null数据类型的查询:
--在进行值为null数据的查询时,所有值为null,以及不包含指定键的文档均会被检索出来。
> db.test.find({"x":null})
{ "_id" : ObjectId("4fd59d30b9ac507e96276f1b"), "x" : null }
{ "_id" : ObjectId("4fd59d49b9ac507e96276f1c"), "y" : 1 }
--需要将null作为数组中的一个元素进行相等性判断,即便这个数组中只有一个元素。
--再有就是通过$exists判断指定键是否存在。
> db.test.find({"x": {"$in": [null], "$exists":true}})
{ "_id" : ObjectId("4fd59d30b9ac507e96276f1b"), "x" : null }
数组查询,查询国家数组中有中国的电影

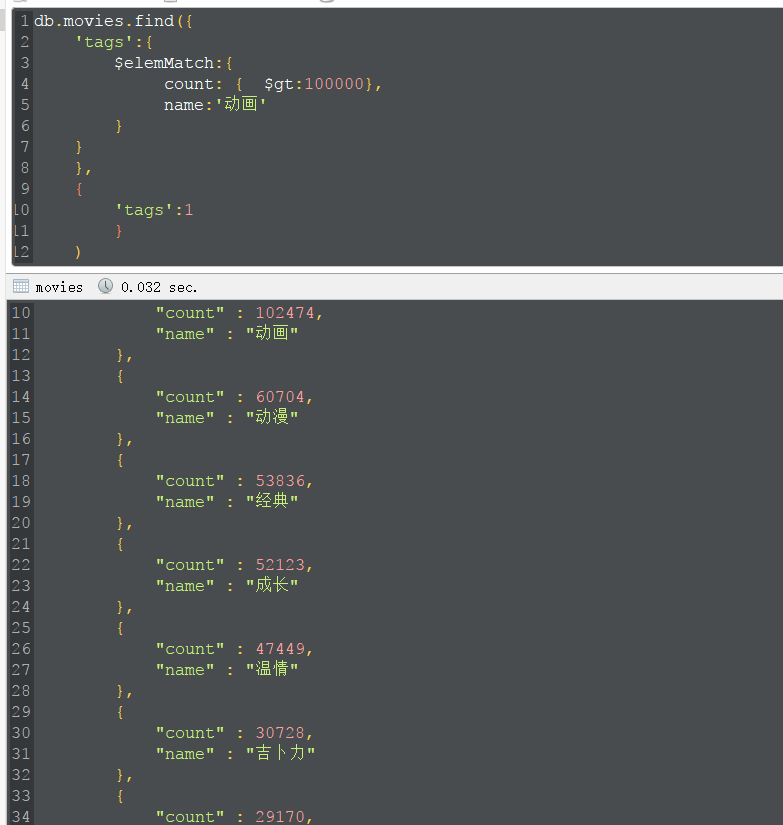
查询tags数组中,至少有一个元素满足count大于一万且name为动漫的电影
检索数组中需要包含多个元素的情况,这里使用$all。出现顺序无关紧要

下面的示例表示精确匹配,即被检索出来的文档,数组数据必须和查询条件完全匹配,即不能多,也不能少,顺序也必须保持一致。

匹配数组中指定下标元素的值。数组的起始下标是0。
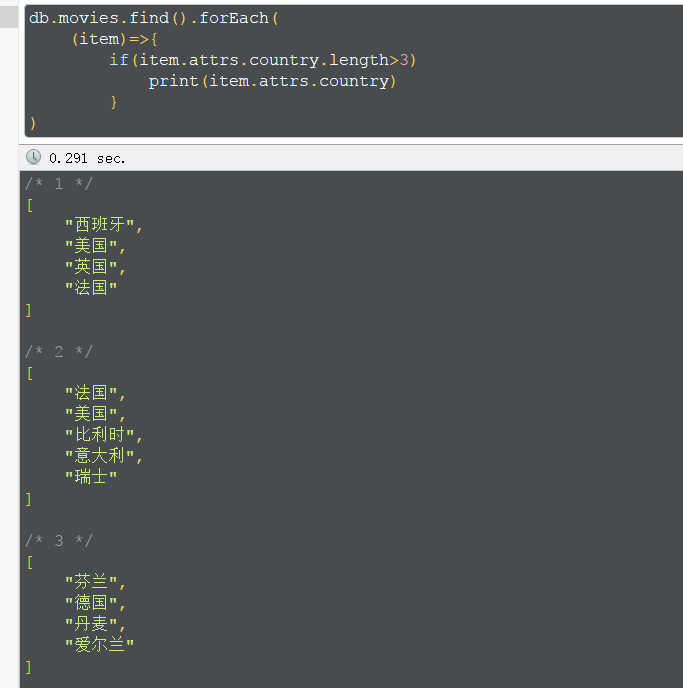
通过$size获取数组的长度,但是$size不能和比较操作符联合使用。如果需要查找数组长度在一定范围,可以增加一个字段或者使用函数

