请求头
对爬虫有一定实战经验的人都知道,我们往往需要加请求头。那么为什么需要加请求头呢? 因为搜索引擎其实就是个爬虫,大部分的网页都是允许搜索引擎爬虫来进行爬取的,所以当我们模拟搜索引擎对网页进行爬取的时候就可以在某些场合下爬到数据啦。
更换ip地址
但有时候模拟搜索引擎进行爬取时候也会出问题,我们每一台电脑默认都只有一个唯一的ip地址,如果在同一时段内同一IP地址多次重复对某一网站进行有规律地爬取,这样是很容易被发现进而你的ip被拉入了黑名单。进入黑名单也就意味着你的ip被发现是用于爬虫的,再次使用的话会出现重定向,获取不到数据,获取到假数据的情况,在这样的情况下,我们就需要更换爬虫所用的ip了,下面介绍几种非常好用的更换代理ip的方法。
更换代理ip的方法
1.通过ip代理池获取代理
这里给出一个github网站,你可以直接下载下来,github代理项目,安装需要的库,直接run.py就可以运行并等待爬取将可用代理全部装入代理池redis中
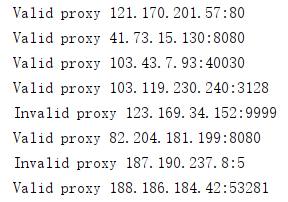
 从各大代理网站爬取代理进行测试使用:
从各大代理网站爬取代理进行测试使用:
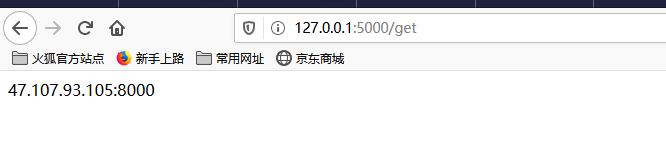
访问网址http://127.0.0.1:5000/get获取代理,刷新后继续获取
 redis代理池
redis代理池
 [Note]: 如果你的爬虫项目不大,那么完全可以从代理池中拿几个代理直接使用,如果爬取的项目比较大,那么你可以自己写个爬取http://127.0.0.1:5000/get的代码自动从这里面拿代理,这种方式也适合每天定时爬取的项目。
[Note]: 如果你的爬虫项目不大,那么完全可以从代理池中拿几个代理直接使用,如果爬取的项目比较大,那么你可以自己写个爬取http://127.0.0.1:5000/get的代码自动从这里面拿代理,这种方式也适合每天定时爬取的项目。
当然你也可以自己维护一个ip代理池,从各大免费的代理网站上爬取代理,然后自己对ip进行验证,如果访问你所要爬取的网站返回的状态码是200,那么就加入ip列表中,否则不加入列表,继续爬取。
2.通过购买代理进行爬取
如果你经济允许的话,可以购买私密代理进行使用,一般代理网站都会给出代理使用的API,你只需要访问它的接口网址就可以拿到代理了。
#!/usr/bin/env python
#-*- coding: utf-8 -*-
"""使用requests调用API接口
import requests
#api链接
api_url = "http://dev.kdlapi.com/api/getproxy/?orderid=965102959536478&num=100&protocol=1&method=2&an_ha=1&sep=1"
headers = {"Accept-Encoding": "gzip"} #使用gzip压缩传输数据让访问更快
r = requests.get(url=api_url, headers=headers)
print(r.status_code) #获取Reponse的返回码
print(r.content.decode('utf-8')) #获取页面内容
需要提醒你的是,虽然你用的是购买了的代理IP,但是仍然会出现使用不了的情况,本人之前买过的快XX就是到了半个月期限的时候所有代理都用不了,但是用第一种方式可以正常爬取网站,所以建议你去别的代理网站去购买。