版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
[double_happy@hadoop101 bin]$ spark-submit --help
Usage: spark-submit [options] <app jar | python file | R file> [app arguments]
Usage: spark-submit --kill [submission ID] --master [spark://...]
Usage: spark-submit --status [submission ID] --master [spark://...]
Usage: spark-submit run-example [options] example-class [example args]
Options:
--master MASTER_URL spark://host:port, mesos://host:port, yarn,
k8s://https://host:port, or local (Default: local[*]).
--deploy-mode DEPLOY_MODE Whether to launch the driver program locally ("client") or
on one of the worker machines inside the cluster ("cluster")
(Default: client).
--class CLASS_NAME Your application's main class (for Java / Scala apps).
--name NAME A name of your application.
--jars JARS Comma-separated list of jars to include on the driver
and executor classpaths.
--packages Comma-separated list of maven coordinates of jars to include
on the driver and executor classpaths. Will search the local
maven repo, then maven central and any additional remote
repositories given by --repositories. The format for the
coordinates should be groupId:artifactId:version.
--exclude-packages Comma-separated list of groupId:artifactId, to exclude while
resolving the dependencies provided in --packages to avoid
dependency conflicts.
--repositories Comma-separated list of additional remote repositories to
search for the maven coordinates given with --packages.
--py-files PY_FILES Comma-separated list of .zip, .egg, or .py files to place
on the PYTHONPATH for Python apps.
--files FILES Comma-separated list of files to be placed in the working
directory of each executor. File paths of these files
in executors can be accessed via SparkFiles.get(fileName).
--conf PROP=VALUE Arbitrary Spark configuration property.
--properties-file FILE Path to a file from which to load extra properties. If not
specified, this will look for conf/spark-defaults.conf.
--driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M).
--driver-java-options Extra Java options to pass to the driver.
--driver-library-path Extra library path entries to pass to the driver.
--driver-class-path Extra class path entries to pass to the driver. Note that
jars added with --jars are automatically included in the
classpath.
--executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G).
--proxy-user NAME User to impersonate when submitting the application.
This argument does not work with --principal / --keytab.
--help, -h Show this help message and exit.
--verbose, -v Print additional debug output.
--version, Print the version of current Spark.
Cluster deploy mode only:
--driver-cores NUM Number of cores used by the driver, only in cluster mode
(Default: 1).
Spark standalone or Mesos with cluster deploy mode only:
--supervise If given, restarts the driver on failure.
--kill SUBMISSION_ID If given, kills the driver specified.
--status SUBMISSION_ID If given, requests the status of the driver specified.
Spark standalone and Mesos only:
--total-executor-cores NUM Total cores for all executors.
Spark standalone and YARN only:
--executor-cores NUM Number of cores per executor. (Default: 1 in YARN mode,
or all available cores on the worker in standalone mode)
YARN-only:
--queue QUEUE_NAME The YARN queue to submit to (Default: "default").
--num-executors NUM Number of executors to launch (Default: 2).
If dynamic allocation is enabled, the initial number of
executors will be at least NUM.
--archives ARCHIVES Comma separated list of archives to be extracted into the
working directory of each executor.
--principal PRINCIPAL Principal to be used to login to KDC, while running on
secure HDFS.
--keytab KEYTAB The full path to the file that contains the keytab for the
principal specified above. This keytab will be copied to
the node running the Application Master via the Secure
Distributed Cache, for renewing the login tickets and the
delegation tokens periodically.
[double_happy@hadoop101 bin]$
spark-submit --master yarn
提交到yarn的时候 肯定是有一堆executor进程的对吧 那么 到底有几个呢?每个executor 多少core?每个executor 多少内存?
这些是提交作业的时候都要配置的
on yarn 模式
--executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G)
--executor-cores NUM Number of cores per executor. (Default: 1 in YARN mode)
per executor到底使用几个cpu core呢?
--num-executors NUM Number of executors to launch (Default: 2).
之前我就遇到一个问题就是
我的数据量 没有我给的executor内存大 为什么程序跑不出来呢?还oom呢?
