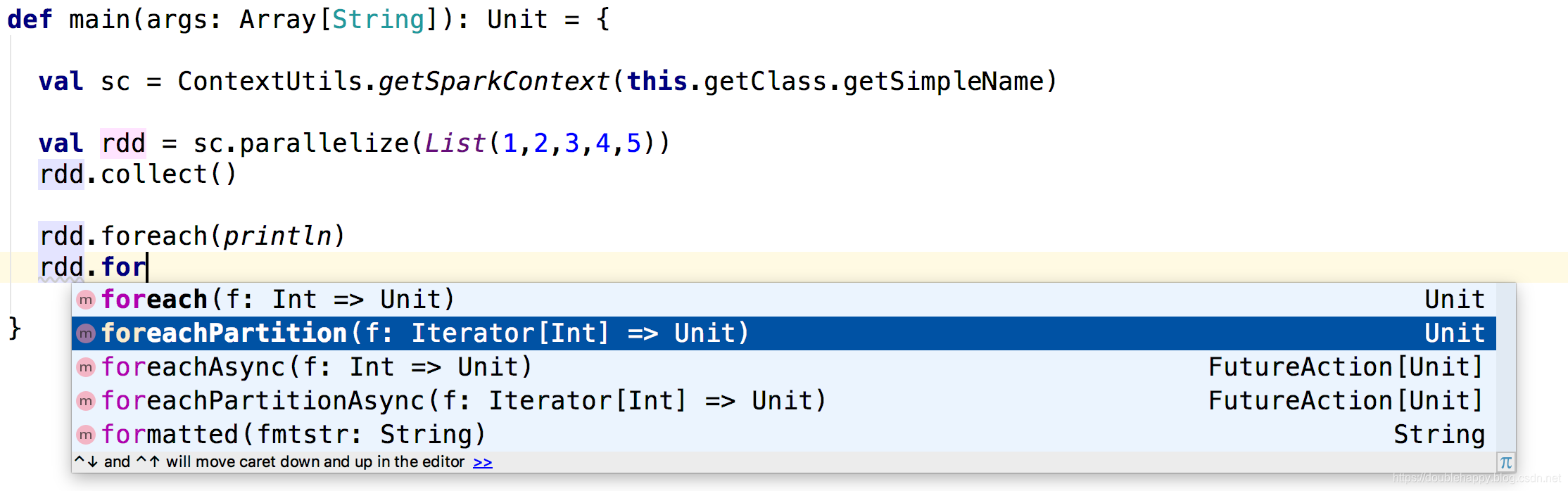
(3)foreachPartition
/**
* Applies a function f to each partition of this RDD.
*/
def foreachPartition(f: Iterator[T] => Unit): Unit = withScope {
val cleanF = sc.clean(f)
sc.runJob(this, (iter: Iterator[T]) => cleanF(iter))
}
scala> val rdd = sc.parallelize(List(1,2,3,4,5))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at parallelize at <console>:24
scala> rdd.foreachPartition(println)
non-empty iterator
non-empty iterator
scala> rdd.partitions.size
res5: Int = 2
scala>
注意:
返回的是non-empty iterator 怎么才能把里面的内容输出出来呢?
如果这样写呢?
rdd.foreachPartition(paritition => paritition.map(println))
scala> val rdd = sc.parallelize(List(1,2,3,4,5))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at parallelize at <console>:24
scala> rdd.foreachPartition(paritition => paritition.map(println))
scala>
能不能想到这是什么问题导致的?
foreachPartition(paritition => paritition.map(println)) 输出结果在正在执行的机器上面是有的
而控制台看到的是driver的
正好引入一个东西:
sortBy 上次的
val rdd2 = sc.parallelize(List(("a",1),("b",2),("c",3),("d",4)),2)
rdd2.sortBy(_._2,false)
注意:
sortBy是全局排序的还是分区排序的?
