LINEST函数使用最小二乘法对已知数据进行最佳直线拟合,并返回描述此直线的数组。例如在上半年产品销售数量统计报表中,根据上半年各月的销售数量预算9月份的产品销售量,可以按如下方法设置公式。



LINEST 函数说明:
LINEST 函数可通过使用最小二乘法计算与现有数据最佳拟合的直线,来计算某直线的统计值,然后返回描述此直线的数组。也可以将 LINEST 与其他函数结合使用来计算未知参数中其他类型的线性模型的统计值,包括多项式、对数、指数和幂级数。因为此函数返回数值数组,所以必须以数组公式的形式输入。请按照本文中的示例使用此函数。
直线的公式为:
y = mx + b
- 或 -
y = m1x1 + m2x2 + ... + b
如果有多个区域的 x 值,其中因变量 y 值是自变量 x 值的函数。m 值是与每个 x 值相对应的系数,b 为常量。注意,y、x 和 m 可以是向量。LINEST 函数返回的数组为 {mn,mn-1,...,m1,b}。LINEST 函数还可返回附加回归统计值。
语法
LINEST(known_y's, [known_x's], [const], [stats])
语法
- Known_y's 必需。关系表达式 y = mx + b 中已知的 y 值集合。
- 如果 known_y's 对应的单元格区域在单独一列中,则 known_x's 的每一列被视为一个独立的变量。
- 如果 known_y's 对应的单元格区域在单独一行中,则 known_x's 的每一行被视为一个独立的变量。
- Known_x's 可选。关系表达式 y = mx + b 中已知的 x 值集合。
- known_x's 对应的单元格区域可以包含一组或多组变量。如果仅使用一个变量,那么只要 known_y's 和 known_x's 具有相同的维数,则它们可以是任何形状的区域。如果使用多个变量,则 known_y's 必须为向量(即必须为一行或一列)。
- 如果省略 known_x's,则假设该数组为 {1,2,3,...}, 其大小与 known_y's 相同。
- const 可选。一个逻辑值,用于指定是否将常量 b 强制设为 0。
- 如果 const 为 TRUE 或被省略,b 将按通常方式计算。
- 如果 const 为 FALSE,b 将被设为 0,并同时调整 m 值使 y = mx。
- stats 可选。一个逻辑值,用于指定是否返回附加回归统计值。
- 如果 stats 为 TRUE,则 LINEST 函数返回附加回归统计值,这时返回的数组为 {mn,mn-1,...,m1,b;sen,sen-1,...,se1,seb;r2,sey;F,df;ssreg,ssresid}。
- 如果 stats 为 FALSE 或被省略,LINEST 函数只返回系数 m 和常量 b。
附加回归统计值如下:
统计值 说明 se1,se2,...,sen 系数 m1,m2,...,mn 的标准误差值。 seb 常量 b 的标准误差值(当 const 为 FALSE 时,seb = #N/A)。 r2 判定系数。y 的估计值与实际值之比,范围在 0 到 1 之间。如果为 1,则样本有很好的相关性,y 的估计值与实际值之间没有差别。相反,如果判定系数为 0,则回归公式不能用来预测 y 值。有关如何计算 r2 的信息,请参阅本主题下文中的“说明”。 sey Y 估计值的标准误差。 F F 统计或 F 观察值。使用 F 统计可以判断因变量和自变量之间是否偶尔发生过可观察到的关系。 df 自由度。用于在统计表上查找 F 临界值。将从表中查得的值与 LINEST 函数返回的 F 统计值进行比较可确定模型的置信区间。有关如何计算 df 的信息,请参阅本主题下文中的“说明”。示例 4 说明了 F 和 df 的用法。 ssreg 回归平方和。 ssresid 残差平方和。有关如何计算 ssreg 和 ssresid 的信息,请参阅本主题下文中的“说明”。 下面的图示显示了附加回归统计值返回的顺序。
-
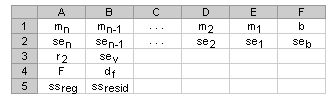
说明
- 可以使用斜率和 y 轴截距描述任何直线:
斜率 (m):
通常记为 m,如果需要计算斜率,则选取直线上的两点,(x1,y1) 和 (x2,y2);斜率等于 (y2 - y1)/(x2 - x1)。Y 轴截距 (b):
通常记为 b,直线的 y 轴的截距为直线通过 y 轴时与 y 轴交点的数值。直线的公式为 y = mx + b。如果知道了 m 和 b 的值,将 y 或 x 的值代入公式就可计算出直线上的任意一点。还可以使用 TREND 函数。
- 当只有一个自变量 x 时,可直接利用下面公式得到斜率和 y 轴截距值:
斜率:
=INDEX(LINEST(known_y's,known_x's),1)Y 轴截距:
=INDEX(LINEST(known_y's,known_x's),2) - 数据的离散程度决定了 LINEST 函数计算的直线的精确度。数据越接近线性,LINEST 模型就越精确。LINEST 函数使用最小二乘法来判定数据的最佳拟合。当只有一个自变量 x 时,m 和 b 是根据下面的公式计算出的:
-
