我们准备利用17天时间,将 Python 基础的刻意练习分为如下任务:
Task01:变量、运算符与数据类型(1day)
Task02:条件与循环(1day)
Task03:列表与元组(2day)
Task04:字符串与序列(1day)
Task05:函数与Lambda表达式(2day)
Task06:字典与集合(1day)
Task07:文件与文件系统(2day)
Task08:异常处理(1day)
Task09:else 与 with 语句(1day)
Task10:类与对象(2day)
Task11:魔法方法(2day)
Task12:模块(1day)
变量、运算符与数据类型
单双引号:
- 没有什么区别,都是将文本展示出来
- 文本中有双引号,因此用单引号
# 双引号中有单引号
print("Let's go!")
# 单引号中有双引号
print('"sss"')
# 既有单引号,又有双引号的句子,使用转义字符
print("\"sss\",I love \'China\'!")
小写字母r 代表原始字符串:
print("D:\three\two\one\now")
print("D:\\three\\two\\one\\now")
print(r"D:\three\two\one\now")
输出
D: hree wo\one
ow
D:\three\two\one\now
D:\three\two\one\now
长字符串
三个单引号,或者三个双引号即可
print('''
面朝大海春暖花开
''')
字符串相加和数字相加
print(123+123)
print('123'+'123')
print("爱你"*3000)
结果
246
123123
** 代表乘方
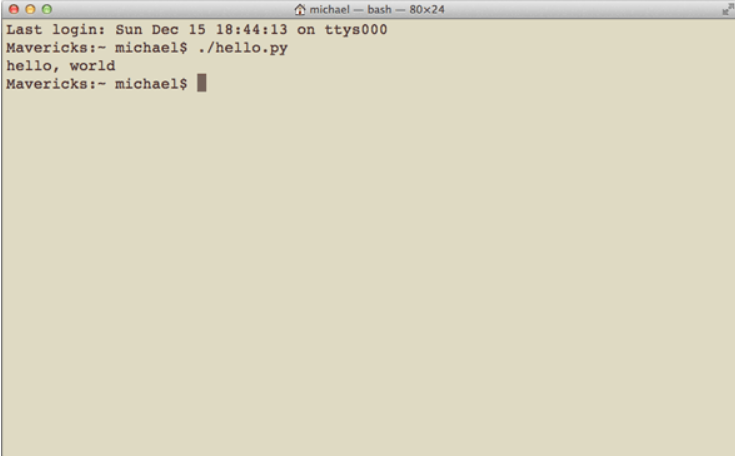
直接运行py文件
有同学问,能不能像.exe文件那样直接运行.py文件呢?在Windows上是不行的,但是,在Mac和Linux上是可以的,方法是在.py文件的第一行加上一个特殊的注释:
#!/usr/bin/env python3
print(‘hello, world’)
然后,通过命令给hello.py以执行权限:
$ chmod a+x hello.py
就可以直接运行hello.py了,比如在Mac下运行:
小结
用文本编辑器写Python程序,然后保存为后缀为.py的文件,就可以用Python直接运行这个程序了。
Python的交互模式和直接运行.py文件有什么区别呢?
直接输入python进入交互模式,相当于启动了Python解释器,但是等待你一行一行地输入源代码,每输入一行就执行一行。
直接运行.py文件相当于启动了Python解释器,然后一次性把.py文件的源代码给执行了,你是没有机会以交互的方式输入源代码的。
用Python开发程序,完全可以一边在文本编辑器里写代码,一边开一个交互式命令窗口,在写代码的过程中,把部分代码粘到命令行去验证,事半功倍!前提是得有个27’的超大显示器!