使用forEach,花费时间比较长
通过$slice返回数组中的部分数据。"$slice":2表示数组中的前两个元素。
通过$slice返回数组中的部分数据。"$slice":-2表示数组中的后两个元素。
$slice : [2,1],表示从第二个2元素开始取1个,如果获取数量大于2后面的元素数量,则取后面的全部数据

嵌套查询,并且返回字段为指定字段,指定显示或者不显示的字段,不能混合使用1和0


当嵌入式文档为数组时,需要$elemMatch操作符来帮助定位某一个元素匹配的情况,否则嵌入式文件将进行全部的匹配。
即检索时需要将所有元素都列出来作为查询条件方可。
> db.test.findOne()
{
"_id" : ObjectId("4fd5af76b9ac507e96276f23"),
"comments" : [
{
"author" : "joe",
"score" : 3
},
{
"author" : "mary",
"score" : 6
}
]
}
> db.test.find({"comments": {"$elemMatch": {"author":"joe","score":{"$gte":3}}}}
{ "_id" : ObjectId("4fd5af76b9ac507e96276f23"), "comments" : [ { "author" : "joe", "score" : 3 }, { "author" : "mary", "score" : 6 } ] }
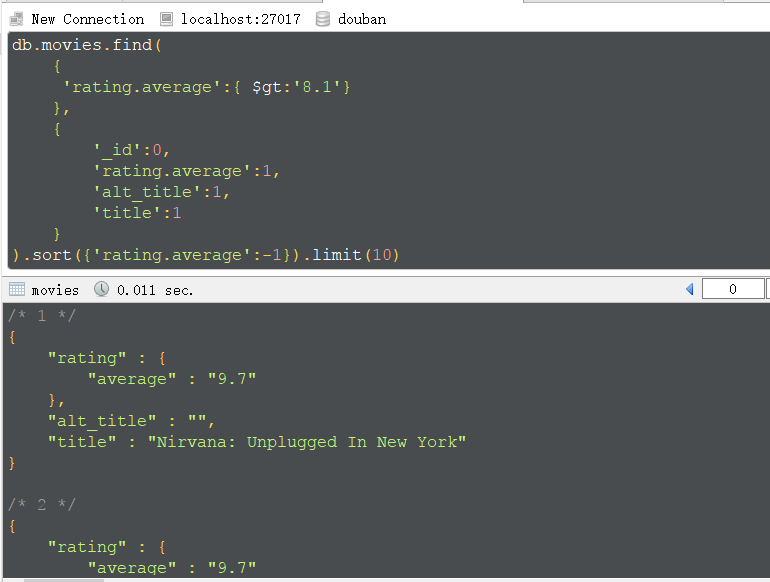
查找高分电影
统计各个分段电影数目,并重命名字段