说明对spark内存管理不了解
Tuning Spark
优化章节
Memory Management Overview
Memory usage in Spark largely falls under one of two categories: execution and storage. Execution memory refers to that used for computation in shuffles, joins, sorts and aggregations, while storage memory refers to that used for caching and propagating internal data across the cluster.
内存分为:
execution : computation in shuffles, joins, sorts and aggregations 用于计算的
storage :caching and propagating internal data 用于存储
所以spark的executor内存是经过划分的 你给他1G 用于计算的达不到1G
查看源码:
SparkEnv类:
val useLegacyMemoryManager = conf.getBoolean("spark.memory.useLegacyMode", false)
val memoryManager: MemoryManager =
if (useLegacyMemoryManager) {
new StaticMemoryManager(conf, numUsableCores)
} else {
UnifiedMemoryManager(conf, numUsableCores)
}
spark.memory.useLegacyMode 什么意思呢?去官网找一下
决定你spark采用什么样的内存管理机制
是否使用历史遗留版本 false

1.SparkEnv类 进去搜索memoryManager
2.点进去StaticMemoryManager
3.点进去getMaxExecutionMemory 或者getMaxStorageMemory 点不进去 说明这个方法就在这个类里面
搜索getMaxExecutionMemory
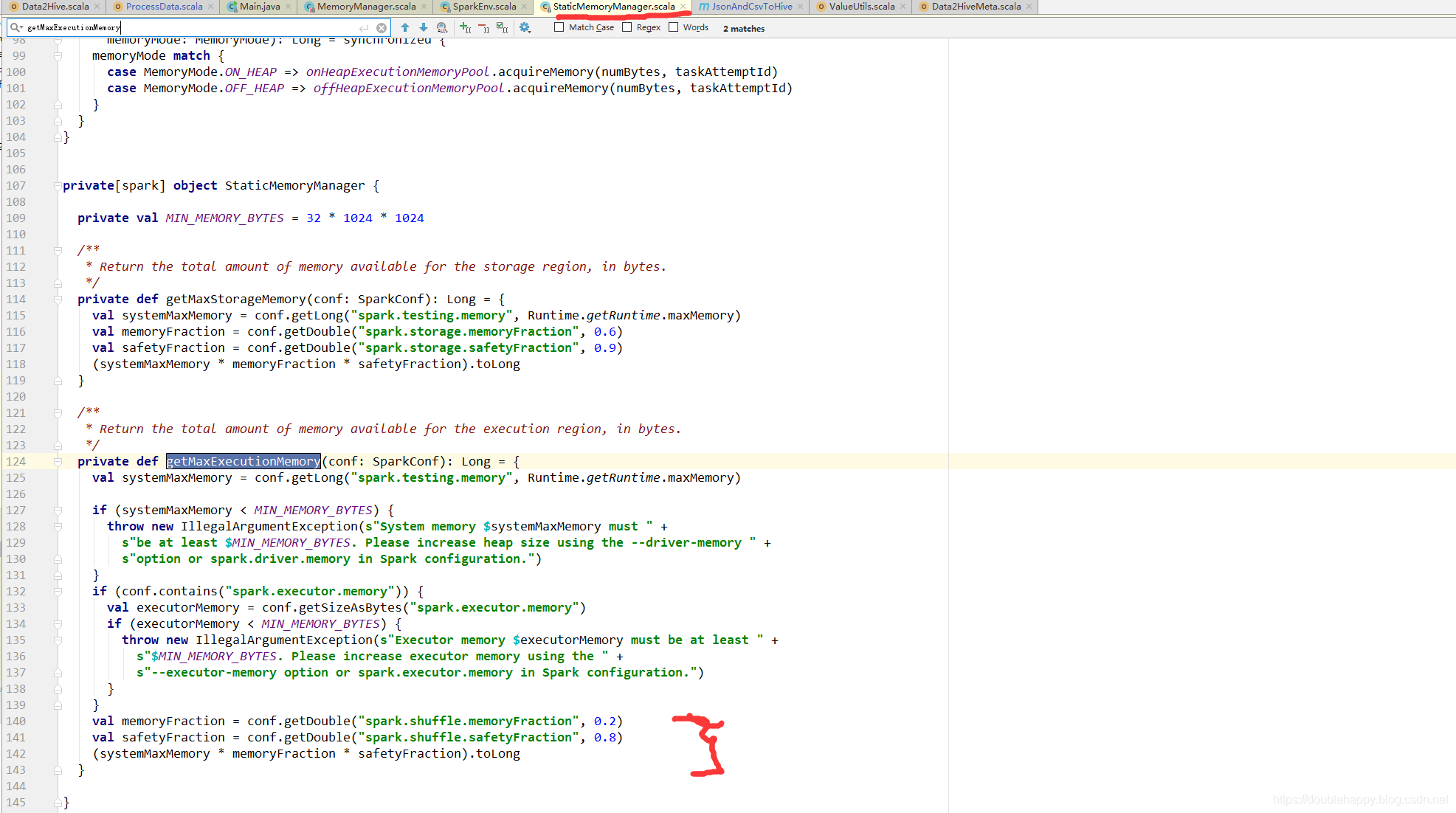
StaticMemoryManager 历史遗留版本 静态内存管理
UnifiedMemoryManager 统一内存管理
静态内存管理机制: 存储和执行是单独的
StaticMemoryManager {
getMaxExecutionMemory{
val systemMaxMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)
......