上面的两行代码看仔细了 , 是两个分区 ,按照降序排
结果:
scala> val rdd2 = sc.parallelize(List(("a",1),("b",2),("c",3),("d",4)),2)
rdd2: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[14] at parallelize at <console>:24
scala> rdd2.sortBy(_._2,false).foreach(println)
(d,4)
(c,3)
(b,2)
(a,1)
scala>
同样的代码我再运行一次:
scala> val rdd2 = sc.parallelize(List(("a",1),("b",2),("c",3),("d",4)),2)
rdd2: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[12] at parallelize at <console>:24
scala> rdd2.sortBy(_._2,false).foreach(println)
(b,2)
(a,1)
(d,4)
(c,3)
scala>
sortBy是全局排序的还是分区排序的?通过上面的测试知道了吗? 知道个鬼
是不是感觉是分区排序

去idea上输出结果看一下:
package com.ruozedata.spark.spark02
import com.ruozedata.spark.homework.utils.ContextUtils
object ActionApp {
def main(args: Array[String]): Unit = {
val sc = ContextUtils.getSparkContext(this.getClass.getSimpleName)
val rdd2 = sc.parallelize(List(("a",1),("b",2),("c",3),("d",4)),2)
rdd2.sortBy(_._2,false).saveAsTextFile("file:///Users/double_happy/zz/G7-03/工程/scala-spark/doc/out")
sc.stop()
}
}
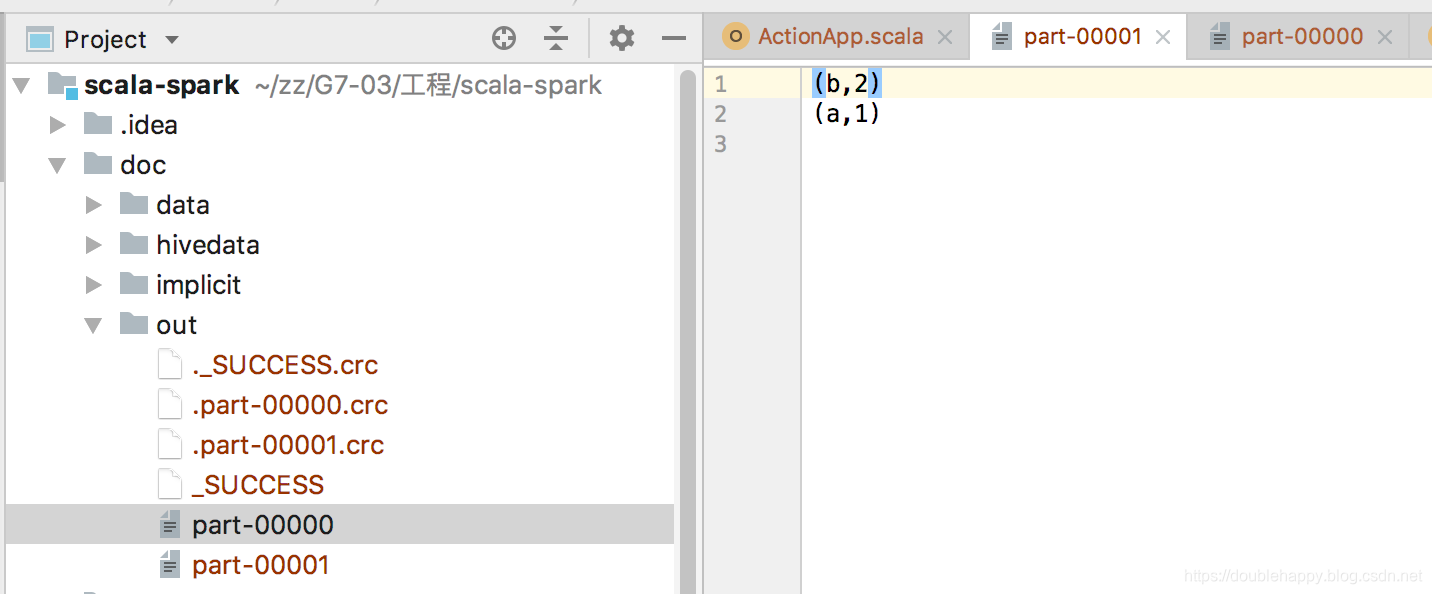
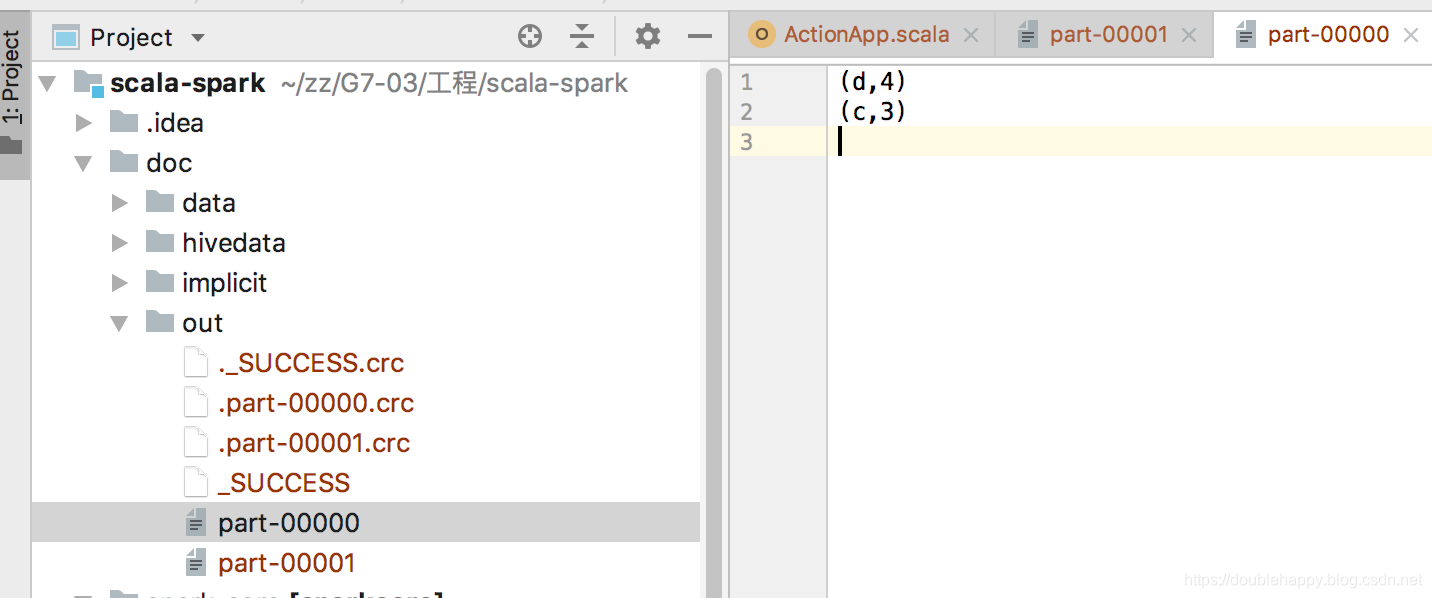
难道真的是分区排序么?在进行测试。
scala> rdd2.sortBy(_._2,false).foreach(println)
(b,2)
(a,1)
(d,4)
(c,3)
scala> rdd2.sortBy(_._2,false).foreach(println)
(d,4)
(c,3)
(b,2)
(a,1)
scala> rdd2.sortBy(_._2,false).foreach(println)
(d,4)
(c,3)
(b,2)
(a,1)
scala>
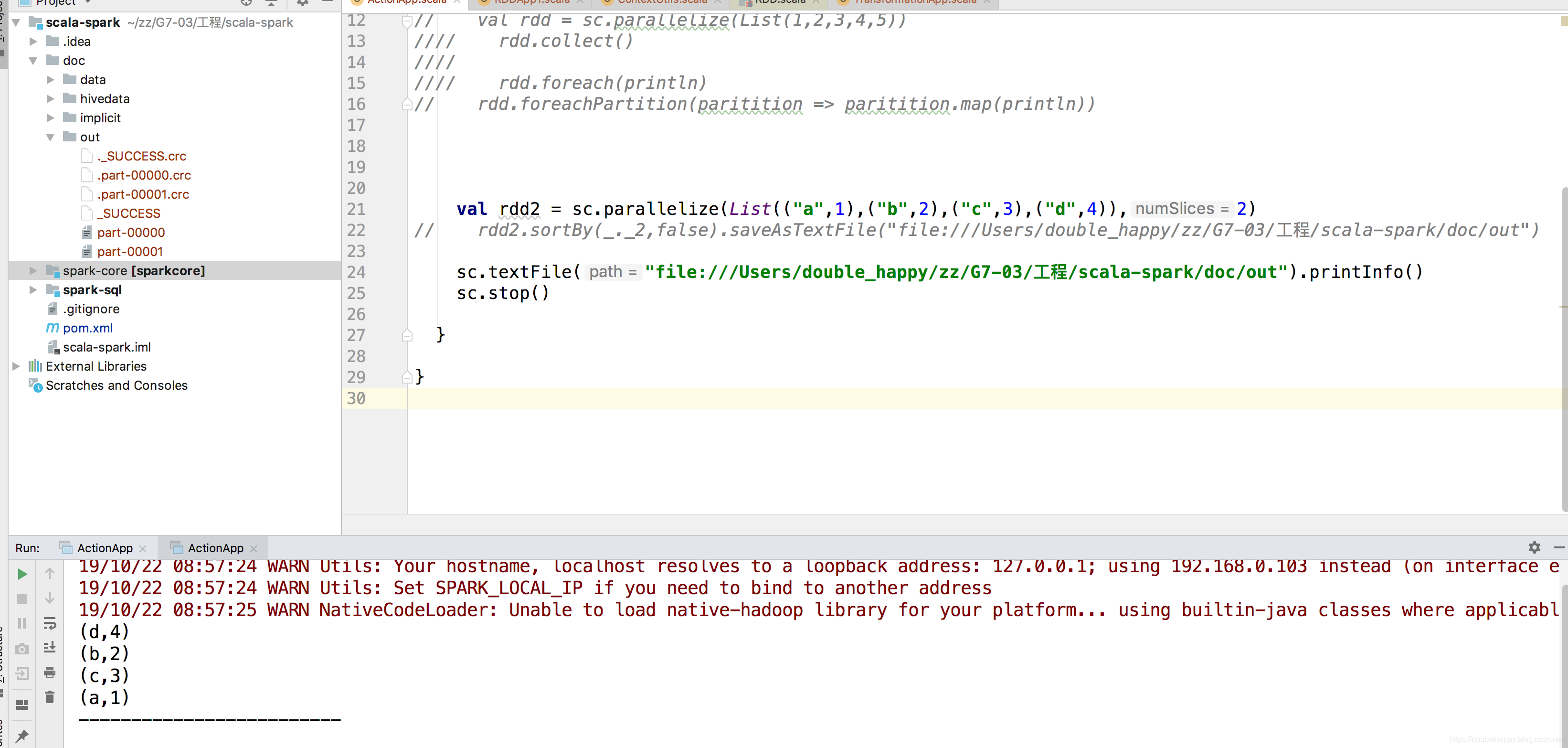
为什么rdd2.sortBy(_._2,false).foreach(println)的结果不一样?
所以使用foreach在这里根本看不出来sortBy是全局排序还是分区排序
因为 rdd2是两个分区的 ,foreach执行的时候 不确定是哪个task先println 出来 明白吗?
所以sortBy 到底是什么排序?
全局排序 你看idea里的
所以你测试的时候 sortBy 后面不能跟着 foreach 来测试 要输出文件
通过 读取文件 来测试
(3)count
/**
* Return the number of elements in the RDD.