输出和输入
1. 输出
print('hello, world')
print()函数也可以接受多个字符串,用逗号“,”隔开,就可以连成一串输出:
>>> print('The quick brown fox', 'jumps over', 'the lazy dog')
The quick brown fox jumps over the lazy dog

print()也可以打印整数,或者计算结果:
>>> print(300)
300
>>> print(100 + 200)
300
2.输入
现在,你已经可以用print()输出你想要的结果了。但是,如果要让用户从电脑输入一些字符怎么办?Python提供了一个input(),可以让用户输入字符串,并存放到一个变量里。比如输入用户的名字:
>>> name = input()
Michael
当你输入name = input()并按下回车后,Python交互式命令行就在等待你的输入了。这时,你可以输入任意字符,然后按回车后完成输入。
输入完成后,不会有任何提示,Python交互式命令行又回到>>>状态了。那我们刚才输入的内容到哪去了?答案是存放到name变量里了。可以直接输入name查看变量内容:
>>> name
'Michael'
也可以这样
>>> name = input('请输入您的名字')
Michael
name = input('please enter your name: ')
print('hello,', name)
C:\Workspace> python hello.py
please enter your name: Michael
hello, Michael
print('1024 * 768 =',1024*768)
缩进
以#开头的语句是注释,注释是给人看的,可以是任意内容,解释器会忽略掉注释。其他每一行都是一个语句,当语句以冒号:结尾时,缩进的语句视为代码块。
缩进有利有弊。好处是强迫你写出格式化的代码,但没有规定缩进是几个空格还是Tab。按照约定俗成的管理,应该始终坚持使用4个空格的缩进。
缩进的另一个好处是强迫你写出缩进较少的代码,你会倾向于把一段很长的代码拆分成若干函数,从而得到缩进较少的代码。
缩进的坏处就是“复制-粘贴”功能失效了,这是最坑爹的地方。当你重构代码时,粘贴过去的代码必须重新检查缩进是否正确。此外,IDE很难像格式化Java代码那样格式化Python代码。
最后,请务必注意,Python程序是大小写敏感的,如果写错了大小写,程序会报错。
Python使用缩进来组织代码块,请务必遵守约定俗成的习惯,坚持使用4个空格的缩进。
在文本编辑器中,需要设置把Tab自动转换为4个空格,确保不混用Tab和空格。
数据类型和变量
1.数据类型
计算机顾名思义就是可以做数学计算的机器,因此,计算机程序理所当然地可以处理各种数值。但是,计算机能处理的远不止数值,还可以处理文本、图形、音频、视频、网页等各种各样的数据,不同的数据,需要定义不同的数据类型。在Python中,能够直接处理的数据类型有以下几种:
-
整数
Python可以处理任意大小的整数,当然包括负整数,在程序中的表示方法和数学上的写法一模一样,例如:1,100,-8080,0,等等。
计算机由于使用二进制,所以,有时候用十六进制表示整数比较方便,十六进制用0x前缀和0-9,a-f表示,例如:0xff00,0xa5b4c3d2,等等。 -
浮点数
浮点数也就是小数,之所以称为浮点数,是因为按照科学记数法表示时,一个浮点数的小数点位置是可变的,比如,1.23x109和12.3x108是完全相等的。浮点数可以用数学写法,如1.23,3.14,-9.01,等等。但是对于很大或很小的浮点数,就必须用科学计数法表示,把10用e替代,1.23x109就是1.23e9,或者12.3e8,0.000012可以写成1.2e-5,等等。
整数和浮点数在计算机内部存储的方式是不同的,整数运算永远是精确的(除法难道也是精确的?是的!),而浮点数运算则可能会有四舍五入的误差。 -
字符串
字符串是以单引号’或双引号"括起来的任意文本,比如’abc’,“xyz"等等。请注意,’'或”“本身只是一种表示方式,不是字符串的一部分,因此,字符串’abc’只有a,b,c这3个字符。如果’本身也是一个字符,那就可以用”"括起来,比如"I’m OK"包含的字符是I,’,m,空格,O,K这6个字符。
如果字符串内部既包含’又包含"怎么办?可以用转义字符\来标识,比如:
'I\'m \"OK\"!'
表示的字符串内容是:
I'm "OK"!
转义字符\可以转义很多字符,比如\n表示换行,\t表示制表符,字符\本身也要转义,所以\表示的字符就是\,可以在Python的交互式命令行用print()打印字符串看看:
>>> print('I\'m ok.')
I'm ok.
>>> print('I\'m learning\nPython.')
I'm learning
Python.