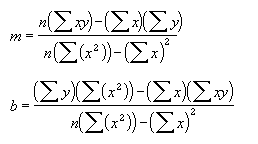
其中,x 和 y 是样本平均值;即,x = AVERAGE(known x's),y = AVERAGE(known_y's)。
- 直线和曲线拟合函数 LINEST 和 LOGEST 可用来计算与给定数据拟合程度最高的直线或指数曲线, 但需要判断两者中哪一个与数据拟合程度最高。可以用函数 TREND(known_y's,known_x's) 来计算直线,或用函数 GROWTH(known_y's, known_x's) 来计算指数曲线。这些不带 new_x's 参数的函数可在实际数据点上根据直线或曲线来返回 y 预测值的数组, 然后可以将预测值与实际值进行比较。可能需要用图表方式来直观地比较二者。
- 回归分析时,Excel 会计算每一点的 y 的估计值和实际值的平方差。这些平方差之和称为残差平方和 (ssresid)。然后 Excel 会计算总平方和 (sstotal)。当参数 const = TRUE 或被省略时,总平方和是 y 的实际值和平均值的平方差之和。当参数 const = FALSE 时,总平方和是 y 的实际值的平方和(不需要从每个 y 值中减去平均值)。回归平方和 (ssreg) 可通过公式 ssreg = sstotal - ssresid 计算出来。ssreg = sstotal - ssresid。残差平方和与总平方和的比值越小,判定系数 r2 的值就越大,r2 是用来判断从回归分析求得的公式是否足以说明变量之间关系的指示器。r2 = ssreg/sstotal。
- 在某些情况下,一个或多个 X 列可能没有出现在其他 X 列中的附加预测值(假设 Y's 和 X's 位于列中)。换句话说,删除一个或多个 X 列可能会得到同样精度的 y 预测值。在这种情况下,应从回归模型中省略这些多余的 X 列。这种现象被称为“共线”,因为任何多余的 X 列都可被表示为多个非多余 X 列的和。LINEST 函数会检查是否存在共线,并在识别出多余的 X 列之后从回归模型中删除所有这些列。由于包含 0 系数以及 0 se 数值,因此已删除的 X 列能在 LINEST 输出中被识别出来。如果一个或多个多余的列被删除,则将影响 df,原因是 df 取决于实际用于预测目的的 X 列的数量。有关计算 df 的详细信息,请参阅示例 4。如果由于删除多余的 X 列而更改了 df,则也会影响 sey 和 F 的值。实际上,出现共线的情况应该相对很少。但是,如果某些 X 列仅包含 0 和 1 数值作为实验中的对象是否属于特定组成员的指示器,则很可能引起共线。如果 const = TRUE 或被省略,则 LINEST 函数可有效地插入所有 1 数值的其他 X 列以便为截距建立模型。如果在一列中,1 对应于每个男性对象,0 对应于女性对象;而在另一列中,1 对应于每个女性对象,0 对应于男性对象,那么后一列就是多余的,因为其中的项可通过从所有 1 值的另一列(通过 LINEST 函数添加)中减去“男性指示器”列中的项来获得。
- 在没有 X 列因共线而被从模型中删除时,请用以下方法计算 df 的值:如果 known_x’s 有 k 列且 const = TRUE 或被省略,那么 df = n – k – 1。如果 const = FALSE,那么 df = n - k。在这两种情况下,每次由于共线而删除一个 X 列都会使 df 的值加 1。
- 对于返回结果为数组的公式,必须以数组公式的形式输入。
- 当输入一个数组常量(如 known_x's)作为参数时,请使用逗号分隔同一行中的各值,使用分号分隔各行。分隔符可能会因“控制面板”的“区域和语言选项”中区域设置的不同而有所不同。
- 注意,如果 y 的回归分析预测值超出了用来计算公式的 y 值的范围,它们可能是无效的。
- LINEST 函数中使用的下层算法与 SLOPE 和 INTERCEPT 函数中使用的下层算法不同。当数据未定且共线时,这些算法之间的差异会导致不同的结果。例如,如果参数 known_y's 的数据点为 0,参数 known_x's 的数据点为 1:
- LINEST 会返回值 0。LINEST 函数的算法用来返回共线数据的合理结果,在这种情况下至少可找到一个答案。
- SLOPE 和 INTERCEPT 会返回错误 #DIV/0! 。SLOPE 和 INTERCEPT 函数的算法只用来查找一个答案,在这种情况下可能有多个答案。
- 除了使用 LOGEST 计算其他回归分析类型的统计值外,还可以使用 LINEST 计算其他回归分析类型的范围,方法是将 x 和 y 变量的函数作为 LINEST 的 x 和 y 系列输入。例如,下面的公式:
=LINEST(yvalues, xvalues^COLUMN($A:$C))
将在您使用 y 值的单个列和 x 值的单个列计算下面的方程式的近似立方(多项式次数 3)值时运行:
y = m1*x + m2*x^2 + m3*x^3 + b
可以调整此公式以计算其他类型的回归,但是在某些情况下,需要调整输出值和其他统计值。
- LINEST 函数返回的 F 检验值与 FTEST 函数返回的 F 检验值不同。LINEST 返回 F 统计值,而 FTEST 返回概率。