*/
def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sum
scala> val rdd = sc.parallelize(List(1,2,3,4,5))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[28] at parallelize at <console>:24
scala> rdd.count
res5: Long = 5
scala>
(4) reduce 两两做操作
scala> val rdd = sc.parallelize(List(1,2,3,4,5))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[28] at parallelize at <console>:24
scala> rdd.count
res5: Long = 5
scala> rdd.reduce(_+_)
res6: Int = 15
scala>
(5) first
/**
* Return the first element in this RDD.
*/
def first(): T = withScope {
take(1) match {
case Array(t) => t
case _ => throw new UnsupportedOperationException("empty collection")
}
}
(6)take
/**
* Take the first num elements of the RDD. It works by first scanning one partition, and use the
* results from that partition to estimate the number of additional partitions needed to satisfy
* the limit.
*
* @note This method should only be used if the resulting array is expected to be small, as
* all the data is loaded into the driver's memory.
*
* @note Due to complications in the internal implementation, this method will raise
* an exception if called on an RDD of `Nothing` or `Null`.
*/
def take(num: Int): Array[T] = withScope {
val scaleUpFactor = Math.max(conf.getInt("spark.rdd.limit.scaleUpFactor", 4), 2)
if (num == 0) {
new Array[T](0)
} else {
val buf = new ArrayBuffer[T]
val totalParts = this.partitions.length
var partsScanned = 0
while (buf.size < num && partsScanned < totalParts) {
// The number of partitions to try in this iteration. It is ok for this number to be
// greater than totalParts because we actually cap it at totalParts in runJob.