>>> print('\\\n\\')
\
\
如果字符串里面有很多字符都需要转义,就需要加很多\,为了简化,Python还允许用r’‘表示’'内部的字符串默认不转义,可以自己试试:
>>> print('\\\t\\')
\ \
>>> print(r'\\\t\\')
\\\t\\
如果字符串内部有很多换行,用\n写在一行里不好阅读,为了简化,Python允许用’’’…’’'的格式表示多行内容,可以自己试试:
>>> print('''line1
... line2
... line3''')
line1
line2
line3
上面是在交互式命令行内输入,注意在输入多行内容时,提示符由>>>变为…,提示你可以接着上一行输入,注意…是提示符,不是代码的一部分:
- 布尔值
布尔值和布尔代数的表示完全一致,一个布尔值只有True、False两种值,要么是True,要么是False,在Python中,可以直接用True、False表示布尔值(请注意大小写),也可以通过布尔运算计算出来:
>>> True
True
>>> False
False
>>> 3 > 2
True
>>> 3 > 5
False
布尔值可以用and、or和not运算。
and运算是与运算,只有所有都为True,and运算结果才是True:
>>> True and True
True
>>> True and False
False
>>> False and False
False
>>> 5 > 3 and 3 > 1
True
or运算是或运算,只要其中有一个为True,or运算结果就是True:
>>> True or True
True
>>> True or False
True
>>> False or False
False
>>> 5 > 3 or 1 > 3
True
not运算是非运算,它是一个单目运算符,把True变成False,False变成True:
>>> not True
False
>>> not False
True
>>> not 1 > 2
True
布尔值经常用在条件判断中,比如:
if age >= 18:
print('adult')
else:
print('teenager')
-
空值
-
空值是Python里一个特殊的值,用None表示。None不能理解为0,因为0是有意义的,而None是一个特殊的空值。
此外,Python还提供了列表、字典等多种数据类型,还允许创建自定义数据类型,我们后面会继续讲到。 -
变量
变量的概念基本上和初中代数的方程变量是一致的,只是在计算机程序中,变量不仅可以是数字,还可以是任意数据类型。
变量在程序中就是用一个变量名表示了,变量名必须是大小写英文、数字和_的组合,且不能用数字开头,比如:
a = 1
变量a是一个整数。
t_007 = 'T007'
在Python中,等号=是赋值语句,可以把任意数据类型赋值给变量,同一个变量可以反复赋值,而且可以是不同类型的变量,例如:
a = 123 # a是整数
print(a)
a = 'ABC' # a变为字符串
print(a)
这种变量本身类型不固定的语言称之为动态语言,与之对应的是静态语言。静态语言在定义变量时必须指定变量类型,如果赋值的时候类型不匹配,就会报错。例如Java是静态语言,赋值语句如下(// 表示注释):
int a = 123; // a是整数类型变量
a = "ABC"; // 错误:不能把字符串赋给整型变量
和静态语言相比,动态语言更灵活,就是这个原因。
请不要把赋值语句的等号等同于数学的等号。比如下面的代码:
x = 10
x = x + 2
如果从数学上理解x = x + 2那无论如何是不成立的,在程序中,赋值语句先计算右侧的表达式x + 2,得到结果12,再赋给变量x。由于x之前的值是10,重新赋值后,x的值变成12。
最后,理解变量在计算机内存中的表示也非常重要。当我们写:
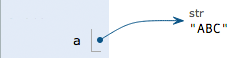
a = 'ABC'
时,Python解释器干了两件事情:
在内存中创建了一个’ABC’的字符串;
在内存中创建了一个名为a的变量,并把它指向’ABC’。
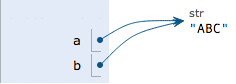
也可以把一个变量a赋值给另一个变量b,这个操作实际上是把变量b指向变量a所指向的数据,例如下面的代码:
a = 'ABC'
b = a
a = 'XYZ'
print(b)
最后一行打印出变量b的内容到底是’ABC’呢还是’XYZ’?如果从数学意义上理解,就会错误地得出b和a相同,也应该是’XYZ’,但实际上b的值是’ABC’,让我们一行一行地执行代码,就可以看到到底发生了什么事:
执行a = ‘ABC’,解释器创建了字符串’ABC’和变量a,并把a指向’ABC’:
执行b = a,解释器创建了变量b,并把b指向a指向的字符串’ABC’:
执行a = ‘XYZ’,解释器创建了字符串’XYZ’,并把a的指向改为’XYZ’,但b并没有更改:
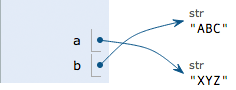
所以,最后打印变量b的结果自然是’ABC’了。
常量
所谓常量就是不能变的变量,比如常用的数学常数π就是一个常量。在Python中,通常用全部大写的变量名表示常量:
