版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
目录
- 创建
- 数据库文件和文件组
- 语法 CREATE DATABASE
- 修改
- 增加 | 删除文件和文件组
- 数据库收缩
- 8种常用数据库选项
- 重命名数据库
- 删除
1.数据库管理
数据库是存储表、索引以及表之间逻辑运算关系的容器。
1.1 创建数据库
创建时,需明确数据库的名称、所有者、大小以及存储该数据库的文件和文件组。
- 注意:
1.有权限
2.创建者将成为所有者
3.一个服务器实例可创建32767个数据库
4.数据库名称命名遵循标识符规则
5.创建数据库时,model数据库中所有用户定义对象都将复制到所有新数据库中。(get可以向model数据库中添加任何对象,以便这些对象包含到所有新建的数据库中。)
1.1.1 数据库文件和文件组
文件组是文件的命名集合,用于简化数据存放和管理任务(如备份和还原)。
- 数据库文件
1.主文件(.mdf),每个数据库都有一个主文件,包含数据库的启动信息,也用于存储数据。
2.次要文件(.ndf),非必须,包含不能放置在主文件中的所有数据。
3.事务日志文件(.ldf),每个数据库必须至少一个事务日志文件,包含用于恢复数据库的日志信息,最小512KB。 - 文件组
每个文件组有一个PRIMARY文件组,包含主文件和未放入其他文件组的次要文件。
1.填充策略:对组内所有文件都使用按比例填充。eg.文件组有2个文件,f1有100M可用,f2有200M可用,则从f1分配一个区,f2分配两个区,两个文件几乎同时填满。
2.文件扩展:自动轮流扩展组内一个文件(自动增长)。eg.文件组有f1,f2两个文件,组内文件都满后,自动扩展f1,f1满后自动扩展f2,f2满后自动拓展f1……类推。
3.数据库性能优化:1)允许跨多个磁盘创建数据库,实现并发访问数据。2)可以将特定表的所有I/O定向到一个特定的磁盘(如建立常用文件组)。 - 文件和文件组设计规则
1.多个DB不能共用一个文件/组
2.多个文件组不能共用一个文件
3.事务日志不属于任何文件组
4.建议:1)如使用多个文件,将附加文件都放入第2个文件组,并设置为默认。主文件只包含系统表和对象。2)事务日志文件与其它文件和文件组放于不同磁盘。
1.1.2 语法 CREATE DATABASE
创建数据库后,应备份master数据库。因为创建数据库会更新master中的系统表。
/* eg.1 默认
- 主文件 数据大小为model数据库主文件的大小
- 事务日志文件 512KB或主数据文件大小的25%(较大者)
- 文件可以自动增大到填满所有可用磁盘
*/
IF DB_ID('mydata') IS NOT NULL
DROP DATABASE mydata
GO
CREATE DATABASE mydata
eg.2 指定数据文件和事务日志文件
IF DB_ID('mydata') IS NOT NULL
DROP DATABASE mydata
GO
CREATE DATABASE mydata
ON
-- [PRIMARY] -- 此处被省略,可显示指定主文件
( NAME = Sales_dat, -- 第1个文件默认为主文件
FILENAME = 'd:\saledat.mdf',
SIZE = 10, -- 初始大小,默认MB
MAXSIZE = 50, -- 最大,达到后不再继续增长
FILEGROWTH = 5) -- 自动增长
LOG ON -- 事务日志文件
( NAME = Sales_log,
FILENAME = 'd:\Salelog.ldf',
SIZE = 5MB,
MAXSIZE = 25MB,
FILEGROWTH = 5MB)
eg.3