var numPartsToTry = 1L
val left = num - buf.size
if (partsScanned > 0) {
// If we didn't find any rows after the previous iteration, quadruple and retry.
// Otherwise, interpolate the number of partitions we need to try, but overestimate
// it by 50%. We also cap the estimation in the end.
if (buf.isEmpty) {
numPartsToTry = partsScanned * scaleUpFactor
} else {
// As left > 0, numPartsToTry is always >= 1
numPartsToTry = Math.ceil(1.5 * left * partsScanned / buf.size).toInt
numPartsToTry = Math.min(numPartsToTry, partsScanned * scaleUpFactor)
}
}
val p = partsScanned.until(math.min(partsScanned + numPartsToTry, totalParts).toInt)
val res = sc.runJob(this, (it: Iterator[T]) => it.take(left).toArray, p)
res.foreach(buf ++= _.take(num - buf.size))
partsScanned += p.size
}
buf.toArray
}
}
first底层调用take方法
scala> val rdd = sc.parallelize(List(1,2,3,4,5))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[28] at parallelize at <console>:24
scala> rdd.count
res5: Long = 5
scala> rdd.reduce(_+_)
res6: Int = 15
scala> rdd.first
res7: Int = 1
scala> rdd.take(2)
res8: Array[Int] = Array(1, 2)
scala>
(7) top
里面肯定是做了排序的
/**
* Returns the top k (largest) elements from this RDD as defined by the specified
* implicit Ordering[T] and maintains the ordering. This does the opposite of
* [[takeOrdered]]. For example:
* {{{
* sc.parallelize(Seq(10, 4, 2, 12, 3)).top(1)
* // returns Array(12)
*
* sc.parallelize(Seq(2, 3, 4, 5, 6)).top(2)
* // returns Array(6, 5)
* }}}
*
* @note This method should only be used if the resulting array is expected to be small, as
* all the data is loaded into the driver's memory.