PI = 3.14159265359
但事实上PI仍然是一个变量,Python根本没有任何机制保证PI不会被改变,所以,用全部大写的变量名表示常量只是一个习惯上的用法,如果你一定要改变变量PI的值,也没人能拦住你。
最后解释一下整数的除法为什么也是精确的。在Python中,有两种除法,一种除法是/:
>>> 10 / 3
3.3333333333333335
/除法计算结果是浮点数,即使是两个整数恰好整除,结果也是浮点数:
>>> 9 / 3
3.0
还有一种除法是//,称为地板除,两个整数的除法仍然是整数:
>>> 10 // 3
3
你没有看错,整数的地板除//永远是整数,即使除不尽。要做精确的除法,使用/就可以。
因为//除法只取结果的整数部分,所以Python还提供一个余数运算,可以得到两个整数相除的余数:
>>> 10 % 3
1
无论整数做//除法还是取余数,结果永远是整数,所以,整数运算结果永远是精确的。
小结
Python支持多种数据类型,在计算机内部,可以把任何数据都看成一个“对象”,而变量就是在程序中用来指向这些数据对象的,对变量赋值就是把数据和变量给关联起来。
对变量赋值x = y是把变量x指向真正的对象,该对象是变量y所指向的。随后对变量y的赋值不影响变量x的指向。
注意:Python的整数没有大小限制,而某些语言的整数根据其存储长度是有大小限制的,例如Java对32位整数的范围限制在-2147483648-2147483647。
Python的浮点数也没有大小限制,但是超出一定范围就直接表示为inf(无限大)。
字符编码
我们已经讲过了,字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题。
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295。
由于计算机是美国人发明的,因此,最早只有127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
现在,捋一捋ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000,注意字符’0’和整数0是不同的;
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
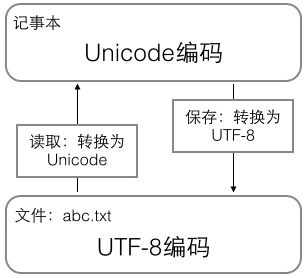
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
所以你看到很多网页的源码上会有类似的信息,表示该网页正是用的UTF-8编码。
Python的字符串
搞清楚了令人头疼的字符编码问题后,我们再来研究Python的字符串。
在最新的Python 3版本中,字符串是以Unicode编码的,也就是说,Python的字符串支持多语言,例如:
>>> print('包含中文的str')
包含中文的str
对于单个字符的编码,Python提供了ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符:
>>> ord('A')
65
>>> ord('中')
20013
>>> chr(66)
'B'
>>> chr(25991)
'文'
如果知道字符的整数编码,还可以用十六进制这么写str:
>>> '\u4e2d\u6587'
'中文'
两种写法完全是等价的。
由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
Python对bytes类型的数据用带b前缀的单引号或双引号表示:
x = b'ABC'
要注意区分’ABC’和b’ABC’,前者是str,后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节。
以Unicode表示的str通过encode()方法可以编码为指定的bytes,例如:
>>> 'ABC'.encode('ascii')
b'ABC'
>>> '中文'.encode('utf-8')
b'\xe4\xb8\xad\xe6\x96\x87'
>>> '中文'.encode('ascii')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
纯英文的str可以用ASCII编码为bytes,内容是一样的,含有中文的str可以用UTF-8编码为bytes。含有中文的str无法用ASCII编码,因为中文编码的范围超过了ASCII编码的范围,Python会报错。
在bytes中,无法显示为ASCII字符的字节,用\x##显示。
反过来,如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:
>>> b'ABC'.decode('ascii')
'ABC'
>>> b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
'中文'
如果bytes中包含无法解码的字节,decode()方法会报错:
>>> b'\xe4\xb8\xad\xff'.decode('utf-8')
Traceback (most recent call last):
...