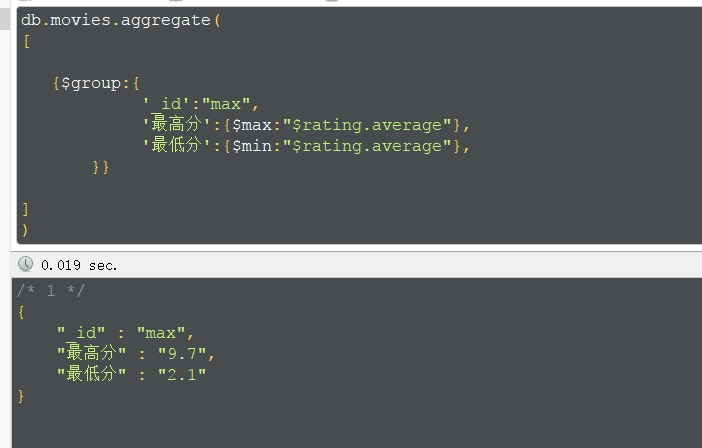
查询最高分和最低分
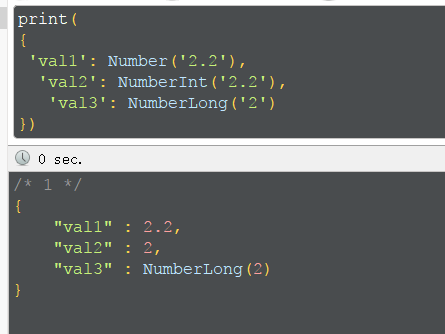
类型转换,NumberLong 对字符串格式有要求,不能有小数点
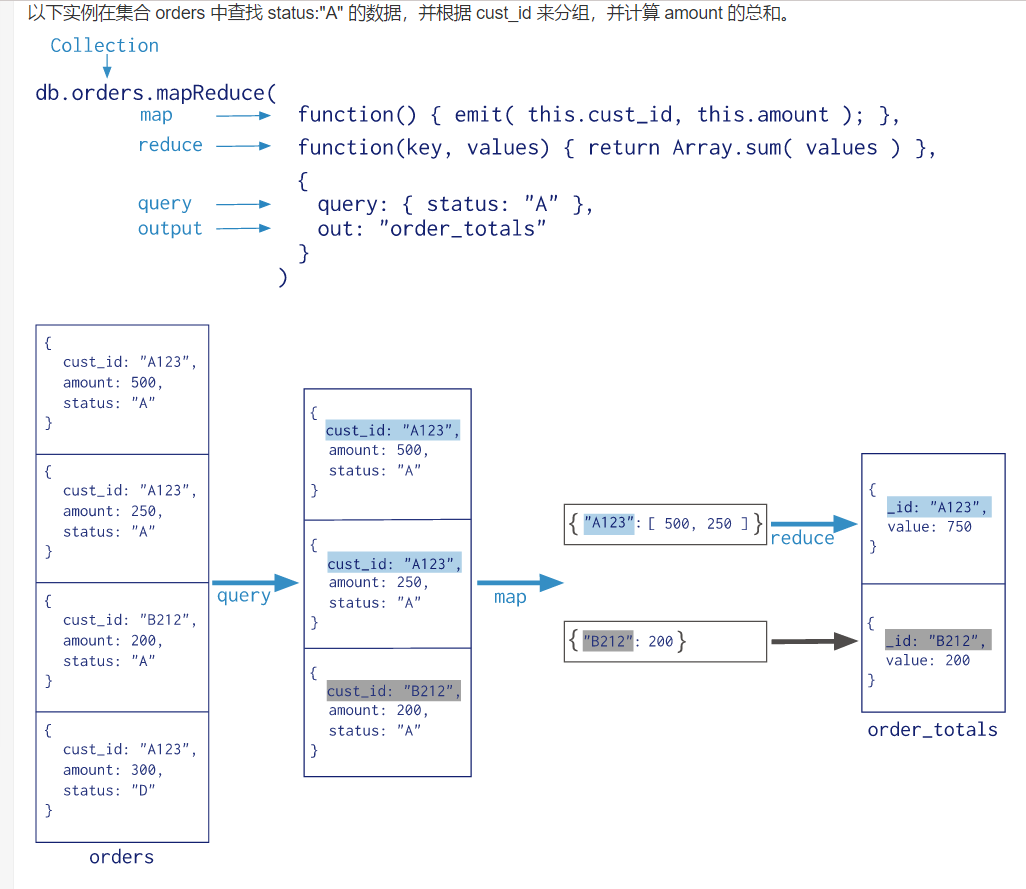
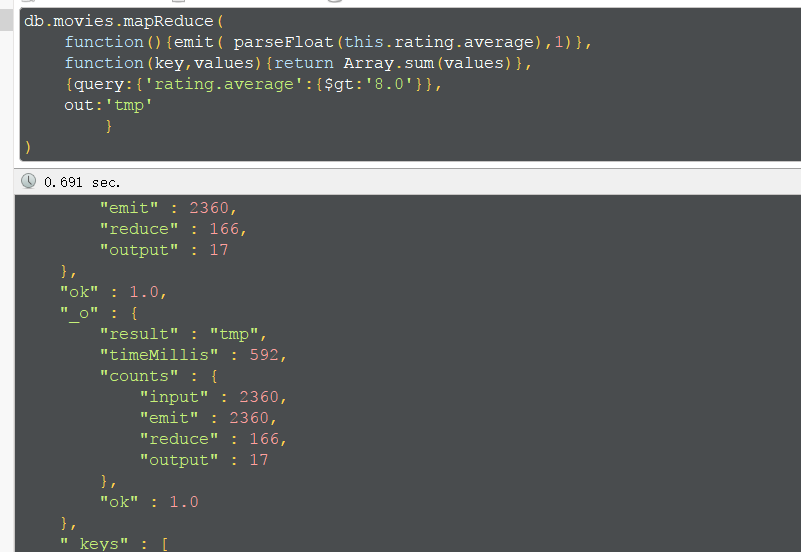
mapReduce
db.collection.mapReduce(
function() {emit(key,value);}, //map 函数
function(key,values) {return reduceFunction}, //reduce 函数
{
out: collection,
query: document,
sort: document,
limit: number
}
)使用 MapReduce 要实现两个函数 Map 函数和 Reduce 函数,Map 函数调用 emit(key, value), 遍历 collection 中所有的记录, 将 key 与 value 传递给 Reduce 函数进行处理。
Map 函数必须调用 emit(key, value) 返回键值对。
参数说明:
- map :映射函数 (生成键值对序列,作为 reduce 函数参数)。