*
* @param num k, the number of top elements to return
* @param ord the implicit ordering for T
* @return an array of top elements
*/
def top(num: Int)(implicit ord: Ordering[T]): Array[T] = withScope {
takeOrdered(num)(ord.reverse)
}
注意:
1. This does the opposite of
* [[takeOrdered]].
2.top 底层调用的是 takeOrdered
3.top 柯里化的 Ordering 看scala篇这部分 讲的很详细
scala> val rdd = sc.parallelize(List(1,2,3,4,5))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[28] at parallelize at <console>:24
scala> rdd.top(2)
res9: Array[Int] = Array(5, 4)
scala> rdd.takeOrdered(2)
res10: Array[Int] = Array(1, 2)
(8)zipWithIndex
给你一个算子 你怎么知道他是 action还是 transformation??
action算子里面是有sc.runJob()方法的
eg:

所以zipWithIndex 它不是action算子
/**
* Zips this RDD with its element indices. The ordering is first based on the partition index
* and then the ordering of items within each partition. So the first item in the first
* partition gets index 0, and the last item in the last partition receives the largest index.
*
* This is similar to Scala's zipWithIndex but it uses Long instead of Int as the index type.
* This method needs to trigger a spark job when this RDD contains more than one partitions.
*
* @note Some RDDs, such as those returned by groupBy(), do not guarantee order of
* elements in a partition. The index assigned to each element is therefore not guaranteed,
* and may even change if the RDD is reevaluated. If a fixed ordering is required to guarantee
* the same index assignments, you should sort the RDD with sortByKey() or save it to a file.
*/
def zipWithIndex(): RDD[(T, Long)] = withScope {
new ZippedWithIndexRDD(this)
}
scala> val rdd = sc.parallelize(List(1,2,3,4,5))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[28] at parallelize at <console>:24
scala> rdd.zipWithIndex
res11: org.apache.spark.rdd.RDD[(Int, Long)] = ZippedWithIndexRDD[31] at zipWithIndex at <console>:26
scala> rdd.zipWithIndex.collect
res12: Array[(Int, Long)] = Array((1,0), (2,1), (3,2), (4,3), (5,4))
scala>
(9)countByKey
这是action算子
/**
* Count the number of elements for each key, collecting the results to a local Map.
*
* @note This method should only be used if the resulting map is expected to be small, as
* the whole thing is loaded into the driver's memory.
* To handle very large results, consider using rdd.mapValues(_ => 1L).reduceByKey(_ + _), which
* returns an RDD[T, Long] instead of a map.
*/
def countByKey(): Map[K, Long] = self.withScope {
self.mapValues(_ => 1L).reduceByKey(_ + _).collect().toMap
}
(10)collectAsMap 针对kv类型的
/**
* Return the key-value pairs in this RDD to the master as a Map.
*
* Warning: this doesn't return a multimap (so if you have multiple values to the same key, only
* one value per key is preserved in the map returned)
*
* @note this method should only be used if the resulting data is expected to be small, as
* all the data is loaded into the driver's memory.
*/
def collectAsMap(): Map[K, V] = self.withScope {
val data = self.collect()
val map = new mutable.HashMap[K, V]
map.sizeHint(data.length)
data.foreach { pair => map.put(pair._1, pair._2) }
map
}
scala> rdd.zipWithIndex.collect
res12: Array[(Int, Long)] = Array((1,0), (2,1), (3,2), (4,3), (5,4))
scala> rdd.zipWithIndex().countByKey()
res13: scala.collection.Map[Int,Long] = Map(5 -> 1, 1 -> 1, 2 -> 1, 3 -> 1, 4 -> 1)
scala> rdd.zipWithIndex().collectAsMap()
res14: scala.collection.Map[Int,Long] = Map(2 -> 1, 5 -> 4, 4 -> 3, 1 -> 0, 3 -> 2)
scala>
Action算子官网:Action 算子