最近又看到了迭代和解析的知识点,今天做一次更新吧,把迭代和解析讲完。
关于扩展生成器函数协议:send和next 我没有看懂,也没有看到用的意义,这里就不讲了,如果以后发现了,会再上一讲补充。
4.2 生成器表达式:迭代器遇到列表解析
a = [x ** 2 for x in range(4)] # 这个是列表解析:build a list b = (x ** 2 for x in range(4)) # 这个是生成器表达式(generator expression):make a iterable
从语法上讲,生成器表达式就像一般的解析列表一样,一个是方括号,一个是圆括号。但生成器表达式大体上可以认为是对内存空间的优化,它们不需要像列表解析一样,一次构造出整个结果列表。
其实将生成器表达式转化为列表解析的方法,只需要使用List,强迫生成器表达式一次生成列表中所有的结果 即:a == list(b)
4.3 生成器是单迭代器对象
一个生成器的迭代器是生成器本身。即在生成器上调用iter没有任何效果。生成器只能是一个单迭代对象,不能是多个迭代对象。即一旦任何迭代器运行到完成,所有的迭代器都将用尽,我们必须产生一个新的迭代器以再次开始。
G=(a for a in range(10)) print(list(G)) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] print(list(G)) # []
注:这里必须使用list(G),不能用[G] 否则会返回一个地址给你。
5.基于类的迭代器
类的常见运算符重载方法中,和迭代有关的有__getitem__,__setitem__,__iter__和__next__
但在Python中所有的迭代环境会先尝试__iter__方法,再尝试__getitem__。因此这里重点讲__iter__和__next__
5.1 用户定义的迭代器
在__iter__机制中,类就是通过实现迭代器协议来实现用户定义的迭代器的。例如,定义了用户定义的迭代器类来生成平方值。在这里,迭代器对象就是实例self(__iter__的写法一般固定,有时候如pytorch的dataloader有所不同),因为next方法是这个类的一部分。
class Squares: def __init__(self, start, stop): self.value = start -1 self.stop = stop def __iter__(self): return self def __next__(self): if self.value == self.stop: raise StopIteration self.value +=1 return self.value ** 2 for i in Squares(1,5): # for calls this iter, which calls __iter__, means i = Iter(Squares(1,5)) print(i, end=' ') # Each iteration calls __next__, means next(i)->next(i)
注意:这里的__iter__只循环一次,而不是循环多次。例如:
X = squares(1,5) print([n for n in X]) # [1, 4, 9, 16, 25] print([n for n in X]) # []
5.2有多个迭代器的对象
要达到多个迭代器的效果,__iter__只需要迭代器定义新的状态对象,而不是返回self。
class SkipIterator: def __init__(self,skipper): self.wrapped = skipper.wrapped self.offset = 0 def __next__(self): if self.offset >=len(self.wrapped): raise StopIteration else: item = self.wrapped[self.offset] self.offset +=2 return item class SkipObject: def __init__(self,wrapped): self.wrapped = wrapped def __iter__(self): return SkipIterator(self) alpha = 'abcdef' skipper = SkipObject(alpha) I = iter(skipper) print(next(I),next(I),next(I)) # a c e for x in skipper: for y in skipper: print(x+y, end=' ') # aa ac ae ca cc ce ea ec ee
运行时,这个例子工作起来就像是对内置字符串进行嵌套循环一样,因为每个循环都会获得独立的迭代器对象来记录自己的状态信息,所以每个激活状态下的循环都有自己字符串中的位置。
即x和y在SkipObject对象中分别创立了两个SkipIterator迭代器对象。
5.3 Pytorch1.0 datasetloader源码分析
torch的Dataloader类在torch.utils.data.dataloader文件中。如下图所示,显然这个Dataloader和上面的有多个迭代器的对象实现方法相同,有一个_DataLoaderIter类,这里我们重点关注这个类的实现。
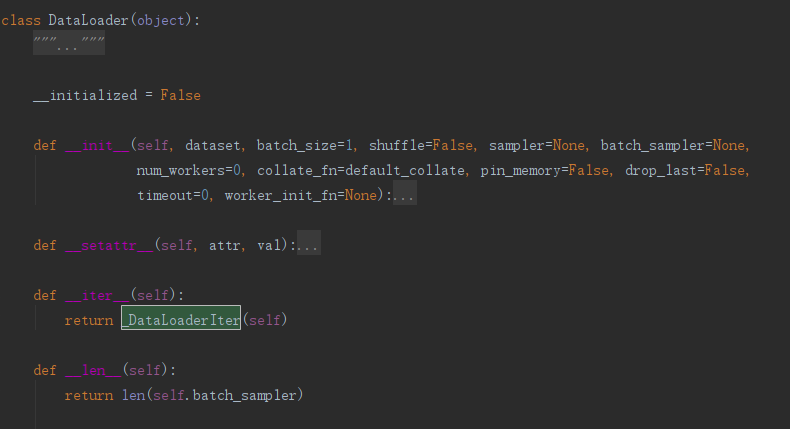
class _DataLoaderIter(object): def __init__(self, loader): xxx def __len__(self): return len(self.batch_sampler) def _get_batch(self): xxx def __next__(self): if self.num_workers == 0: # same-process loading indices = next(self.sample_iter) # may raise StopIteration batch = self.collate_fn([self.dataset[i] for i in indices]) if self.pin_memory: batch = pin_memory_batch(batch) return batch # check if the next sample has already been generated if self.rcvd_idx in self.reorder_dict: batch = self.reorder_dict.pop(self.rcvd_idx) return self._process_next_batch(batch) if self.batches_outstanding == 0: self._shutdown_workers() raise StopIteration while True: assert (not self.shutdown and self.batches_outstanding > 0) idx, batch = self._get_batch() self.batches_outstanding -= 1 if idx != self.rcvd_idx: # store out-of-order samples self.reorder_dict[idx] = batch continue return self._process_next_batch(batch) next = __next__ # Python 2 compatibility def __iter__(self): return self def _put_indices(self): xxx def _process_next_batch(self, batch): xxx def __getstate__(self): raise NotImplementedError("_DataLoaderIter cannot be pickled") def _shutdown_workers(self): xxx def __del__(self): # 析构函数,iter对象收回 if self.num_workers > 0: self._shutdown_workers()