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 3: invalid start byte
如果bytes中只有一小部分无效的字节,可以传入errors='ignore’忽略错误的字节:
>>> b'\xe4\xb8\xad\xff'.decode('utf-8', errors='ignore')
'中'
要计算str包含多少个字符,可以用len()函数:
>>> len('ABC')
3
>>> len('中文')
2
len()函数计算的是str的字符数,如果换成bytes,len()函数就计算字节数:
>>> len(b'ABC')
3
>>> len(b'\xe4\xb8\xad\xe6\x96\x87')
6
>>> len('中文'.encode('utf-8'))
6
可见,1个中文字符经过UTF-8编码后通常会占用3个字节,而1个英文字符只占用1个字节。
在操作字符串时,我们经常遇到str和bytes的互相转换。为了避免乱码问题,应当始终坚持使用UTF-8编码对str和bytes进行转换。
由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
申明了UTF-8编码并不意味着你的.py文件就是UTF-8编码的,必须并且要确保文本编辑器正在使用UTF-8 without BOM编码:
格式化
>>> 'Hello, %s' % 'world'
'Hello, world'
>>> 'Hi, %s, you have $%d.' % ('Michael', 1000000)
'Hi, Michael, you have $1000000.'
你可能猜到了,%运算符就是用来格式化字符串的。在字符串内部,%s表示用字符串替换,%d表示用整数替换,有几个%?占位符,后面就跟几个变量或者值,顺序要对应好。如果只有一个%?,括号可以省略。
常见的占位符有:
| 占位符 | 替换内容 |
|---|---|
| %d | 整数 |
| %f | 浮点数 |
| %s | 字符串 |
| %x | 十六进制整数 |
如果你不太确定应该用什么,%s永远起作用,它会把任何数据类型转换为字符串:
>>> 'Age: %s. Gender: %s' % (25, True)
'Age: 25. Gender: True'
字符串和编码
阅读: 101919815
字符编码
我们已经讲过了,字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题。
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295。
由于计算机是美国人发明的,因此,最早只有127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
char-encoding-problem
因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
现在,捋一捋ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000,注意字符’0’和整数0是不同的;
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
字符 ASCII Unicode UTF-8
A 01000001 00000000 01000001 01000001
中 x 01001110 00101101 11100100 10111000 10101101
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
rw-file-utf-8
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
web-utf-8
所以你看到很多网页的源码上会有类似的信息,表示该网页正是用的UTF-8编码。
Python的字符串
搞清楚了令人头疼的字符编码问题后,我们再来研究Python的字符串。
在最新的Python 3版本中,字符串是以Unicode编码的,也就是说,Python的字符串支持多语言,例如:
>>> print('包含中文的str')
包含中文的str
对于单个字符的编码,Python提供了ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符:
>>> ord('A')
65
>>> ord('中')
20013
>>> chr(66)
'B'
>>> chr(25991)
'文'
如果知道字符的整数编码,还可以用十六进制这么写str:
>>> '\u4e2d\u6587'
'中文'
两种写法完全是等价的。
由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
Python对bytes类型的数据用带b前缀的单引号或双引号表示:
x = b'ABC'
要注意区分'ABC'和b'ABC',前者是str,后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节。
以Unicode表示的str通过encode()方法可以编码为指定的bytes,例如:
>>> 'ABC'.encode('ascii')
b'ABC'
>>> '中文'.encode('utf-8')
b'\xe4\xb8\xad\xe6\x96\x87'
>>> '中文'.encode('ascii')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
纯英文的str可以用ASCII编码为bytes,内容是一样的,含有中文的str可以用UTF-8编码为bytes。含有中文的str无法用ASCII编码,因为中文编码的范围超过了ASCII编码的范围,Python会报错。
在bytes中,无法显示为ASCII字符的字节,用\x##显示。
反过来,如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:
>>> b'ABC'.decode('ascii')
'ABC'
>>> b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
'中文'
如果bytes中包含无法解码的字节,decode()方法会报错:
>>> b'\xe4\xb8\xad\xff'.decode('utf-8')
Traceback (most recent call last):
...