-- 包含文件Spri1_dat和Spri2_dat的PRIMARY文件组。将这些文件的FILEGROWTH增量指定为15%
-- 名为SalesGroup1的文件组,其中包含文件SGrp1Fi1和SGrp1Fi2;
-- 名为SalesGroup2的文件组,其中包含文件SGrp2Fi1和SGrp2Fi2。
IF DB_ID('mydata') IS NOT NULL
DROP DATABASE mydata
GO
CREATE DATABASE mydata
ON PRIMARY
( NAME = SPri1_dat,
FILENAME = 'd:\SPri1dat.mdf',
SIZE = 10, -- 默认MB
MAXSIZE = 50,
FILEGROWTH = 15% ),
( NAME = SPri2_dat,
FILENAME = 'd:\SPri2dt.ndf',
SIZE = 10,
MAXSIZE = 50,
FILEGROWTH = 15% ),
FILEGROUP SalesGroup1
( NAME = SGrp1Fi1_dat,
FILENAME = 'd:\SG1Fi1dt.ndf',
SIZE = 10,
MAXSIZE = 50,
FILEGROWTH = 5 ),
( NAME = SGrp1Fi2_dat,
FILENAME = 'd:\SG1Fi2dt.ndf',
SIZE = 10,
MAXSIZE = 50,
FILEGROWTH = 5 ),
FILEGROUP SalesGroup2
( NAME = SGrp2Fi1_dat,
FILENAME = 'd:\SG2Fi1dt.ndf',
SIZE = 10,
MAXSIZE = 50,
FILEGROWTH = 5 ),
( NAME = SGrp2Fi2_dat,
FILENAME = 'd:\SG2Fi2dt.ndf',
SIZE = 10,
MAXSIZE = 50,
FILEGROWTH = 5 )
LOG ON
( NAME = Sales_log,
FILENAME = 'd:\salelog.ldf',
SIZE = 5MB,
MAXSIZE = 25MB,
FILEGROWTH = 5MB ) ;
1.2 修改数据库
- 增加 | 删除
-- 文件
-- 修改文件设置
ALTER DATABASE mydata
MODIFY FILE
( NAME = SPri2_dat,
SIZE = 15,
MAXSIZE = 100,
FILEGROWTH = 10% )
-- 增加数据文件
ALTER DATABASE mydata
ADD FILE
(
NAME = SGrp1Fi3_dat,
FILENAME = 'D:\SG1Fi3dt.ndf',
SIZE = 5,
MAXSIZE = 10,
FILEGROWTH = 1)
TO FILEGROUP SalesGroup1
-- 删除文件
ALTER DATABASE mydata
REMOVE FILE SGrp1Fi2_dat
-- 文件组
-- 增加文件组
ALTER DATABASE mydata
ADD FILEGROUP SalesGroup3
-- 修改文件组名
ALTER DATABASE mydata
MODIFY FILEGROUP SalesGroup3
NAME = SaleGroup4
- 收缩
-- 手动收缩
DBCC SHRINKDATABASE('mydata', 1)
GO
-- 自动
ALTER DATABASE mydata
SET AUTO_SHRINK ON
- 8种常用数据库选项
-- 1.
-- 自动收缩数据库可用空间大小 默认OFF,关闭
AUTO_SHRINK
-- 2.
-- 默认OFF,ON-双引号可用于标识符
QUOTED_IDENTIFIER
-- 3.