- reduce 统计函数,reduce函数的任务就是将key-values变成key-value,也就是把values数组变成一个单一的值value。。
- out 统计结果存放集合 (不指定则使用临时集合,在客户端断开后自动删除)。
- query 一个筛选条件,只有满足条件的文档才会调用map函数。(query。limit,sort可以随意组合)
- sort 和limit结合的sort排序参数(也是在发往map函数前给文档排序),可以优化分组机制
- limit 发往map函数的文档数量的上限(要是没有limit,单独使用sort的用处不大)
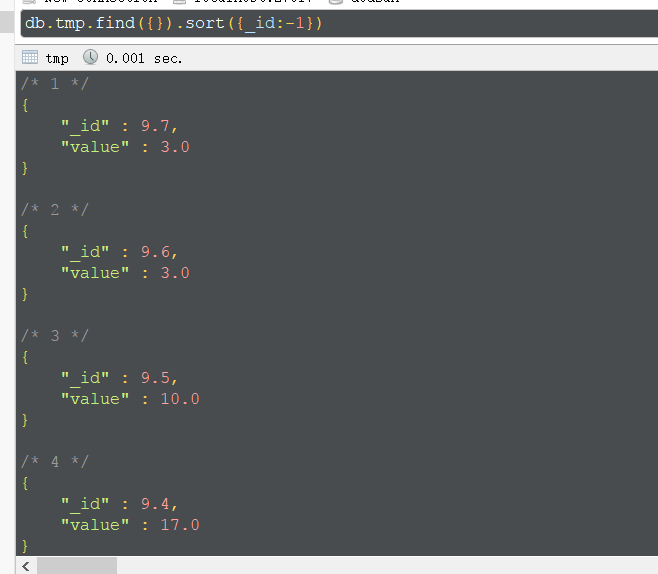
将8分以上的电影统计下,求出数目,保存到tmp表中,查看结果
这种方法比使用group慢太多了。。。
(1)MapReduce使用自定义JavaScript函数执行map和reduce操作,所以是基于js引擎,单线程执行,效率不高,比Aggregation复杂,适合用做后台统计等。
(2)MapReduce支持分片操作,可以进行拆分,分发到不同的机器上执行(多服务器并行做数据集合处理),然后再将不同的机器处理的结果汇集起 来,输出结果,。
(3)MapReduce能执行单一聚合的所有操作count、distinct、group,但group 在当数据量非常大的时候,处理能力就不太好,先筛选再分组,不支持 分片,对数据量有所限制,效率不高。