如上述具体代码所示,dataloader类的迭代器是类dataloaderIter。先将dataloader的实例化传入dataloaditer类进行实例化,参数名为loader。这里的关注重点是在每次迭代时候调用__next__函数。
我们先分析第一个if 语句self.num_workers == 0的情况:
indices = next(self.sample_iter) # may raise StopIteration batch = self.collate_fn([self.dataset[i] for i in indices]) if self.pin_memory: batch = pin_memory_batch(batch) return batch
这里self.sample_iter是一个迭代器(iterator,注我们知道生成器本身就是迭代器,但是list这些是没有迭代器的)。
# 根据上面的调用,我们可以找到 # self.sample_iter = iter(self.batch_sampler) # batch_sampler = BatchSampler(sampler, batch_size, drop_last) # 而BatchSampler的__iter__代码如下: def __iter__(self): batch = [] for idx in self.sampler: batch.append(idx) if len(batch) == self.batch_size: yield batch batch = [] if len(batch) > 0 and not self.drop_last: yield batch
因此 self.sample_iter 本质是一个生成器。而这里的 self.sampler 是一个打乱idx顺序的list。list的长度是batch_size。即获得一个长度为batch size的列表:indices,
这个列表的每个值表示一个batch中每个数据的index,每执行一次next操作都会读取一批长度为batch size的indices列表。然后通过self.collate_fn函数将batch size个tuple(每个tuple长度为2,其中第一个值是数据,Tensor类型,第二个值是标签,int类型)封装成一个list,这个list长度为2,两个值都是Tensor,一个是batch size个数据组成的FloatTensor,另一个是batch size个标签组成的LongTensor。
batch =self.collate_fn 则是将上面的indices(=next(self.sample_iter))这些分散的tensor合并成一个整体tensor,然后将tensor copy到CUDA中。
如果 self.num_workers 不等于0,这个时候显然是一个多线程程序(假设我们在合理default kernels=8)。直接进入第二个if语句判断当前想要读取的batch的index(self.rcvd_idx)是否之前已经读出来过。
# check if the next sample has already been generated if self.rcvd_idx in self.reorder_dict: batch = self.reorder_dict.pop(self.rcvd_idx) return self._process_next_batch(batch)
而第三个if语句,self.batches_outstanding的值在前面初始中调用self._put_indices()方法时修改了,所以假设你的进程数self.num_workers设置为3,那么这里self.batches_outstanding就是3*2=6,可具体看self._put_indices()方法。
if self.batches_outstanding == 0: self._shutdown_workers() raise StopIteration
最后就是 while循环就是真正用来从队列中读取数据的操作。
最主要的就是idx, batch = self._get_batch(),通过调用_get_batch()方法来读取,后面有介绍,简单讲就是调用了队列的get方法得到下一个batch的数据,得到的batch一般是长度为2的列表,列表的两个值都是Tensor,分别表示数据(是一个batch的)和标签。_get_batch()方法除了返回batch数据外,还得到另一个输出:idx,这个输出表示batch的index,这个if idx != self.rcvd_idx条件语句表示如果你读取到的batch的index不等于当前想要的index:selg,rcvd_idx,那么就将读取到的数据保存在字典self.reorder_dict中:self.reorder_dict[idx] = batch,然后继续读取数据,直到读取到的数据的index等于self.rcvd_idx。
while True: assert (not self.shutdown and self.batches_outstanding > 0) idx, batch = self._get_batch() self.batches_outstanding -= 1 if idx != self.rcvd_idx: # store out-of-order samples self.reorder_dict[idx] = batch continue return self._process_next_batch(batch)
关于torch dataloader的代码解析,我主要是参考的:https://blog.csdn.net/u014380165/article/details/79058479
5.4 tqdm库
Tqdm 是一个快速,可扩展的Python进度条,可以在 Python 长循环中添加一个进度提示信息,用户只需要封装任意可迭代的对象(iteraable object)不是迭代器(iterator)。
一般迭代器(iter)和next联合使用,达到for 的效果,而for中使用的是可迭代对象,而可迭代对象可以通过写入方法__next__和__iter__来创建可迭代类。
while True: try: X = next(iter) except StopIteration: break print(X)
在使用tqdm库的时候,一定要写total 不然不显示进度条,以下就是自己写的一个迭代类,并使用tqdm显示进度条的例子了。
from tqdm import tqdm from time import sleep class IterObj(): def __init__(self,start,stop): self.value = start -1 self.stop = stop def __iter__(self): return self def __next__(self): if self.value == self.stop: raise StopIteration self.value+=1 return self.value ** 2 if __name__ == '__main__': a = IterObj(1,5) b = tqdm(a,total=5) for i in b: sleep(1)