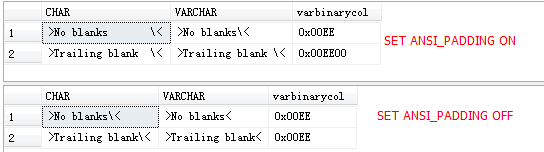
-- 应始终为ON,修改后仅影响新列。
-- ON- 填充时,用空白填充char列,用零填充二进制列。
-- OFF- 修剪后,char列的尾随空白被修剪,二进制列的尾随零被修剪。
ANSI_PADDING
-- 测试
PRINT 'Testing with ANSI_PADDING ON'
SET ANSI_PADDING ON;
GO
CREATE TABLE t1 (
charcol CHAR(16) NULL,
varcharcol VARCHAR(16) NULL,
varbinarycol VARBINARY(8)
);
GO
INSERT INTO t1 VALUES ('No blanks', 'No blanks', 0x00ee);
INSERT INTO t1 VALUES ('Trailing blank ', 'Trailing blank ', 0x00ee00);
SELECT 'CHAR' = '>' + charcol + '\<', 'VARCHAR'='>' + varcharcol + '\<',
varbinarycol
FROM t1;
GO
DROP TABLE t1;
PRINT 'Testing with ANSI_PADDING OFF';
SET ANSI_PADDING OFF;
GO
CREATE TABLE t2 (
charcol CHAR(16) NULL,
varcharcol VARCHAR(16) NULL,
varbinarycol VARBINARY(8)
);
GO
INSERT INTO t2 VALUES ('No blanks', 'No blanks', 0x00ee);
INSERT INTO t2 VALUES ('Trailing blank ', 'Trailing blank ', 0x00ee00);
SELECT 'CHAR' = '>' + charcol + '\<', 'VARCHAR'='>' + varcharcol + '<',
varbinarycol
FROM t2;
GO
DROP TABLE t2;
-- 4.
-- = <>与null比较运算时返回UNKNOWN
-- 建议始终保持 ON,将来可能无OFF
ANSI_NULLS -- 默认ON

-- 5.
-- ON 允许插入空值
ANSI_NULLS_DFLT_ON
-- 测试正常
SET ANSI_NULL_DFLT_ON ON
if object_id('t1', 'U') is not null
drop table t1
GO
CREATE TABLE t1(x int, y int)
INSERT INTO t1 VALUES(null, null)
SELECT * FROM t1
GO
-- 6.
-- ON 发出警告
-- 如果汇总函数中出现空值
-- 除0、算术溢出错误
ANSI_WARNINGS
-- 7. IMPLICT_TRANSACTION
-- 7.1 ON 设置为隐式事务模式,如果@@TRANCOUNT = 0,以下操作都会开始一个新的事务,相当于默认先执行一个BEGIN TRAN
当隐式事务模式时,如果@@ trancount> 0已经存在,则不会发出看不见的BEGIN TRANSACTION。但是,任何显式的BEGIN TRANSACTION语句仍将@@ TRANCOUNT递增。
未从表中选择的SELECT语句不会启动隐式事务。例如SELECT GETDATE();还是SELECT 1, ‘ABC’。
由于ANSI默认值,隐式事务可能会意外打开。
-- 7.2 OFF 默认是auticommit自动事务模式,可以主动发出显示事务(BEGIN TRAN)
当您的INSERT语句和工作单元中的任何其他操作完成时,您必须发出COMMIT TRANSACTION语句,直到@@ TRANCOUNT递减为0。或者您可以发出一个ROLLBACK TRANSACTION。
-- 8. NOCOUNT
-- ON 返回sql语句影响的行数
SET NOCOUNT ON
- 重命名数据库
重命名前应确保无人使用该数据库,且将数据库设置为单用户模式。
CREATE DATABASE tt
GO
-- 设置为单用户模式
ALTER DATABASE tt
SET SINGLE_USER
GO
-- 修改
ALTER DATABASE tt
MODIFY NAME = tt1
GO
-- 设置为多用户模式
ALTER DATABASE tt1
SET MULTI_USER
GO
1.3 删除数据库
数据库删除后,文件和数据都将从磁盘删除。
可以不用管数据库所处的状态。
备注:
- 1.必须先删除数据库上存在的数据库快照。
- 2.如果涉及日志传送操作,应先取消日志传送。
- 3.删除为事务复制发布的数据库,或删除为合并复制发布的数据库,应先删除复制。如数据库损坏,可先ALTER DATABASE修改为脱机,然后删除。
- 4.删除后备份master。删除数据库会更新master中信息。
-- database_snapshop 数据库快照
DROP DATABASE { dbname | database_snapshot_name}