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 3: invalid start byte
如果bytes中只有一小部分无效的字节,可以传入errors='ignore'忽略错误的字节:
>>> b'\xe4\xb8\xad\xff'.decode('utf-8', errors='ignore')
'中'
要计算str包含多少个字符,可以用len()函数:
>>> len('ABC')
3
>>> len('中文')
2
len()函数计算的是str的字符数,如果换成bytes,len()函数就计算字节数:
>>> len(b'ABC')
3
>>> len(b'\xe4\xb8\xad\xe6\x96\x87')
6
>>> len('中文'.encode('utf-8'))
6
可见,1个中文字符经过UTF-8编码后通常会占用3个字节,而1个英文字符只占用1个字节。
在操作字符串时,我们经常遇到str和bytes的互相转换。为了避免乱码问题,应当始终坚持使用UTF-8编码对str和bytes进行转换。
由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
申明了UTF-8编码并不意味着你的.py文件就是UTF-8编码的,必须并且要确保文本编辑器正在使用UTF-8 without BOM编码:
set-encoding-in-notepad++
如果.py文件本身使用UTF-8编码,并且也申明了# -- coding: utf-8 --,打开命令提示符测试就可以正常显示中文:
py-chinese-test-in-cmd
格式化
最后一个常见的问题是如何输出格式化的字符串。我们经常会输出类似’亲爱的xxx你好!你xx月的话费是xx,余额是xx’之类的字符串,而xxx的内容都是根据变量变化的,所以,需要一种简便的格式化字符串的方式。
py-str-format
在Python中,采用的格式化方式和C语言是一致的,用%实现,举例如下:
>>> 'Hello, %s' % 'world'
'Hello, world'
>>> 'Hi, %s, you have $%d.' % ('Michael', 1000000)
'Hi, Michael, you have $1000000.'
你可能猜到了,%运算符就是用来格式化字符串的。在字符串内部,%s表示用字符串替换,%d表示用整数替换,有几个%?占位符,后面就跟几个变量或者值,顺序要对应好。如果只有一个%?,括号可以省略。
常见的占位符有:
占位符 替换内容
%d 整数
%f 浮点数
%s 字符串
%x 十六进制整数
其中,格式化整数和浮点数还可以指定是否补0和整数与小数的位数:
# -*- coding: utf-8 -*-
print('%2d-%02d' % (3, 1))
print('%.2f' % 3.1415926)
print('%.2f' % 3.1415926)
print('你好我是%s' % 'XX')
Run
3-01
3.14
3.14
你好我是XX
如果你不太确定应该用什么,%s永远起作用,它会把任何数据类型转换为字符串:
>>> 'Age: %s. Gender: %s' % (25, True)
'Age: 25. Gender: True'
有些时候,字符串里面的%是一个普通字符怎么办?这个时候就需要转义,用%%来表示一个%:
>>> 'growth rate: %d %%' % 7
'growth rate: 7 %'
format()
另一种格式化字符串的方法是使用字符串的format()方法,它会用传入的参数依次替换字符串内的占位符{0}、{1}……,不过这种方式写起来比%要麻烦得多:
>>> 'Hello, {0}, 成绩提升了 {1:.1f}%'.format('小明', 17.125)
'Hello, 小明, 成绩提升了 17.1%'
小结
Python 3的字符串使用Unicode,直接支持多语言。
当str和bytes互相转换时,需要指定编码。最常用的编码是UTF-8。Python当然也支持其他编码方式,比如把Unicode编码成GB2312:
>>> '中文'.encode('gb2312')
b'\xd6\xd0\xce\xc4'
但这种方式纯属自找麻烦,如果没有特殊业务要求,请牢记仅使用UTF-8编码。
格式化字符串的时候,可以用Python的交互式环境测试,方便快捷。
使用list和tuple
list
Python内置的一种数据类型是列表:list。list是一种有序的集合,可以随时添加和删除其中的元素。
比如,列出班里所有同学的名字,就可以用一个list表示:
>>> classmates = ['Michael', 'Bob', 'Tracy']
>>> classmates
['Michael', 'Bob', 'Tracy']
变量classmates就是一个list。用len()函数可以获得list元素的个数:
>>> len(classmates)
3
用索引来访问list中每一个位置的元素,记得索引是从0开始的:
>>> classmates[0]
'Michael'
>>> classmates[1]
'Bob'
>>> classmates[2]
'Tracy'
>>> classmates[3]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: list index out of range