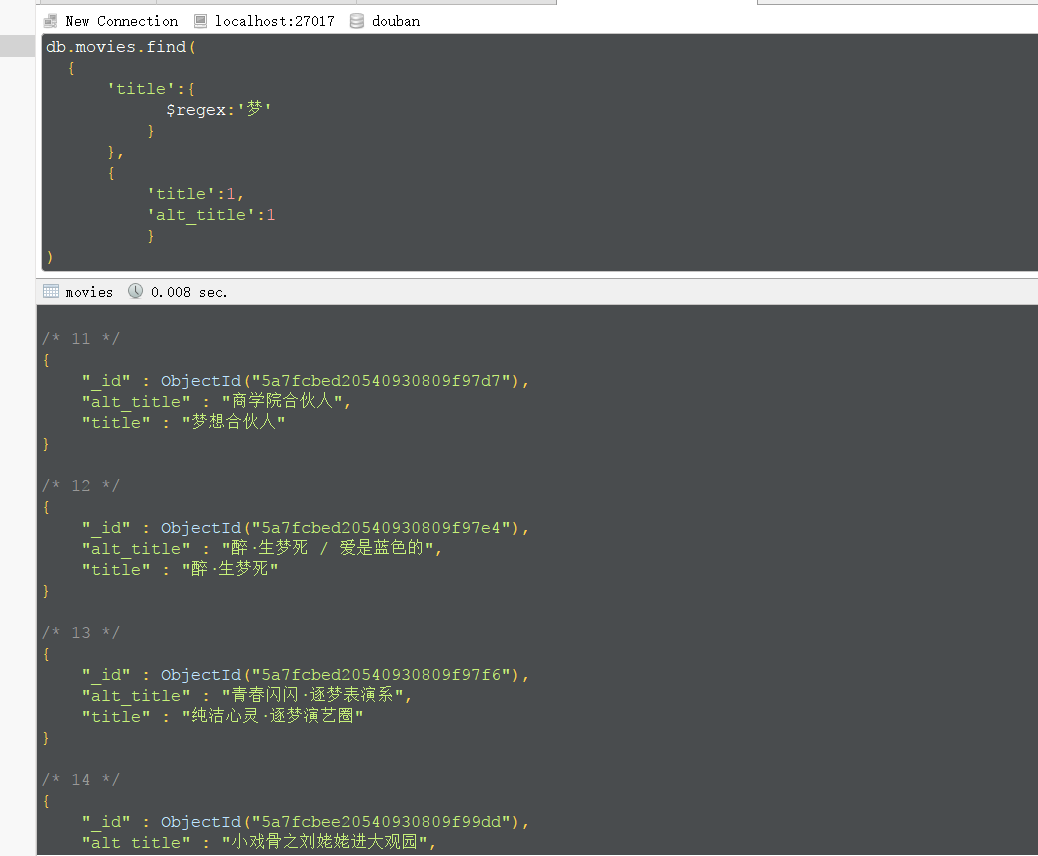
单关键字模糊查询,正则表达式使用
查询结果使用 forEach函数处理,更加灵活

使用聚合函数达到类似的效果,并且速度更快

修改字段类型,整个文档的修改花费时间较长,
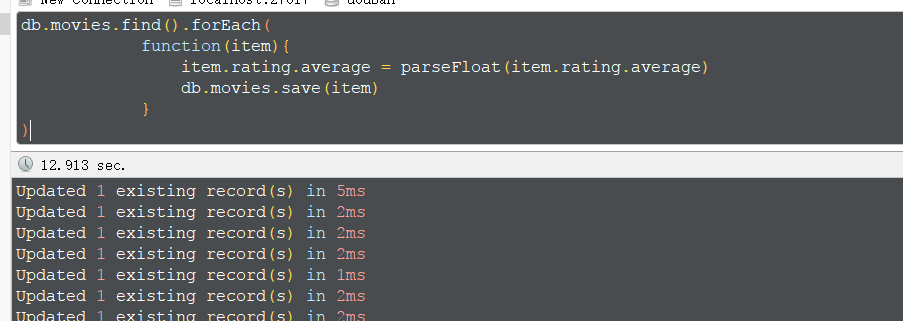
也可以使用 update,会稍微提高一点效率