val memoryFraction = conf.getDouble("spark.shuffle.memoryFraction", 0.2) //默认0.2
val safetyFraction = conf.getDouble("spark.shuffle.safetyFraction", 0.8) //默认0.8
(systemMaxMemory * memoryFraction * safetyFraction).toLong //1000m*0.2*0.8 = 160m
你传进来1g 真正用来计算的Execution 才 160m
}
getMaxStorageMemory{
val memoryFraction = conf.getDouble("spark.storage.memoryFraction", 0.6)
val safetyFraction = conf.getDouble("spark.storage.safetyFraction", 0.9)
(systemMaxMemory * memoryFraction * safetyFraction).toLong //1000m*0.6*0.9 = 540m
你传进来1g 用来存储的的Storage 540m
如果你整个作业不需要 cache 不需要缓存 那么这个部分的内存就浪费掉了
}
}
systemMaxMemory 假设是传进来的内存 实际上比传进来的内存小一点
所以你传进来的内存 是有个占比 有安全系数占比
统一内存管理:存储和执行内存是公用的 ==》会有相互借内存的
UnifiedMemoryManager{
val maxMemory = getMaxMemory(conf){
val systemMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)
val reservedMemory = 300m
。。。。。
//1000m - 300m
val usableMemory = systemMemory - reservedMemory
val memoryFraction = conf.getDouble("spark.memory.fraction", 0.6)
(usableMemory * memoryFraction).toLong //(1000m - 300m)*0.6 = 420m
你真正能使用的内存 420m 这是存储端和执行端公有的 就这么多
}
//存储的占了0.5
onHeapStorageRegionSize =
(maxMemory * conf.getDouble("spark.memory.storageFraction", 0.5)).toLong
}
getMaxMemory :Return the total amount of memory shared between execution and storage, in bytes.
所以最终:
Storage : (1000m - 300m)*0.6*0.5 = 210m
Execution : 210m
新版内存管理:
In Spark, execution and storage share a unified region (M). When no execution memory is used, storage can acquire all the available memory and vice versa.
no execution memory is used 那么storage 会获取所有资源
Spark1.0版本:
静态资源管理:
execution | storage
1.如果storage用来做cache的很少 storage就剩余很多内存资源
那么execution 做sort、join、shuffle的如果 这部分的内存资源不够 只能 spill to disk 。
2.反过来
到了Spark1.6版本:
统一内存管理:
名字都变了
execution|storage 默认各占50%
这块 execution的优先级高,storage如果cache的满了 把cache的数据spill to disk,
如果execution的不够用,那么他会去storage拿资源,极限情况下,只会给storage留一丢丢资源,不会让storage很没面子。但是 execution就是有借无还,谁让他优先级高呢。
还有一点就是 execution借完了之后 storage此时也需要cache 为什么execution不能还给storage内存呢?
如果此时execution 正在shuffle 还了内存 execution 会出现问题的 所以不能还