当索引超出了范围时,Python会报一个IndexError错误,所以,要确保索引不要越界,记得最后一个元素的索引是len(classmates) - 1。
如果要取最后一个元素,除了计算索引位置外,还可以用-1做索引,直接获取最后一个元素:
>>> classmates[-1]
'Tracy'
以此类推,可以获取倒数第2个、倒数第3个:
>>> classmates[-2]
'Bob'
>>> classmates[-3]
'Michael'
>>> classmates[-4]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: list index out of range
当然,倒数第4个就越界了。
list是一个可变的有序表,所以,可以往list中追加元素到末尾:
>>> classmates.append('Adam')
>>> classmates
['Michael', 'Bob', 'Tracy', 'Adam']
也可以把元素插入到指定的位置,比如索引号为1的位置:
>>> classmates.insert(1, 'Jack')
>>> classmates
['Michael', 'Jack', 'Bob', 'Tracy', 'Adam']
要删除list末尾的元素,用pop()方法:
>>> classmates.pop()
'Adam'
>>> classmates
['Michael', 'Jack', 'Bob', 'Tracy']
要删除指定位置的元素,用pop(i)方法,其中i是索引位置:
>>> classmates.pop(1)
'Jack'
>>> classmates
['Michael', 'Bob', 'Tracy']
要把某个元素替换成别的元素,可以直接赋值给对应的索引位置:
>>> classmates[1] = 'Sarah'
>>> classmates
['Michael', 'Sarah', 'Tracy']
list里面的元素的数据类型也可以不同,比如:
>>> L = ['Apple', 123, True]
list元素也可以是另一个list,比如:
>>> s = ['python', 'java', ['asp', 'php'], 'scheme']
>>> len(s)
4
要注意s只有4个元素,其中s[2]又是一个list,如果拆开写就更容易理解了:
>>> p = ['asp', 'php']
>>> s = ['python', 'java', p, 'scheme']
要拿到’php’可以写p[1]或者s[2][1],因此s可以看成是一个二维数组,类似的还有三维、四维……数组,不过很少用到。
如果一个list中一个元素也没有,就是一个空的list,它的长度为0:
>>> L = []
>>> len(L)
0
tuple
另一种有序列表叫元组:tuple。tuple和list非常类似,但是tuple一旦初始化就不能修改,比如同样是列出同学的名字:
>>> classmates = ('Michael', 'Bob', 'Tracy')
现在,classmates这个tuple不能变了,它也没有append(),insert()这样的方法。其他获取元素的方法和list是一样的,你可以正常地使用classmates[0],classmates[-1],但不能赋值成另外的元素。
不可变的tuple有什么意义?因为tuple不可变,所以代码更安全。如果可能,能用tuple代替list就尽量用tuple。
tuple的陷阱:当你定义一个tuple时,在定义的时候,tuple的元素就必须被确定下来,比如:
>>> t = (1, 2)
>>> t
(1, 2)
如果要定义一个空的tuple,可以写成():
>>> t = ()
>>> t
()
但是,要定义一个只有1个元素的tuple,如果你这么定义:
>>> t = (1)
>>> t
1
定义的不是tuple,是1这个数!这是因为括号()既可以表示tuple,又可以表示数学公式中的小括号,这就产生了歧义,因此,Python规定,这种情况下,按小括号进行计算,计算结果自然是1。
所以,只有1个元素的tuple定义时必须加一个逗号,,来消除歧义:
>>> t = (1,)
>>> t
(1,)
Python在显示只有1个元素的tuple时,也会加一个逗号,,以免你误解成数学计算意义上的括号。
最后来看一个“可变的”tuple:
>>> t = ('a', 'b', ['A', 'B'])
>>> t[2][0] = 'X'
>>> t[2][1] = 'Y'
>>> t
('a', 'b', ['X', 'Y'])
这个tuple定义的时候有3个元素,分别是’a’,'b’和一个list。不是说tuple一旦定义后就不可变了吗?怎么后来又变了?
别急,我们先看看定义的时候tuple包含的3个元素:

当我们把list的元素’A’和’B’修改为’X’和’Y’后,tuple变为

表面上看,tuple的元素确实变了,但其实变的不是tuple的元素,而是list的元素。tuple一开始指向的list并没有改成别的list,所以,tuple所谓的“不变”是说,tuple的每个元素,指向永远不变。即指向’a’,就不能改成指向’b’,指向一个list,就不能改成指向其他对象,但指向的这个list本身是可变的!
理解了“指向不变”后,要创建一个内容也不变的tuple怎么做?那就必须保证tuple的每一个元素本身也不能变。
小结:
list和tuple是Python内置的有序集合,一个可变,一个不可变。根据需要来选择使用它们。